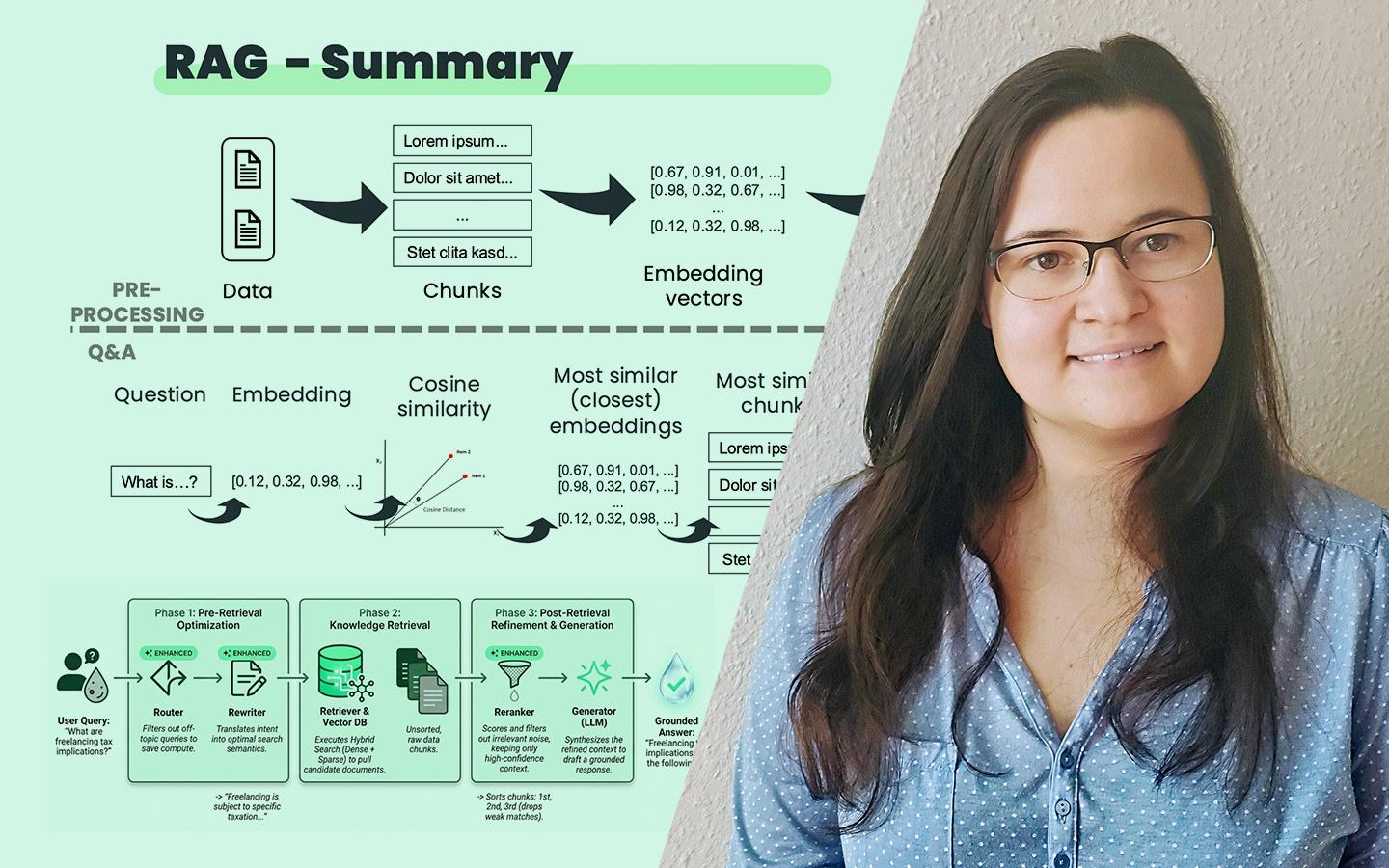
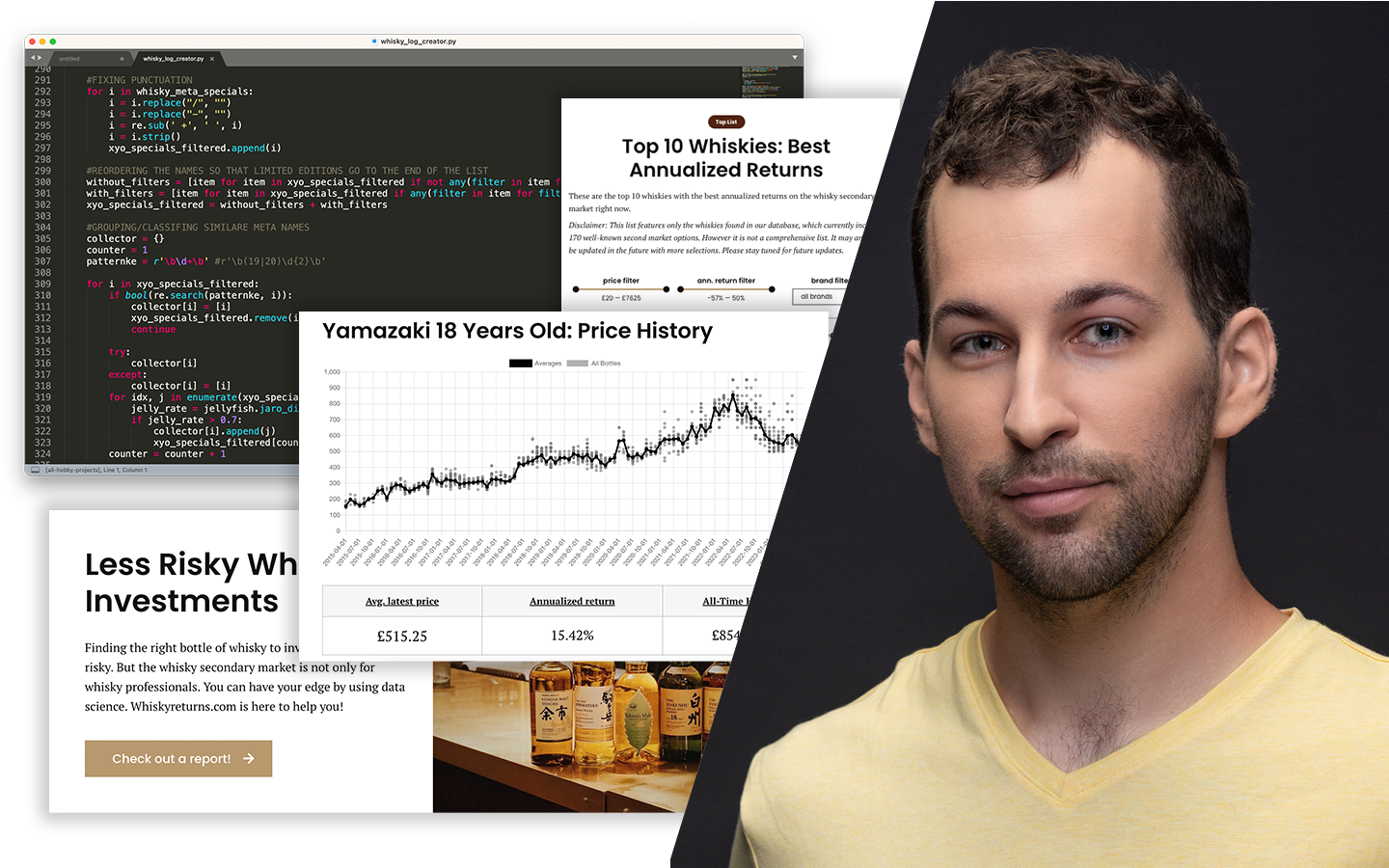
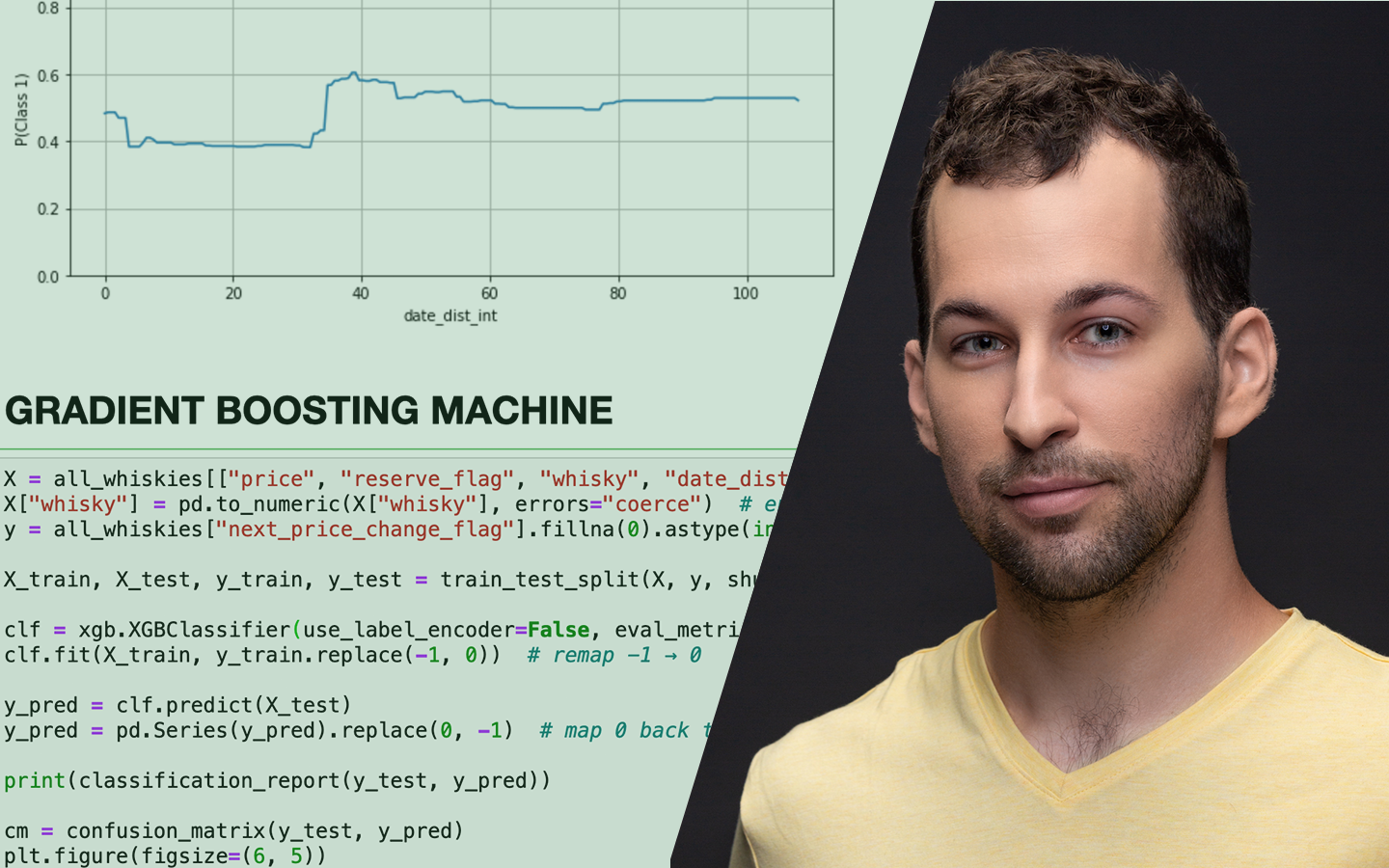
A „Train–Test Adathalmazok Felosztása (Az Összes Módszer, Amit Ismerned Kell)” előadásból megtanulod, miért nem elég sokszor a 70–30-as tankönyvi train–test split. És azt is, hogy