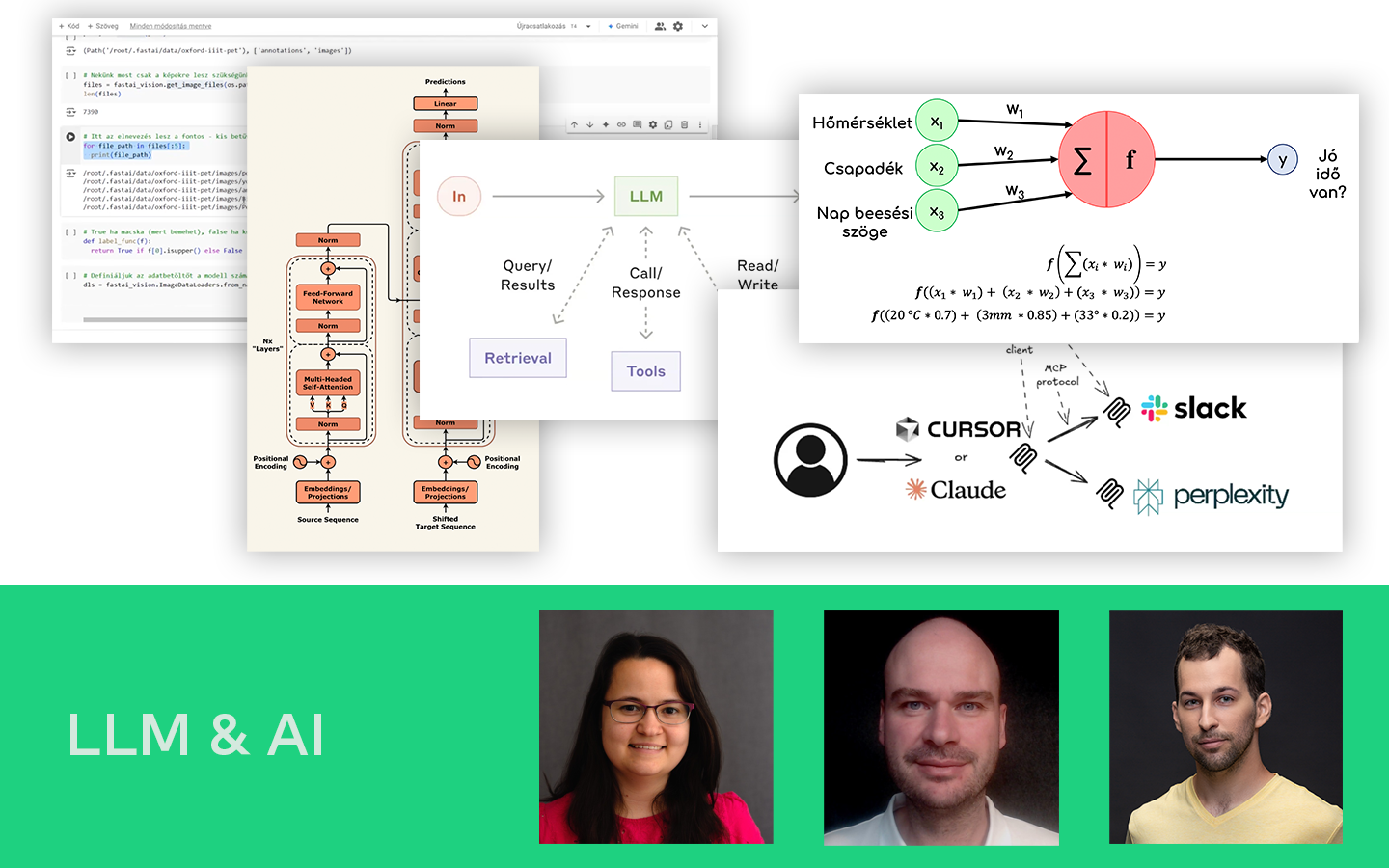
Ha szeretnéd érteni, mi történik a „varázslat” mögött, ez az előadás segít rendszerezni, hogyan lett a Transformer architektúra a mai LLM-ek (pl. ChatGPT) alapja. Hodvogner Szilvia (Data Scientist, AI fejlesztő @Siemens) végigvezet azon az úton, amely az RNN/LSTM megközelítésektől az attention mechanizmusig és a kódoló–dekódoló felépítésig vezet. Közben érthető keretet ad a kulcsfogalmakhoz — például embedding, self- és multi-head attention, maszkok és cross-attention —, hogy lásd, mi miért fontos a gyakorlatban. A végére azt is tisztábban látod, hogyan lesz egy pre-trained modellből használható asszisztens instruction tuninggal és humán visszajelzésen alapuló finomhangolással.
Milyen főbb témákról van szó az előadásban?
- Hogyan jutottunk el a Transformerekig? RNN → LSTM → sequence-to-sequence: miért „felejtettek” a korábbi modellek hosszú szövegeknél, és milyen tanulási/számítási korlátokat kellett megoldani (pl. vanishing gradient, szekvenciális feldolgozás).
- Attention mechanizmus (a kulcsötlet): self-attention és multi-head attention: hogyan tud a modell egyszerre több token kapcsolatára „ráfigyelni”, és mi a szerepe a Q–K–V mátrixoknak, a softmaxnak és a stabilizáló skálázásnak.
- A Transformer építőelemei: embedding, tokenizáció és positional encoding; feed-forward rétegek; normalizáció és reziduális kapcsolatok — mit ad hozzá mindegyik a stabil tanuláshoz és a jobb reprezentációhoz.
- Encoder vs. Decoder (olvasók és írók): mikor elég az encoder-only (megértés: pl. sentiment, NER), és mikor decoder-only (generálás: chatbotok), valamint miért kell a dekóderben a masked attention.
- Hogyan lesz egy Transformerből „hasznos” chatbot? Pre-training → instruction tuning (supervised) → RLHF: hogyan tanulja meg a modell nemcsak a nyelvet, hanem az emberi preferenciákhoz igazodó válaszadást.