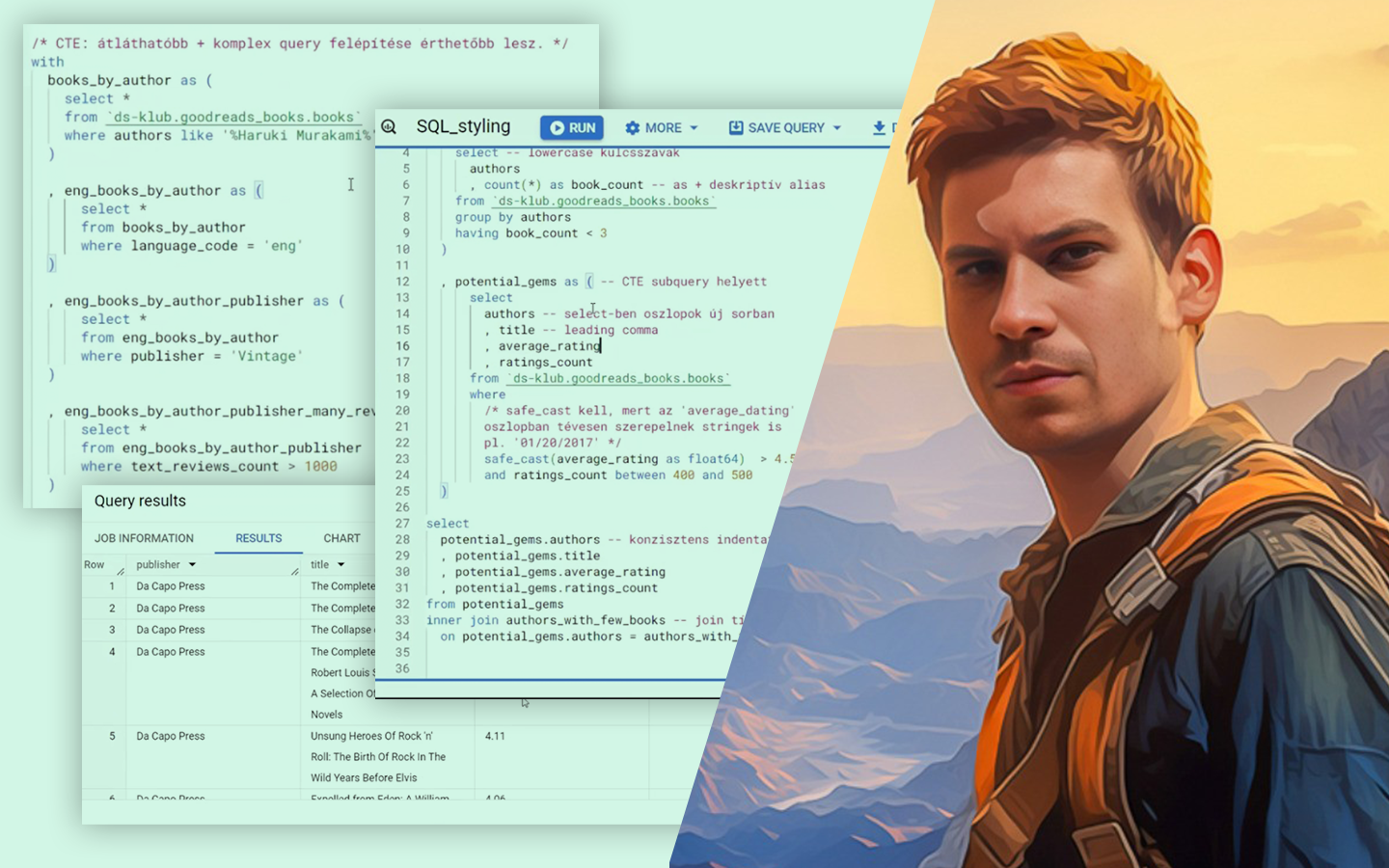