hogyan vezethet egy rosszul megválasztott felosztás hamis biztonságérzethez, túltanuláshoz vagy instabil, élesben gyorsan romló modellhez. Kovács Gyula (Data Scientist, tréner, tanácsadó) gyakorlati példákon és Pythonos kísérleteken keresztül mutatja meg, hogyan érdemes adatfelosztási arányokat tesztelni, hogyan olvasd a train vs. test teljesítményt, milyen jobb módszerek vannak, mint az a bizonyos 70-30… De azt is, hogy mikor segít a cross-validation és, hogy idősoros adatoknál hogyan építs olyan teszt-adathalmazokat, amik segítségével hosszabb távon is megbízhatóan működik.
Milyen főbb témákról van szó az előadásban?
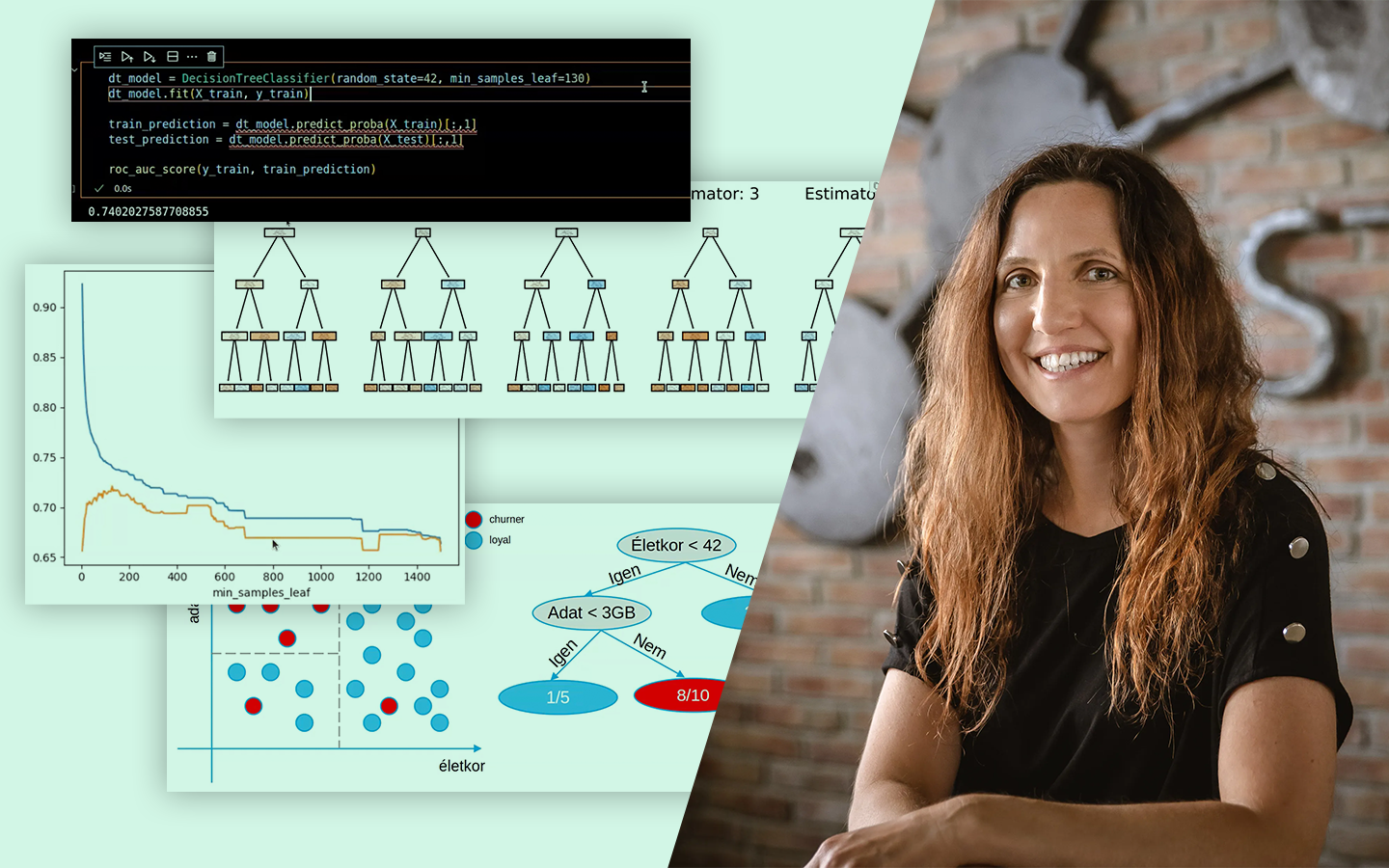
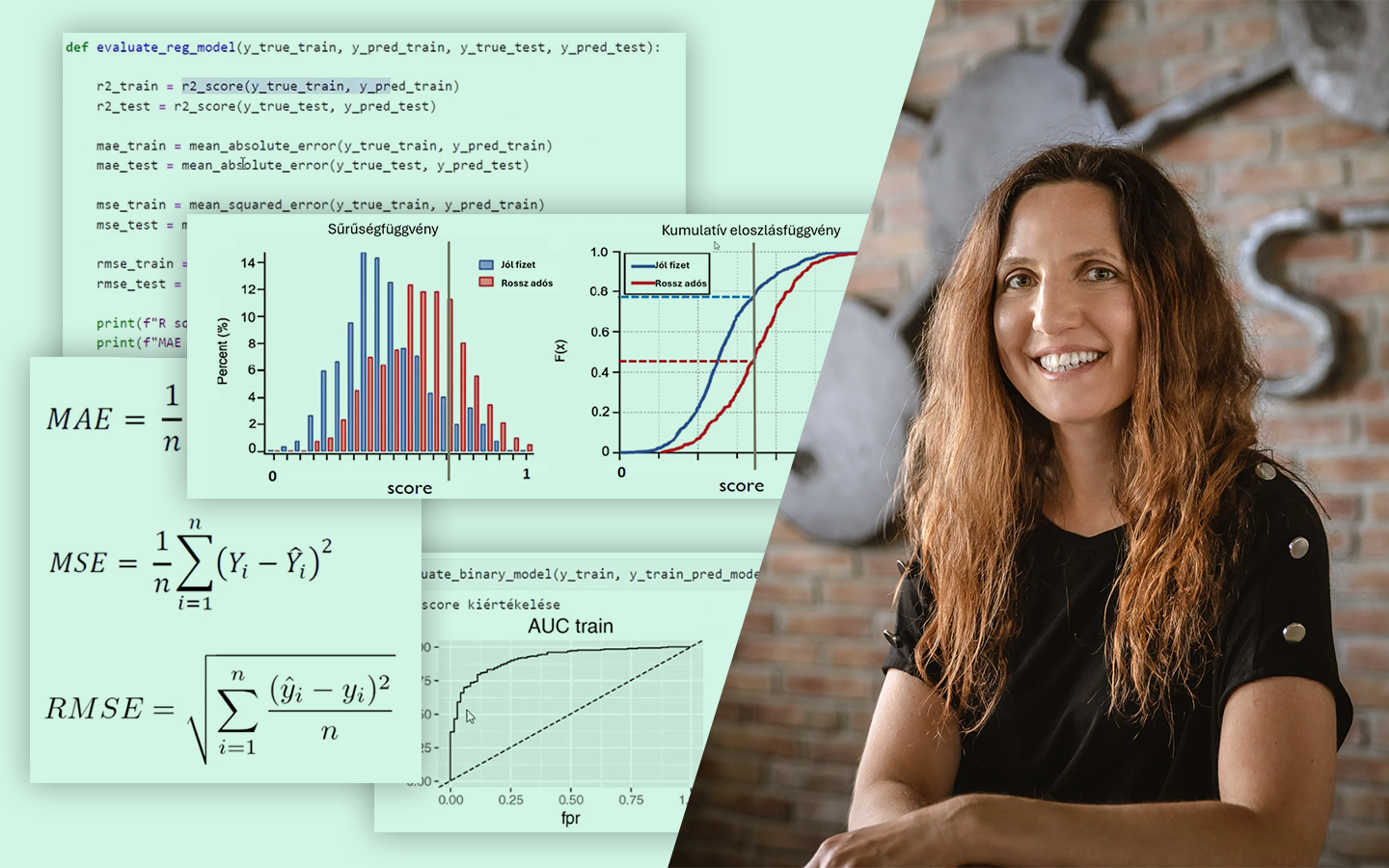
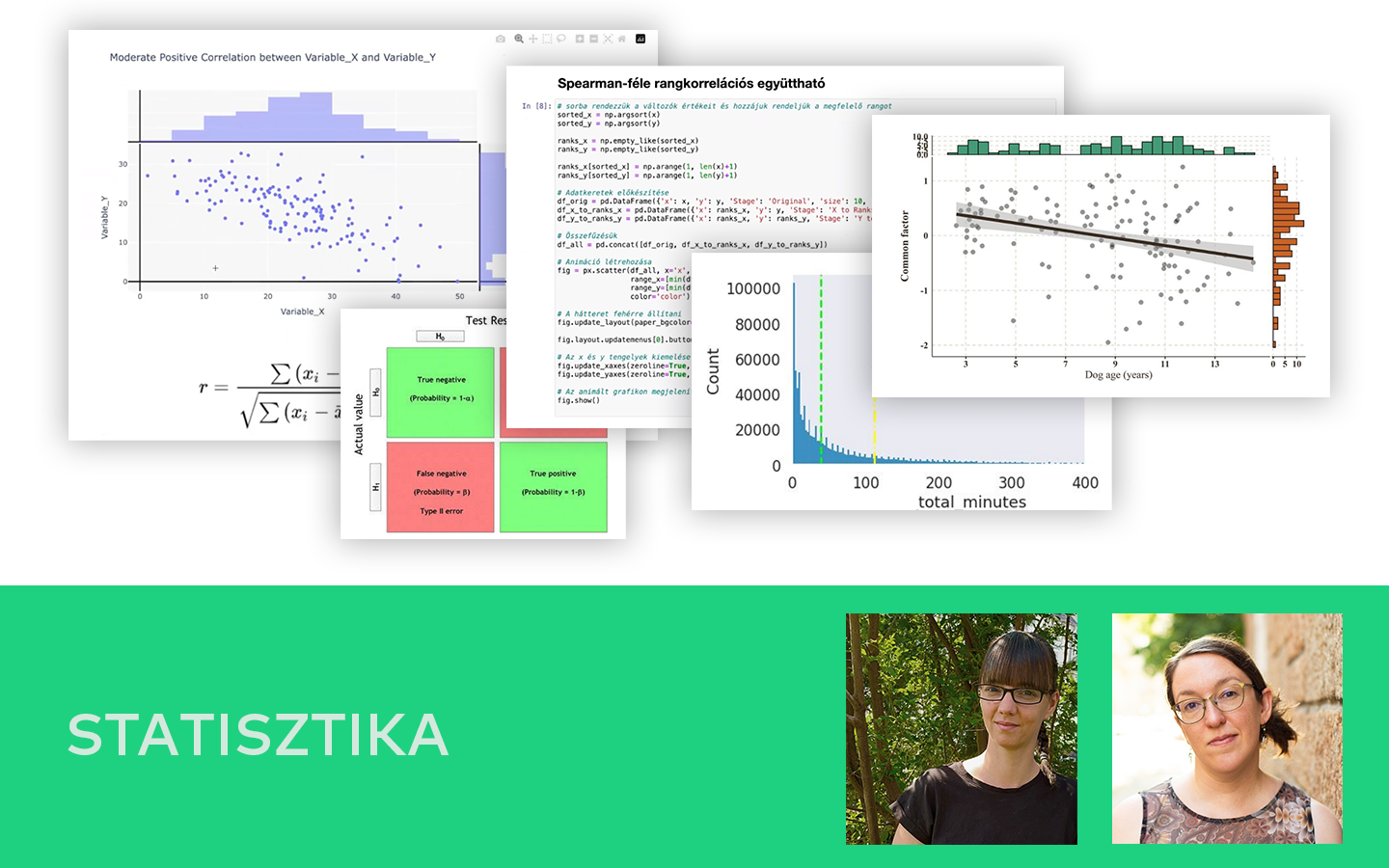
- Miért kritikus a jó felosztás? Hogyan lesznek „babonák” a tanítóadaton talált véletlen mintákból, és miért kell a teljesítményt mindig nem látott adaton