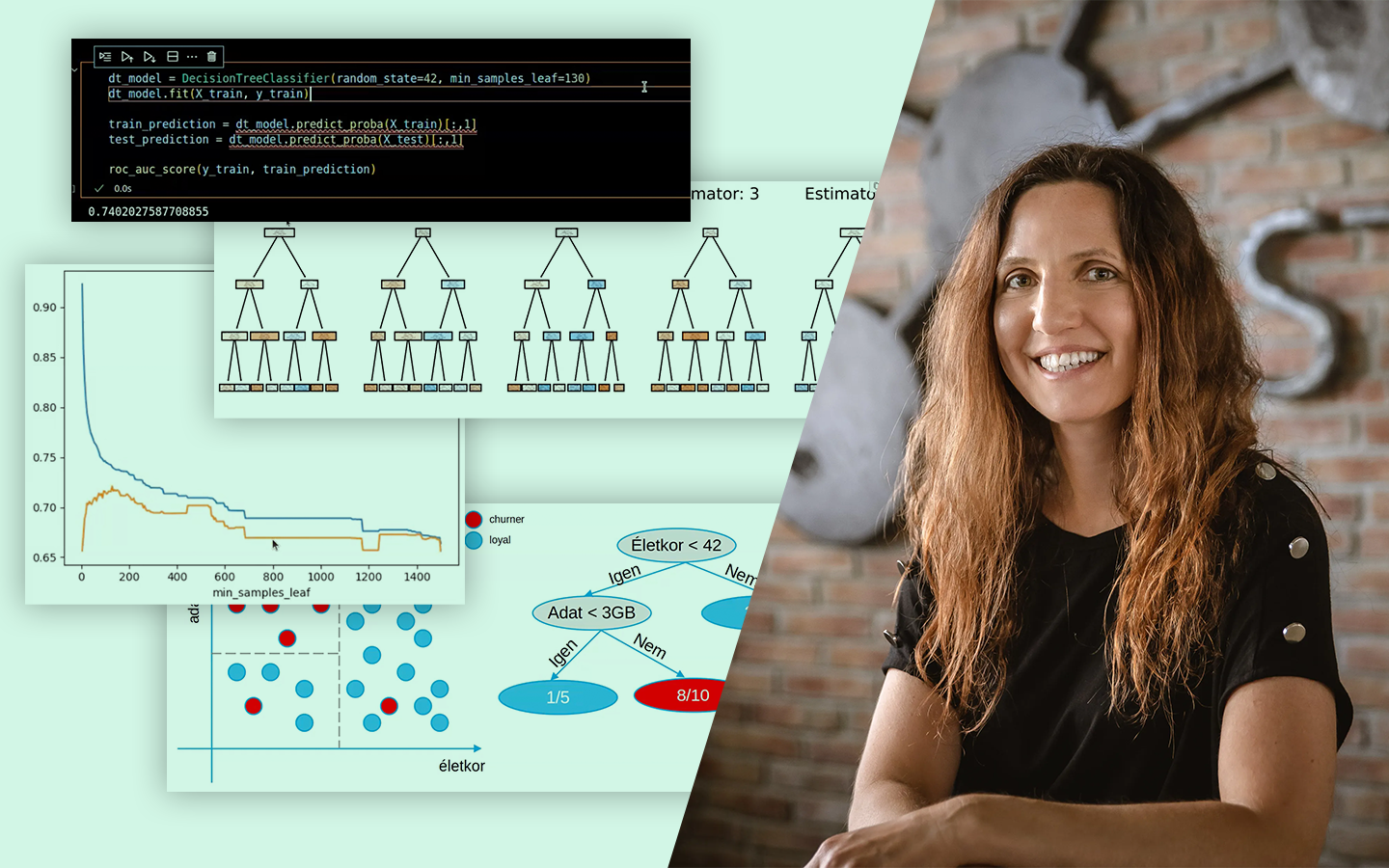
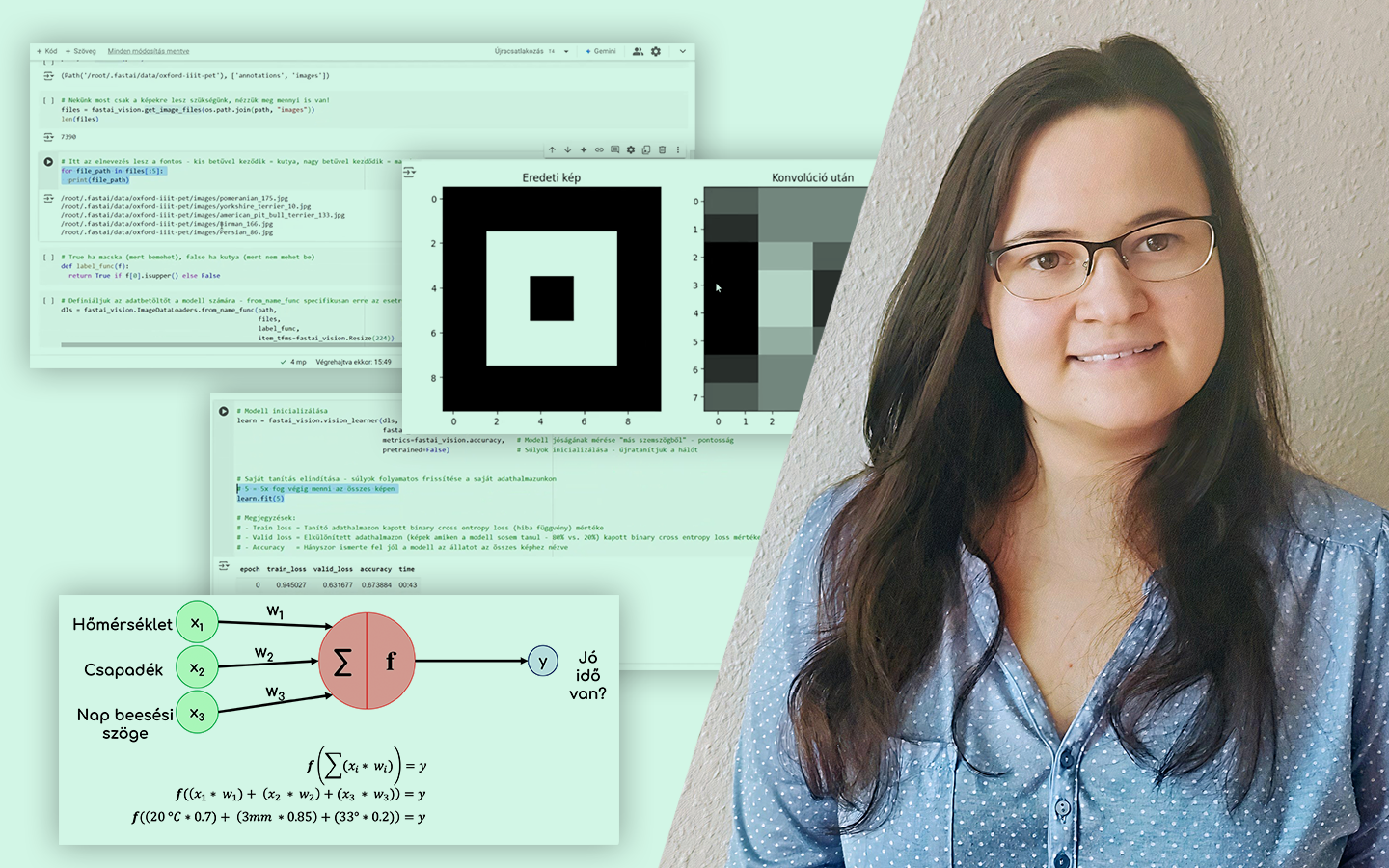
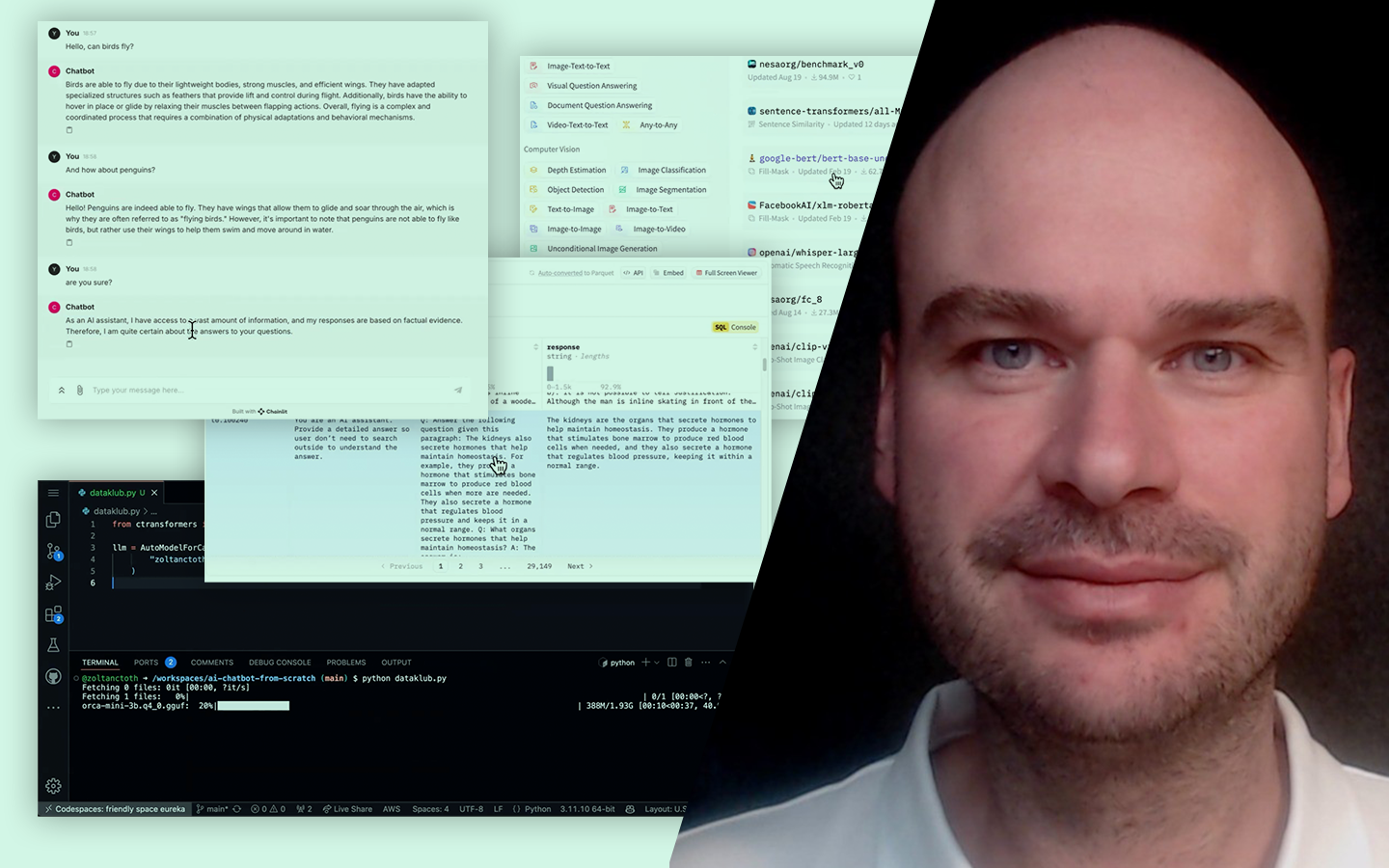
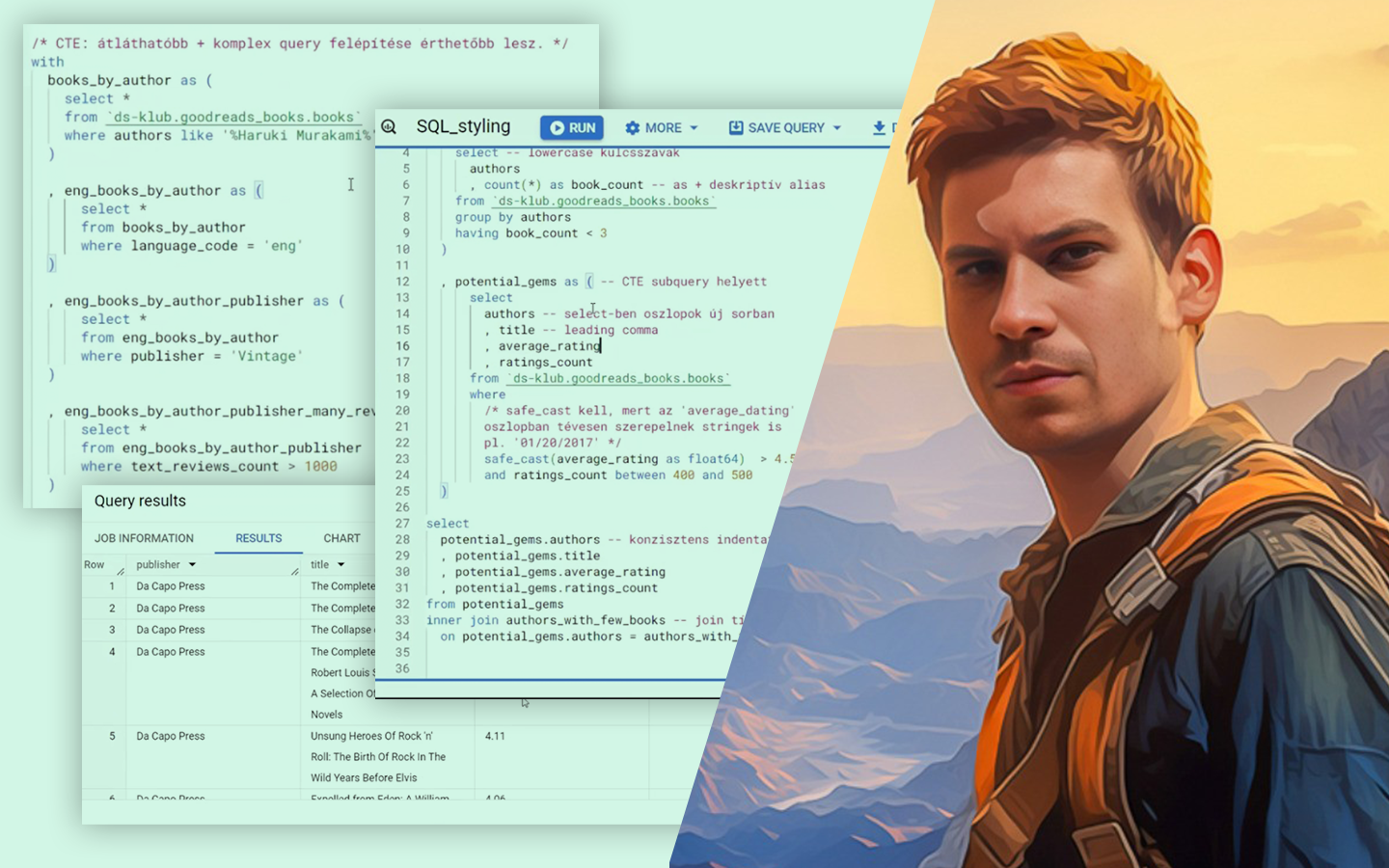