ellenőrizni, hogy a modell valódi, új adatokon is megbízható legyen.
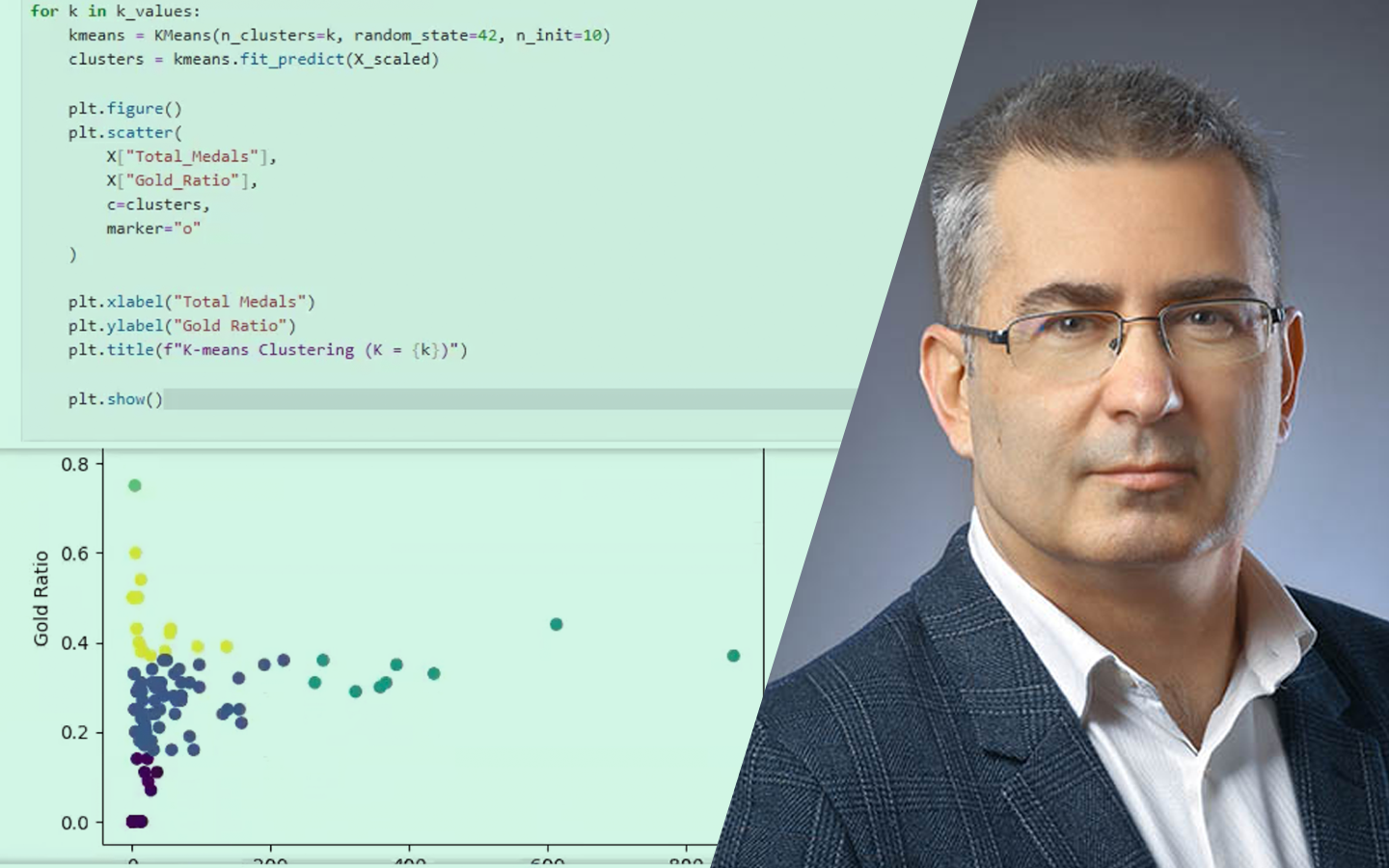
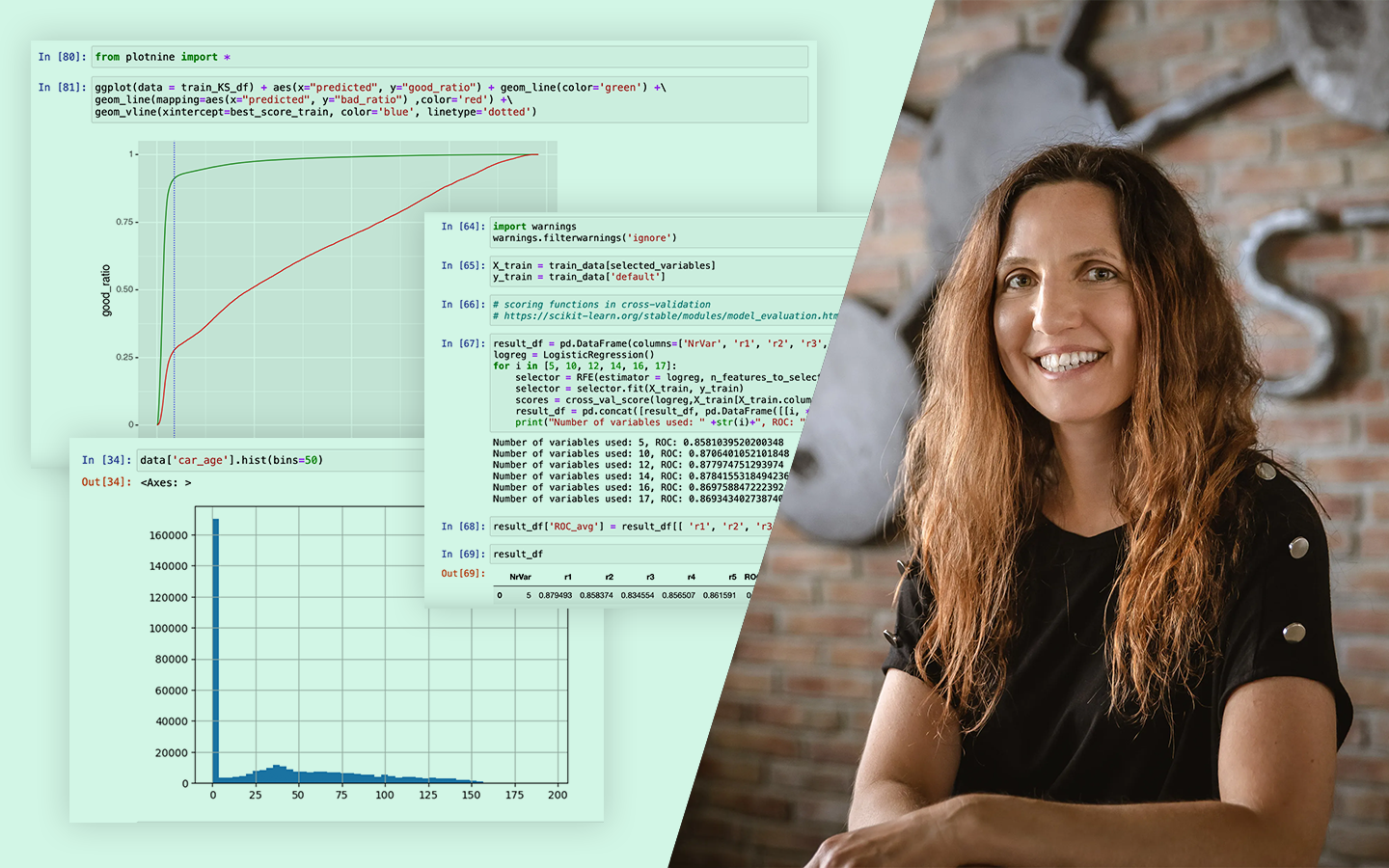
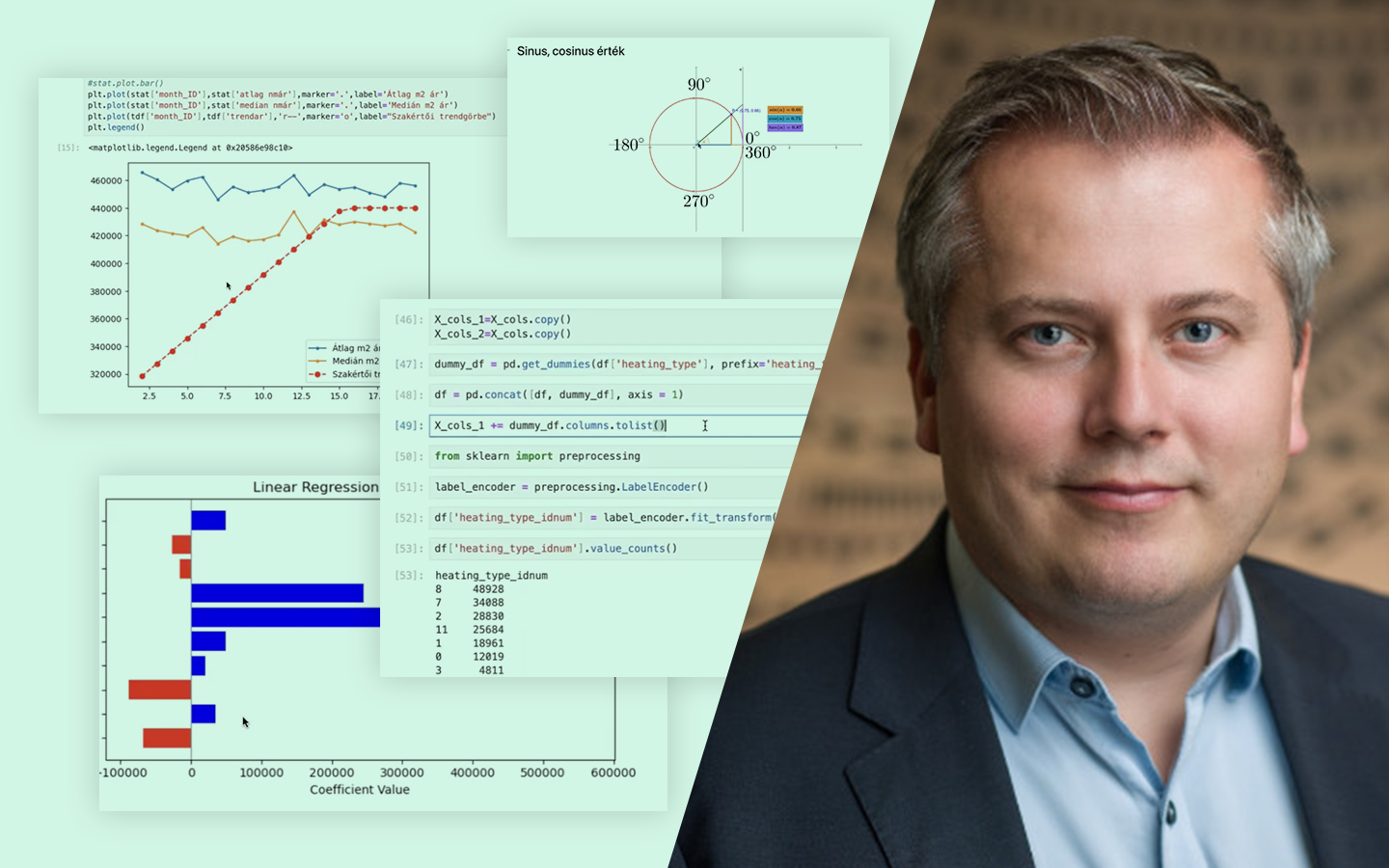
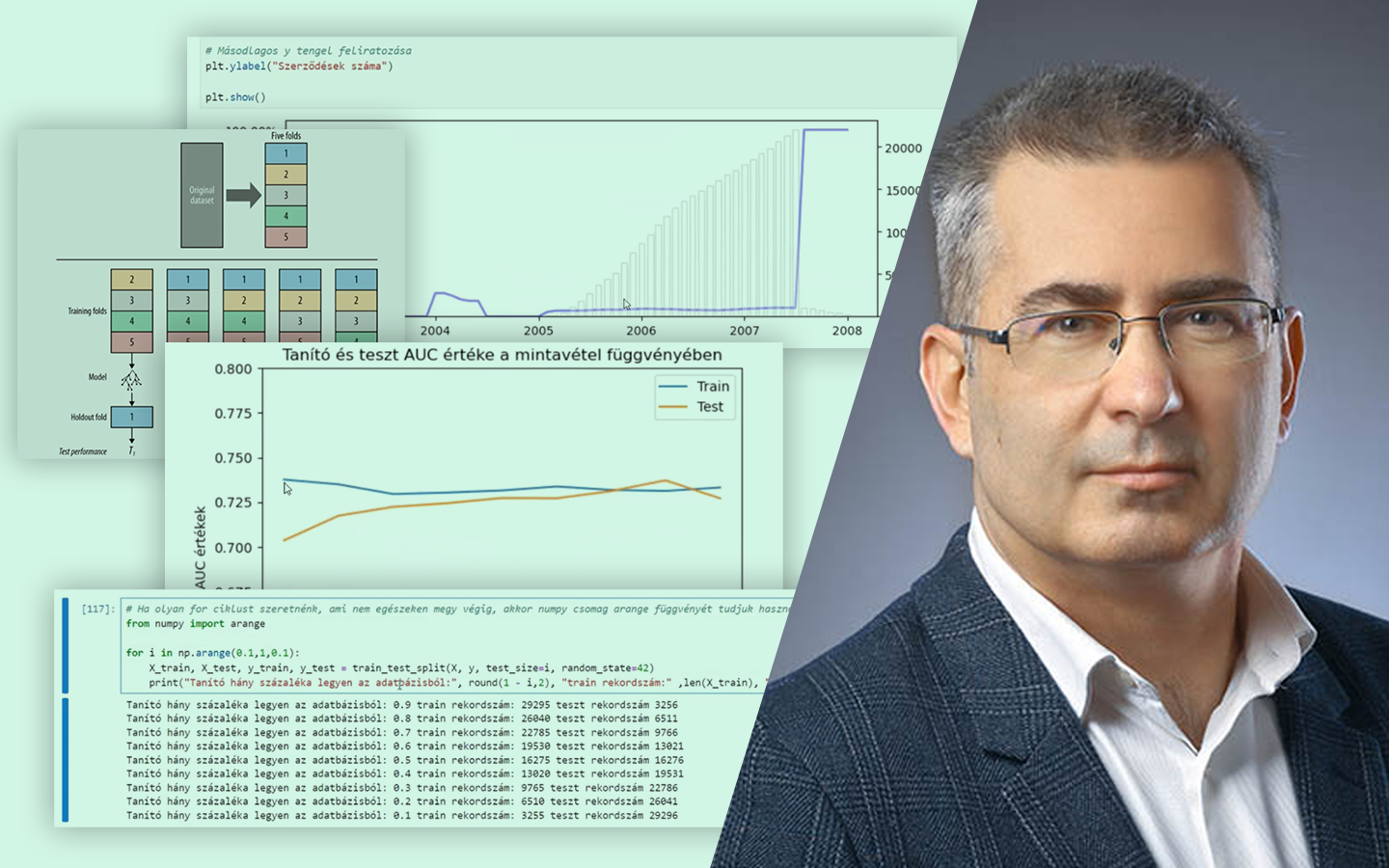
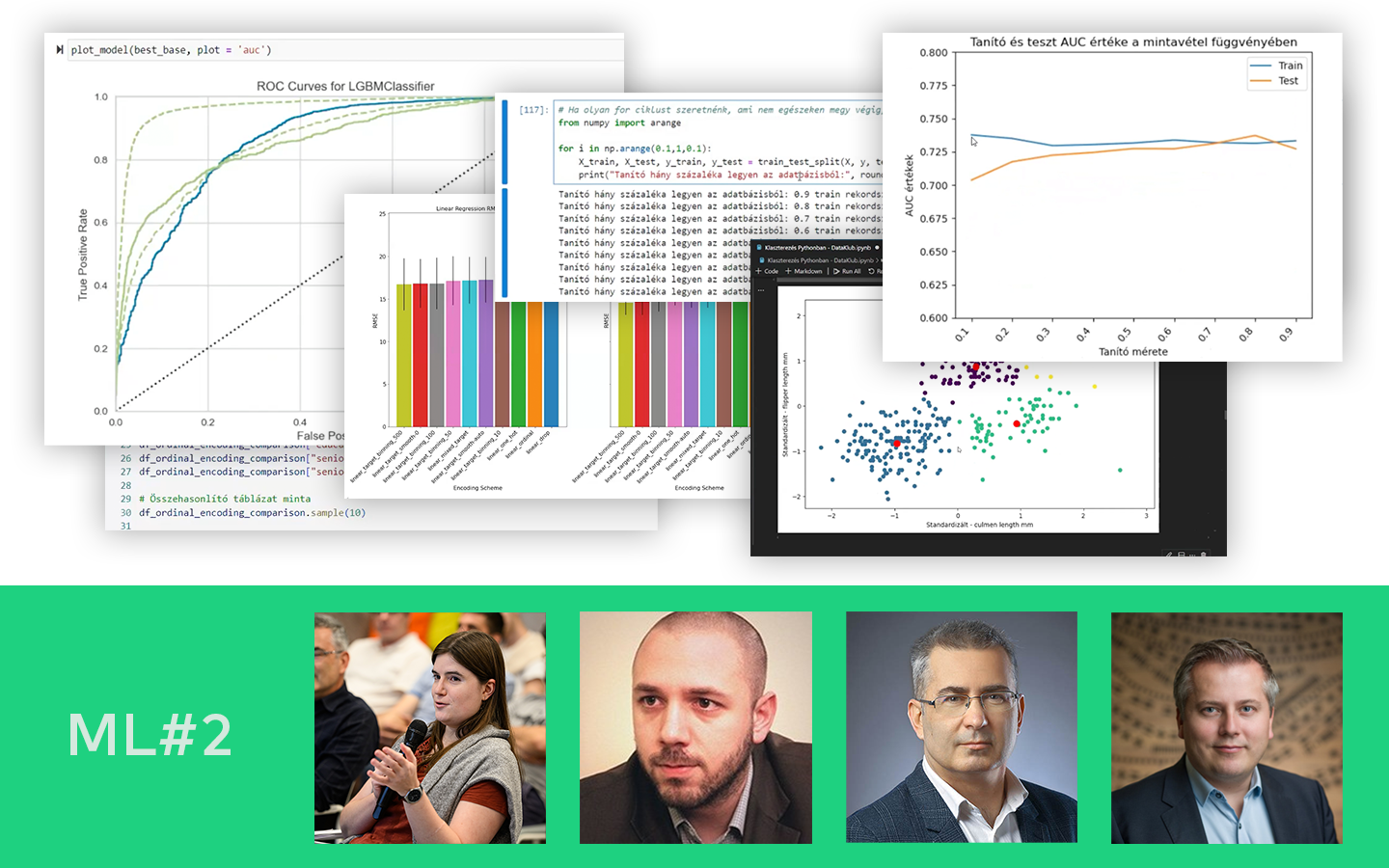
- A klasszikus 70/30 split – és miért nem szentírás Mikor működik jól a 70–30, és hogyan lehet több arányt (90/10-től 10/90-ig) for-ciklussal végigtesztelni AUC alapján, hogy ne megszokásból dönts.
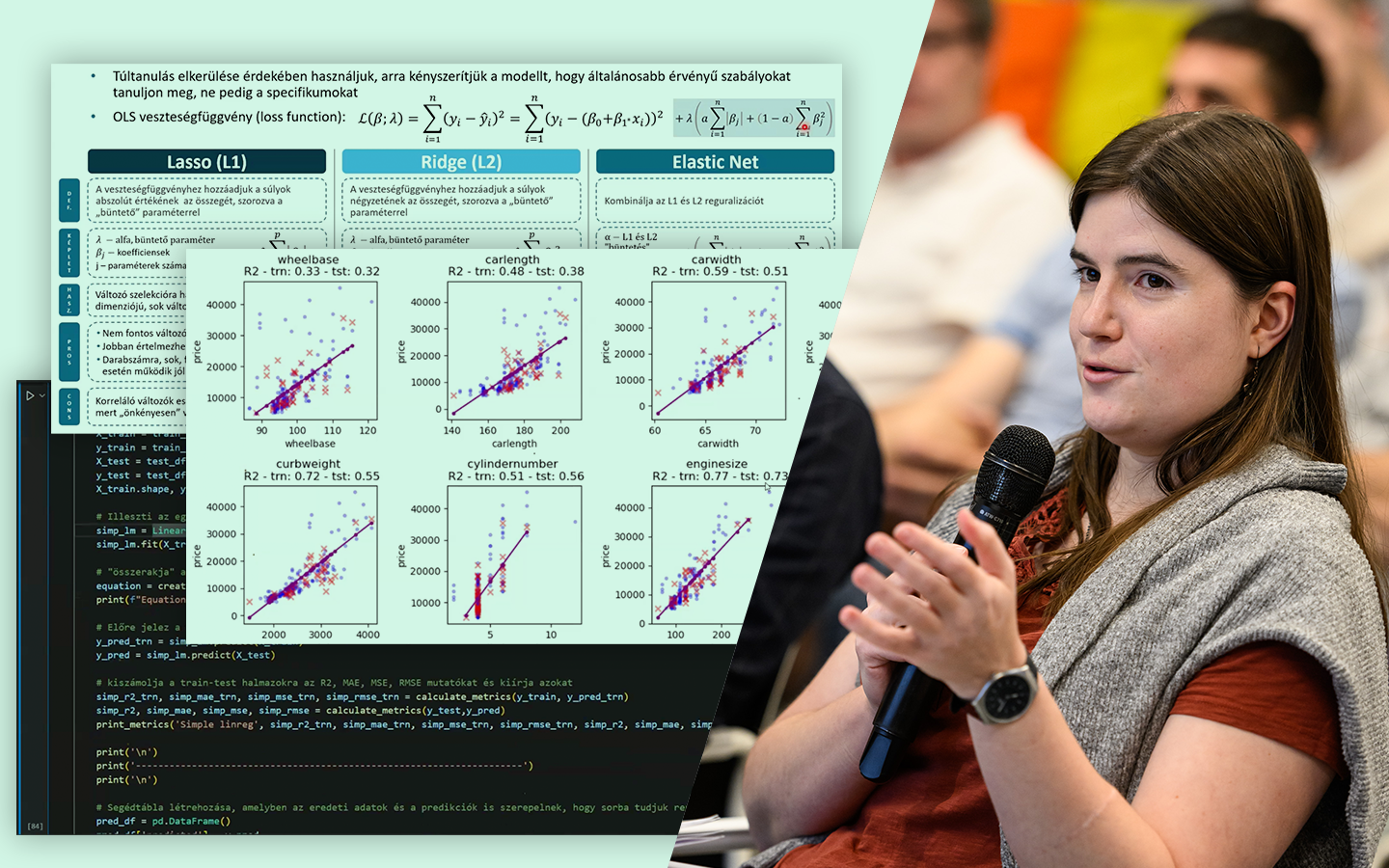
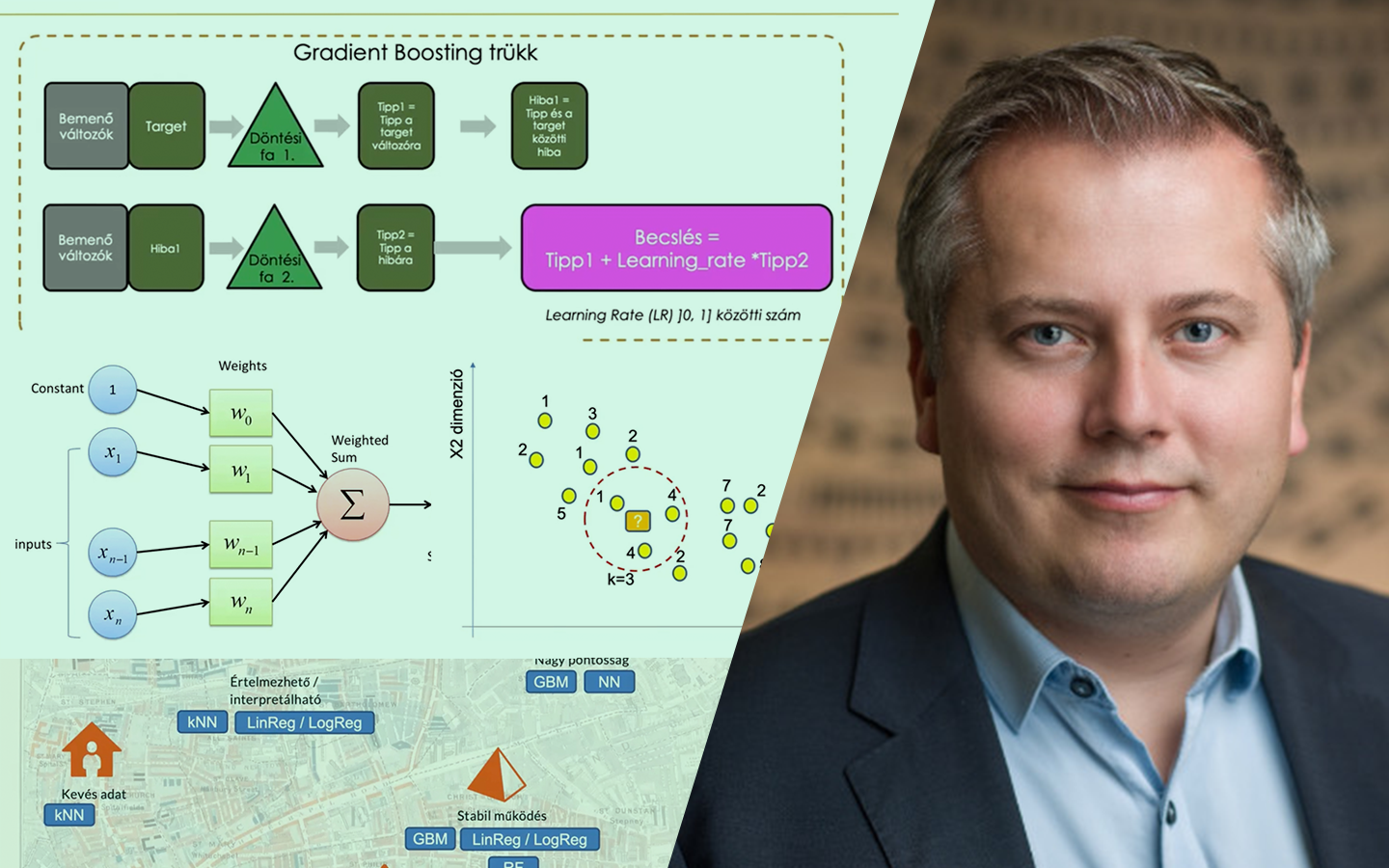
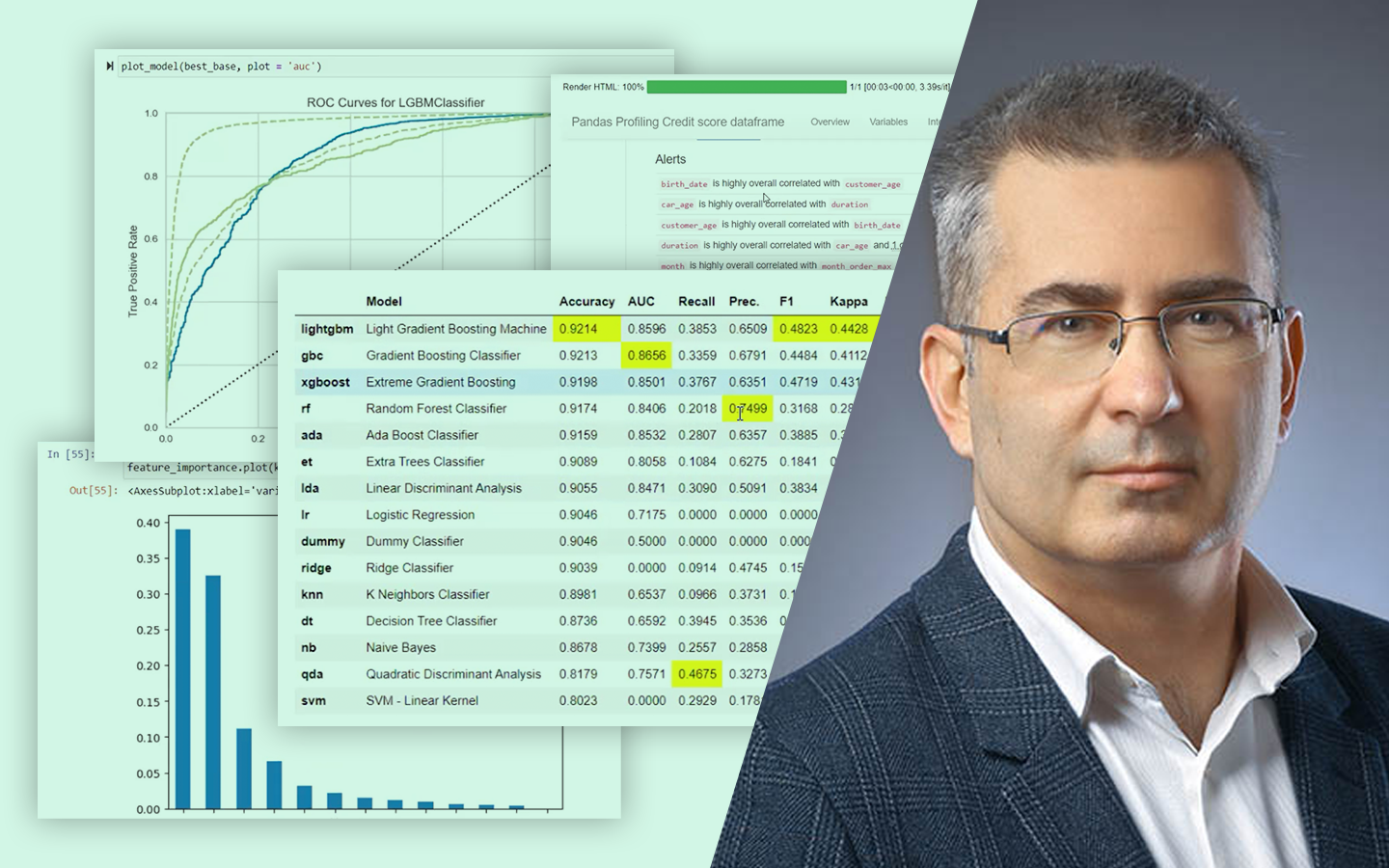