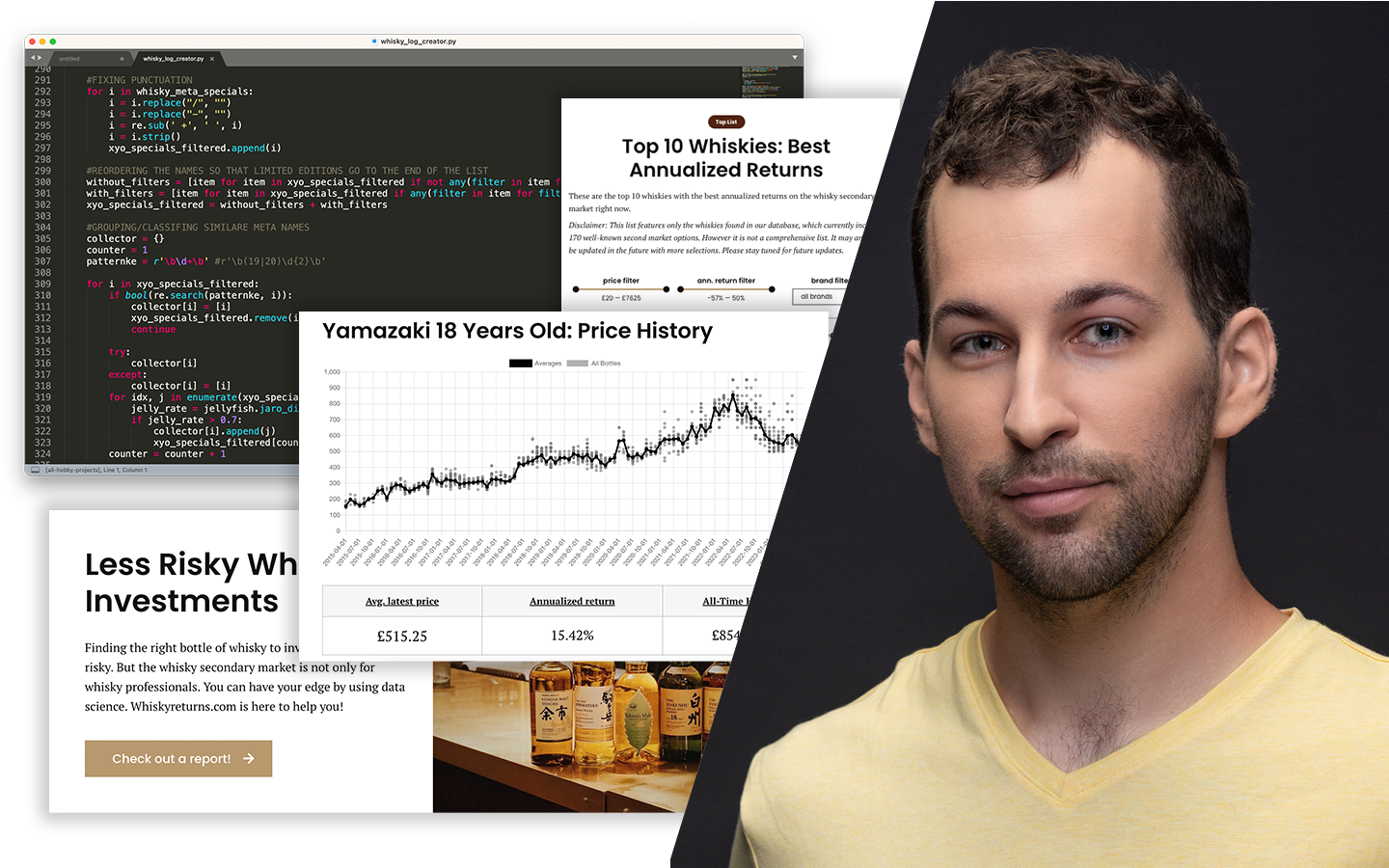
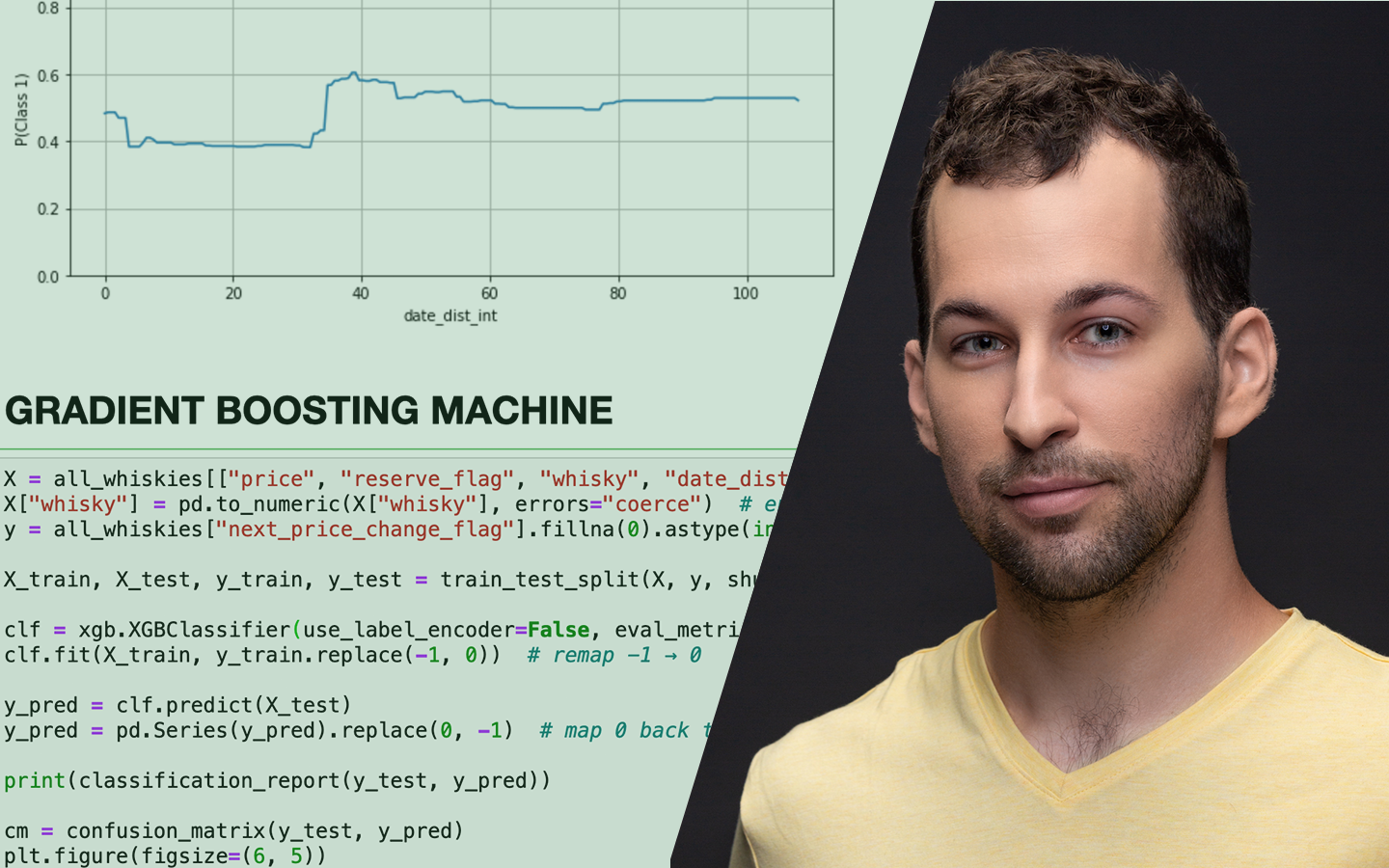
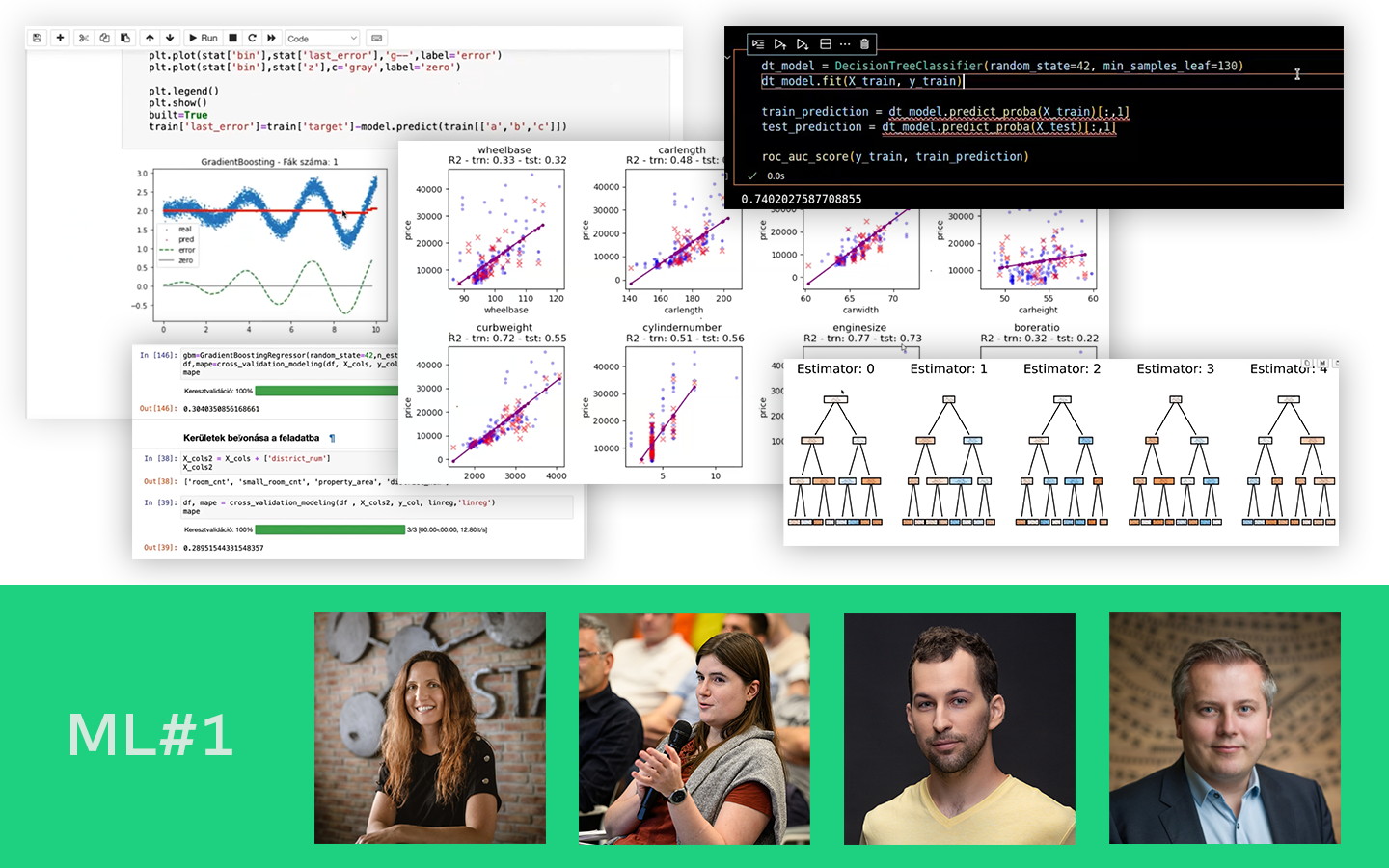
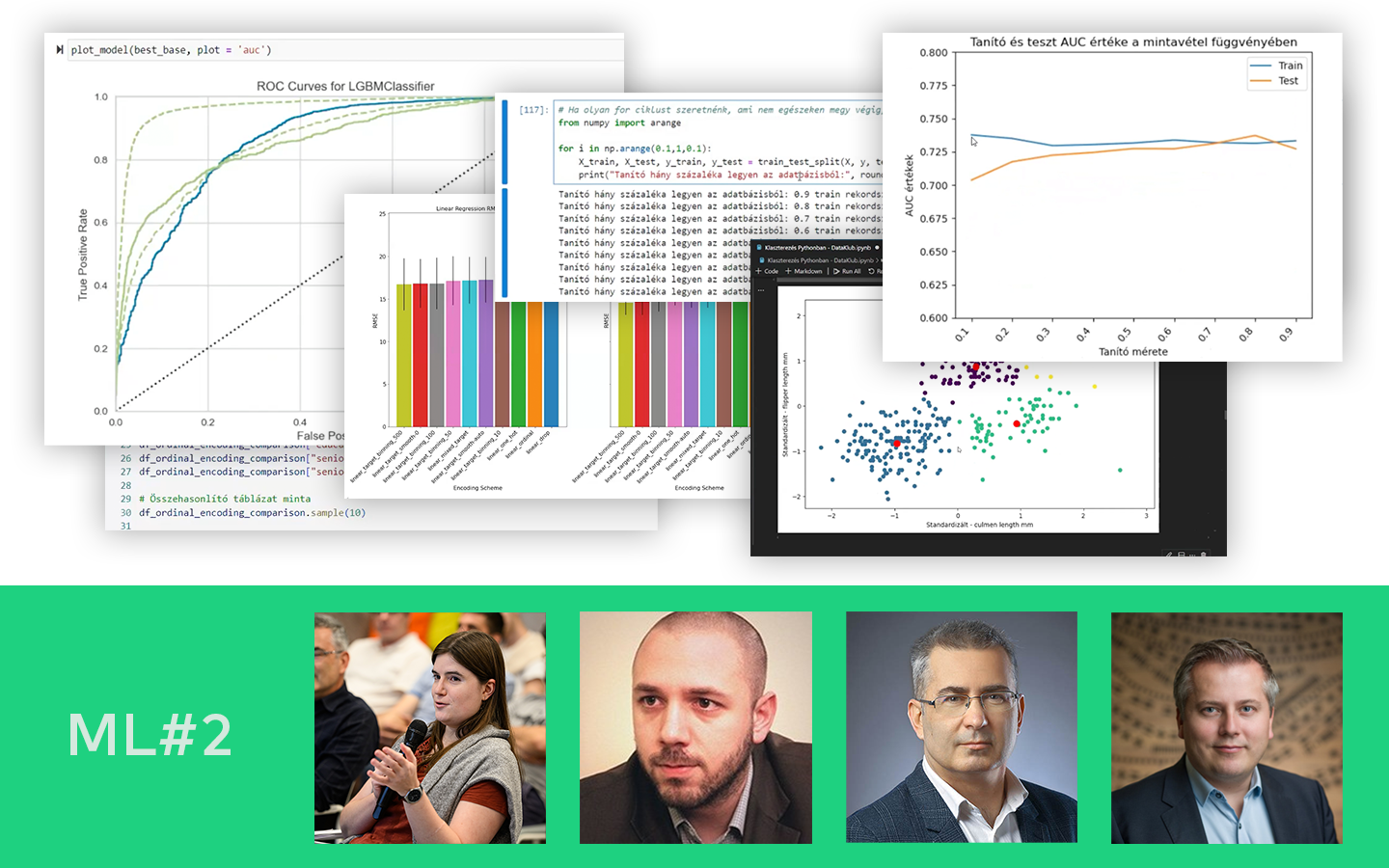
A „Klaszterezés Python-ban (koncepció, kódolás, esettanulmány)” előadásban azt tanulod meg, hogyan találj értelmezhető mintázatokat címkézetlen adatokban, és hogyan döntsd el, hány csoporttal érdemes dolgozni. Böjte Berta (Senior Data Scientist, Starschema) egy konkrét pingvin-adathalmazon vezet végig a teljes folyamaton az adatelőkészítéstől a kiértékelésig. Két változóval (csőrhossz és flipper/szárnyhossz) vizsgálja, kialakulnak‑e természetes csoportok a pontfelhőben, és közben valódi scikit-learn kódban mutatja meg, mire figyelj a távolságoknál, a random state-nél és a hiperparaméterezésnél, hogy a klaszterezés ne csak „szép ábra”, hanem használható eredmény legyen.