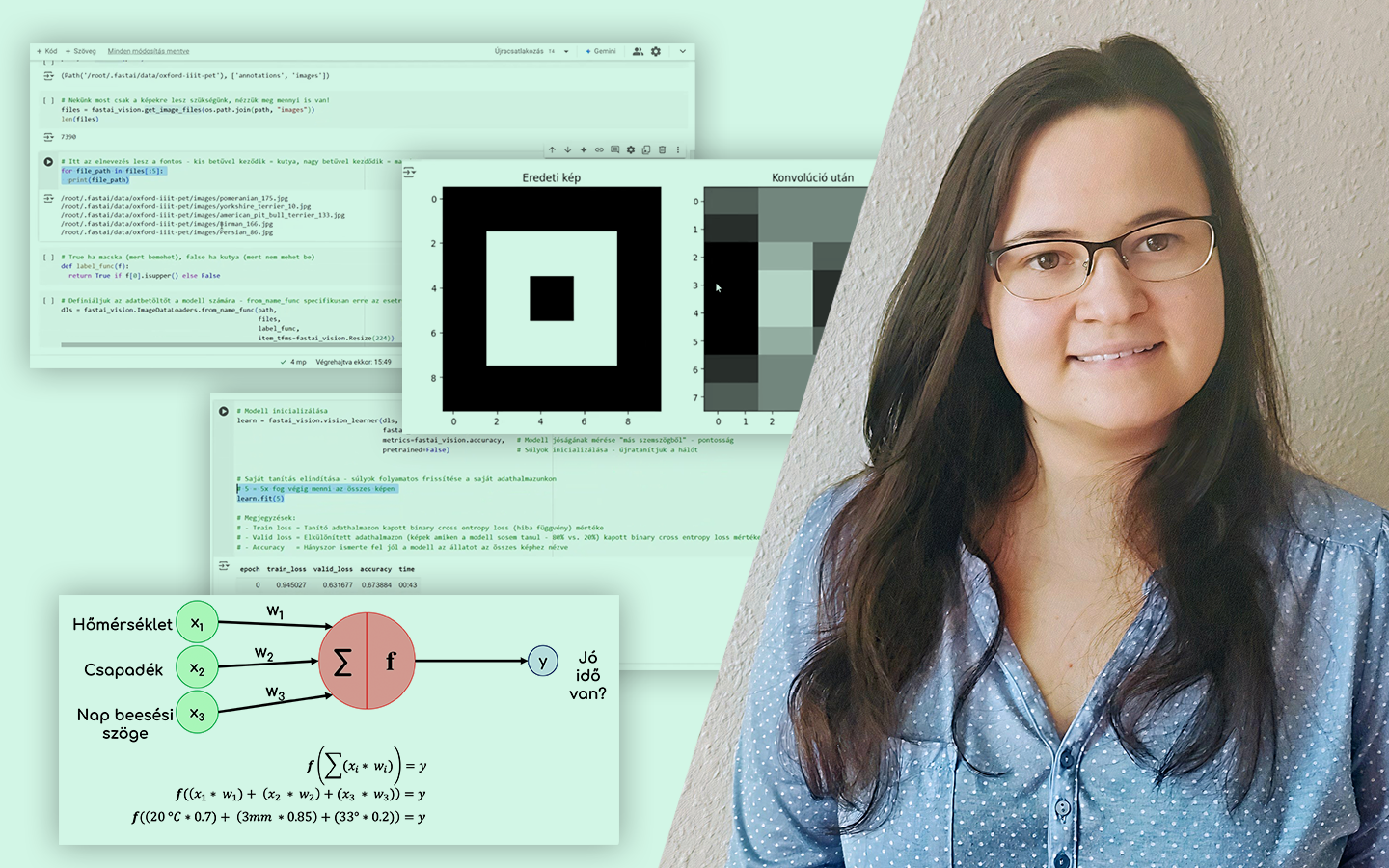
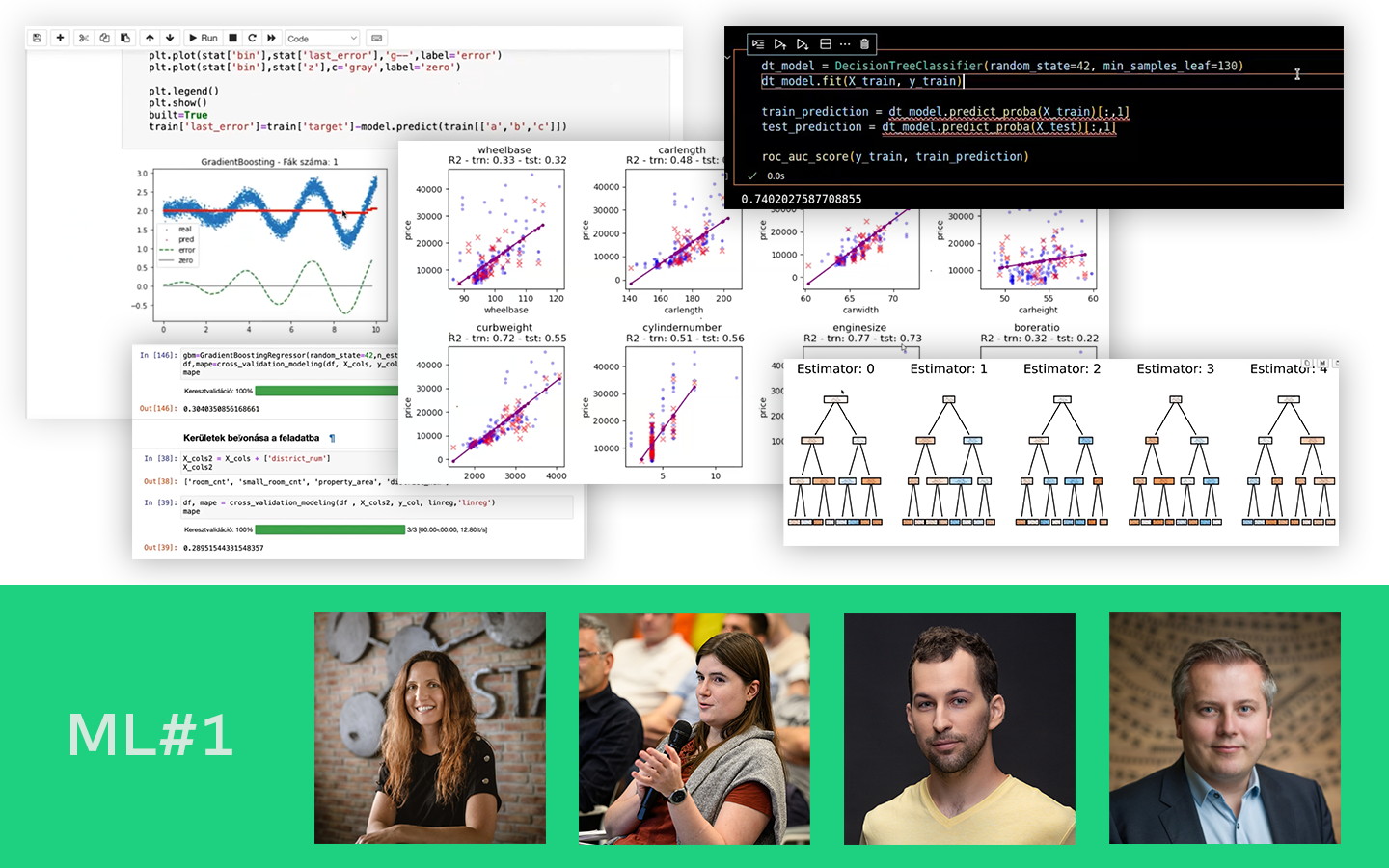
- Túltanulás felismerése különböző algoritmusoknál Logisztikus regresszió vs. döntési fa / ExtraTrees / Random Forest / Gradient Boosting: ugyanaz a split miért adhat teljesen eltérő képet, és hogyan értelmezd ezt helyesen.
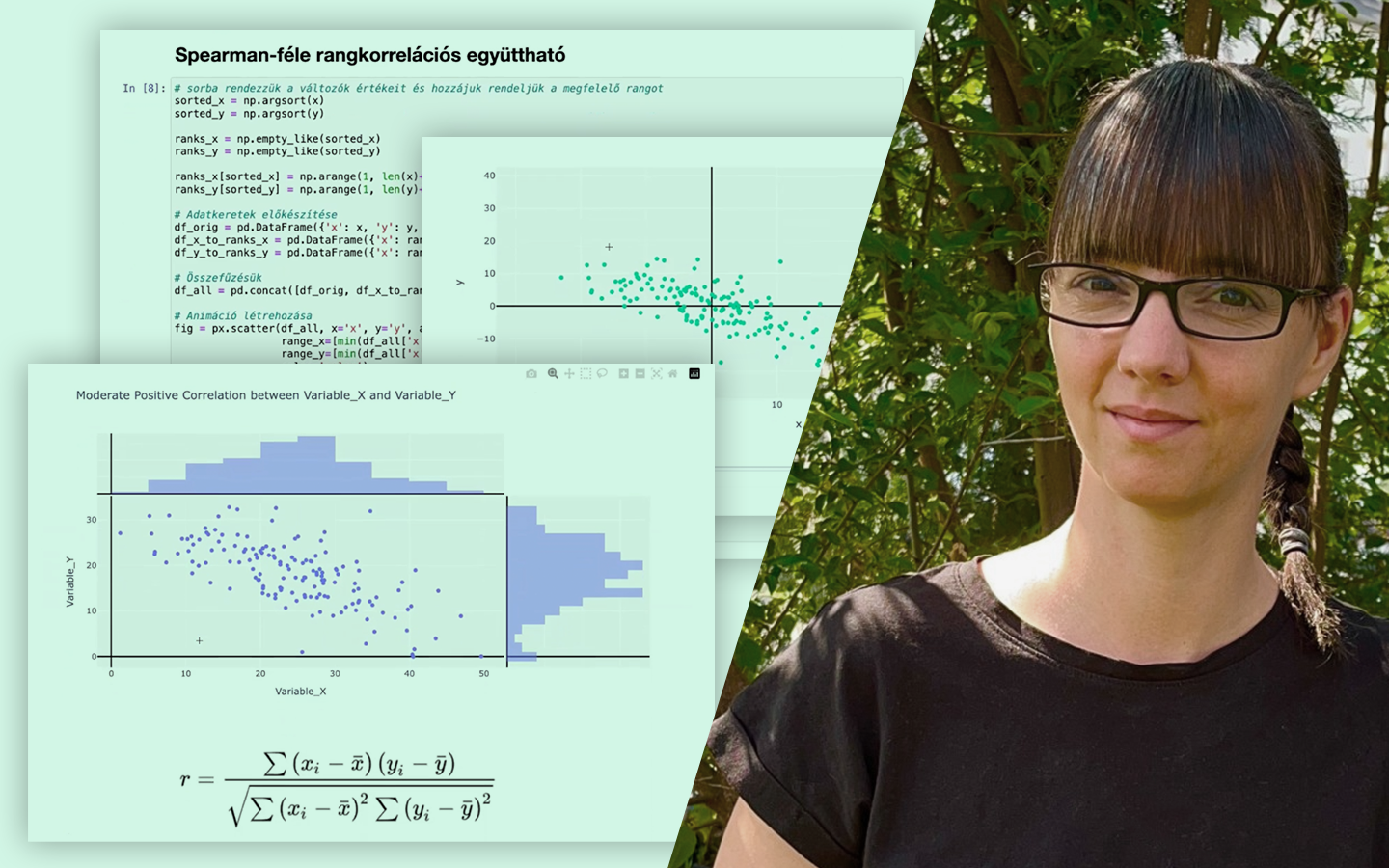
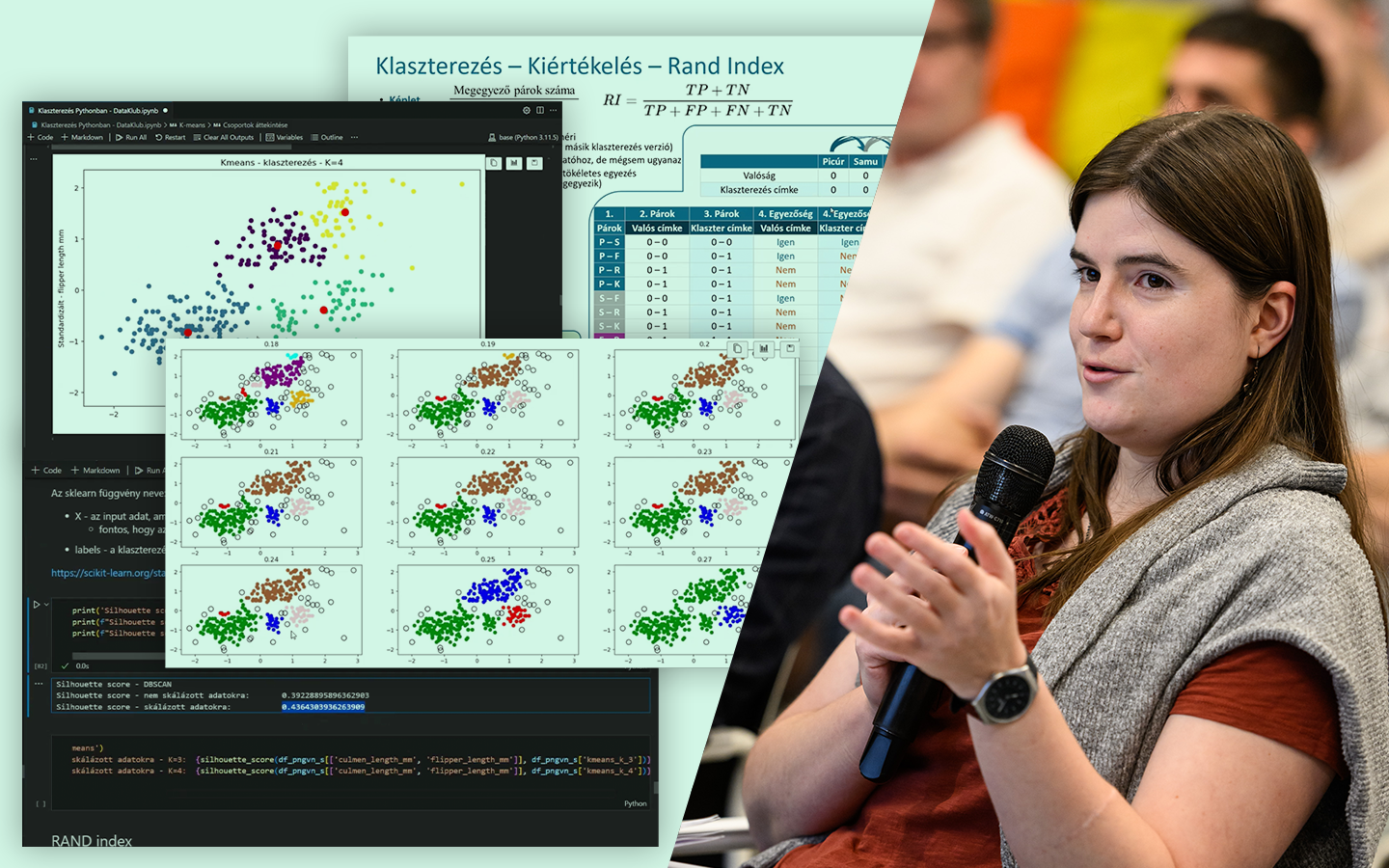
- K-fold cross-validation: átlag és szórás értelmezése Mit mond a szórás a modell stabilitásáról, és hogyan segít algoritmust választani, ha a véletlen mintavételezés erősen befolyásolja az eredményt.
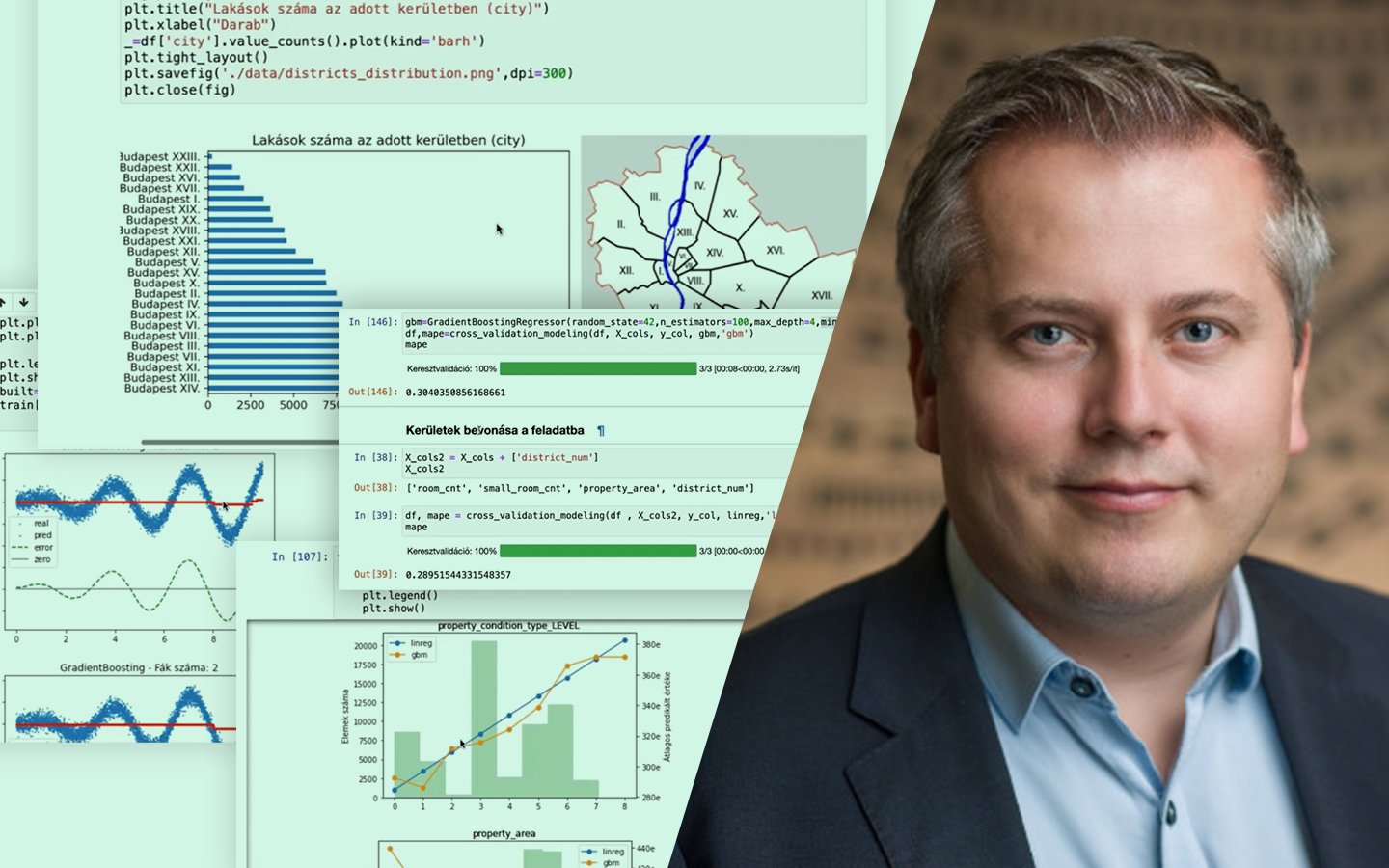
- Időbeli mintavételezés idősoros adatoknál Havi hiteladat példán: miért fontos a periódusok minőségének vizsgálata, és hogyan lehet idő szerint train–testet képezni a későbbi stabil működéshez.