Milyen főbb témákról van szó az előadásban?
- Adatbetöltés és tisztítás: hiányzó értékek kezelése, alap leíró statisztikák (például elemszám, átlagok) a kiindulási állapot megértéséhez.
- Standardizálás (skálázás) és miért fontos: euklideszi távolságon alapuló módszereknél a különböző mértékegységek és nagyságrendek torzíthatnak; StandardScaler használata és a hatás vizualizálása.
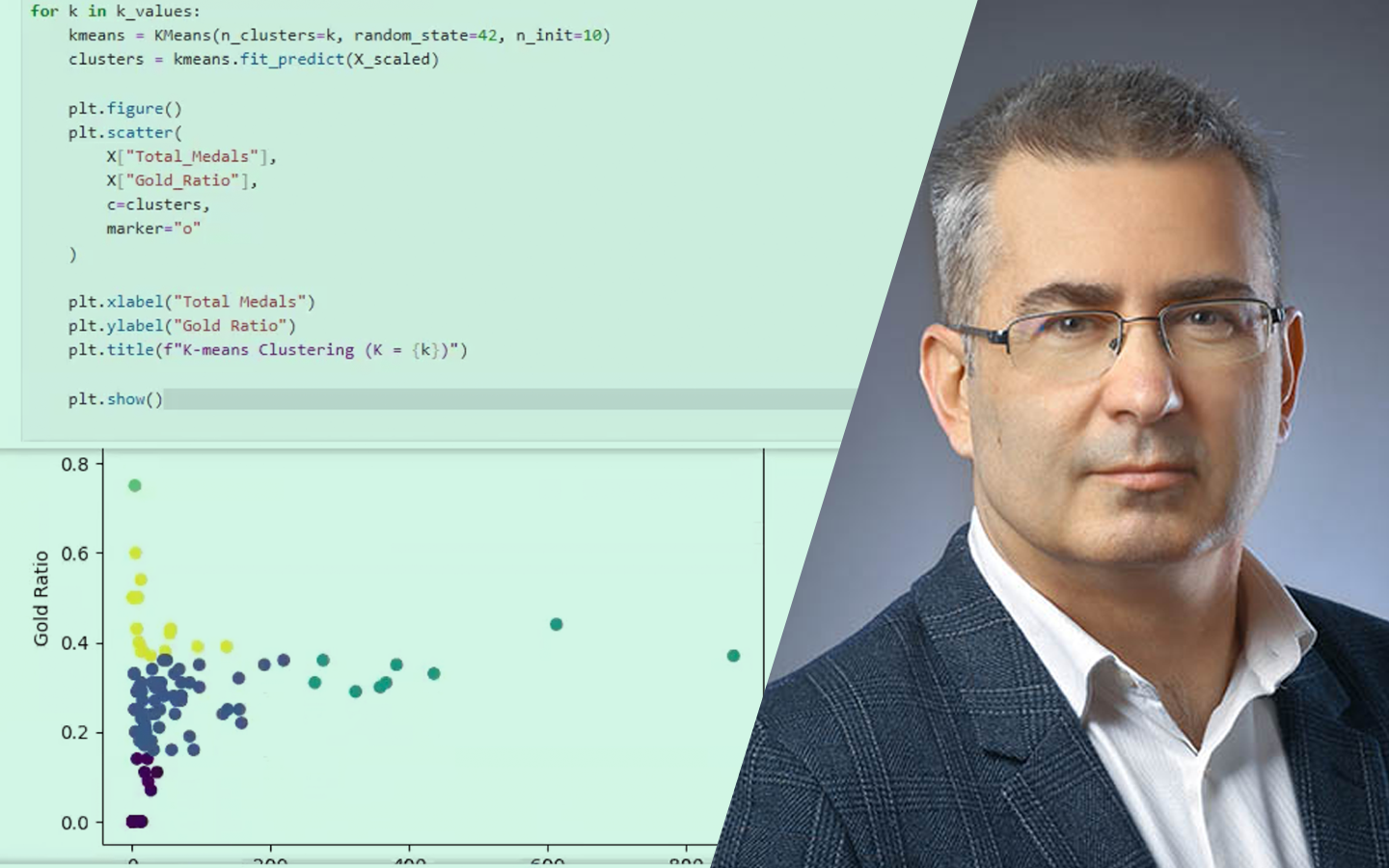
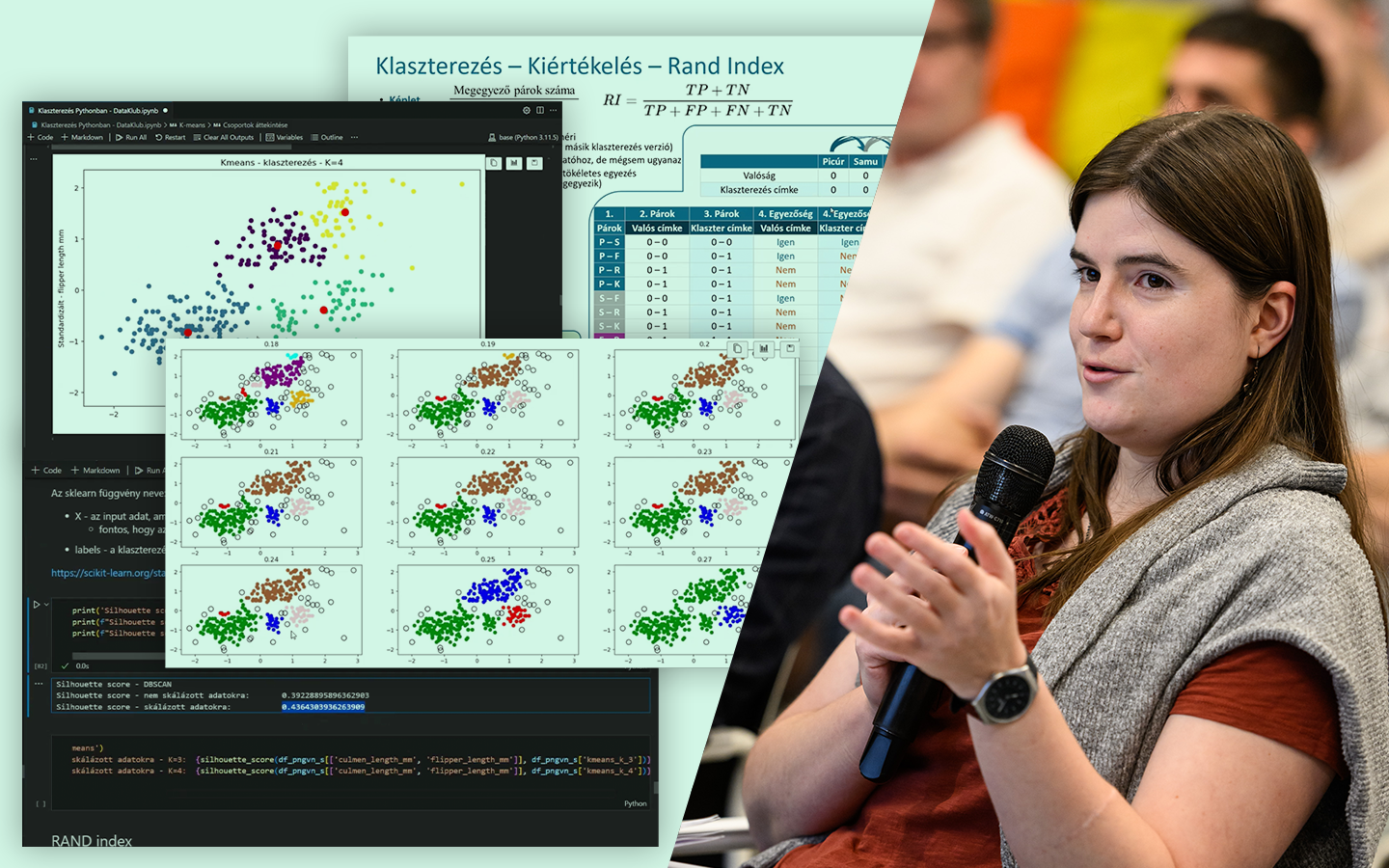
- K-means implementáció scikit-learnnel: a k és a random_state szerepe, centroidok, pontok besorolása, valamint a scatter plotok értelmezése.
- Optimális klaszterszám kiválasztása: könyökdiagram (inertia) számítása több K értékre, és annak gyakorlati értelmezése.
- DBSCAN a gyakorlatban: epsilon és min_samples jelentése, outlierek kezelése (-1 címke), hiperparaméter-hangolás k‑távolságdiagram alapján.
- Klaszterek kiértékelése és összehasonlítása: sziluett-score (külön figyelve a skálázott adatra), Rand-index különböző klaszterezések között, majd összevetés a rendelkezésre álló „species” címkékkel.