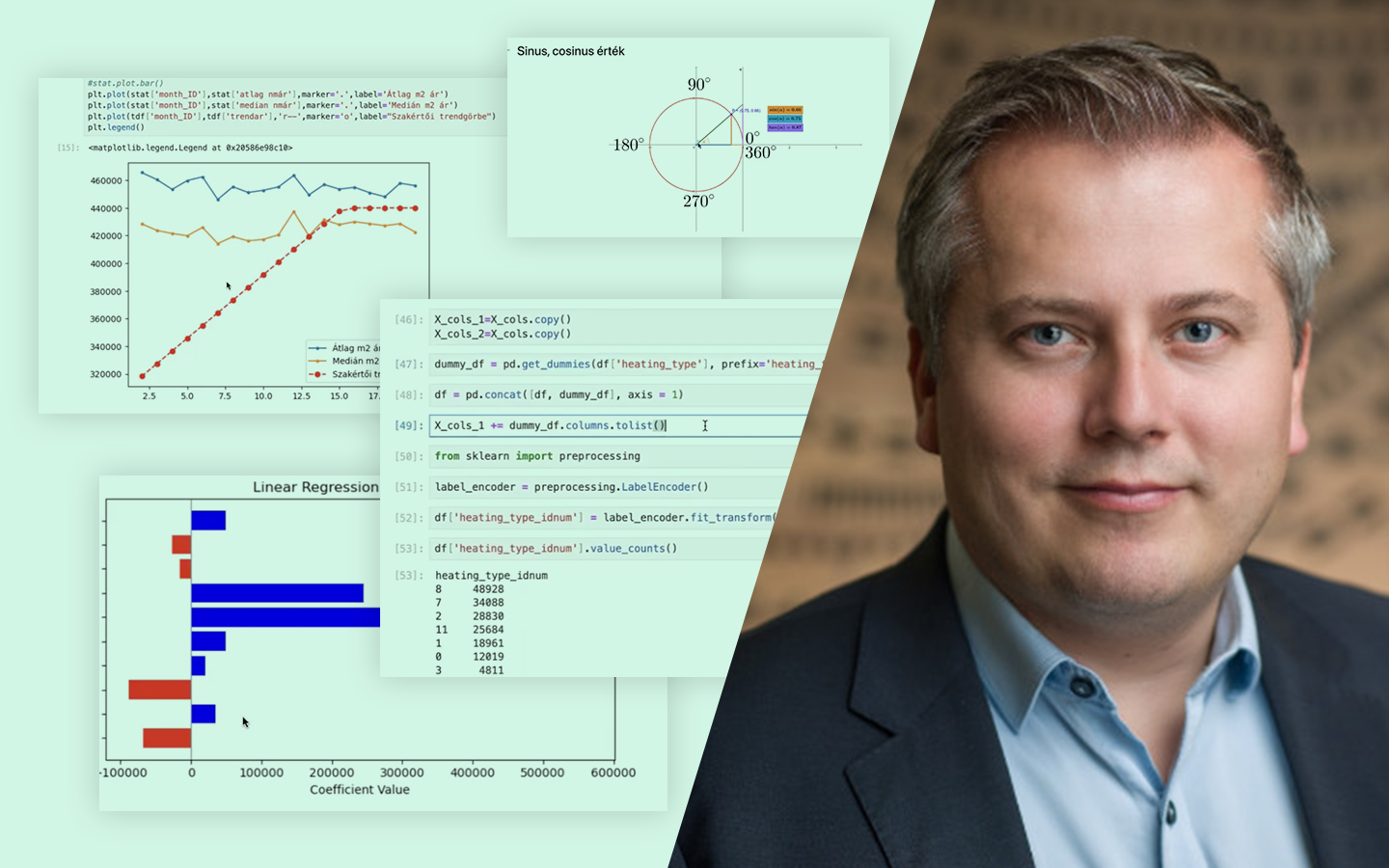
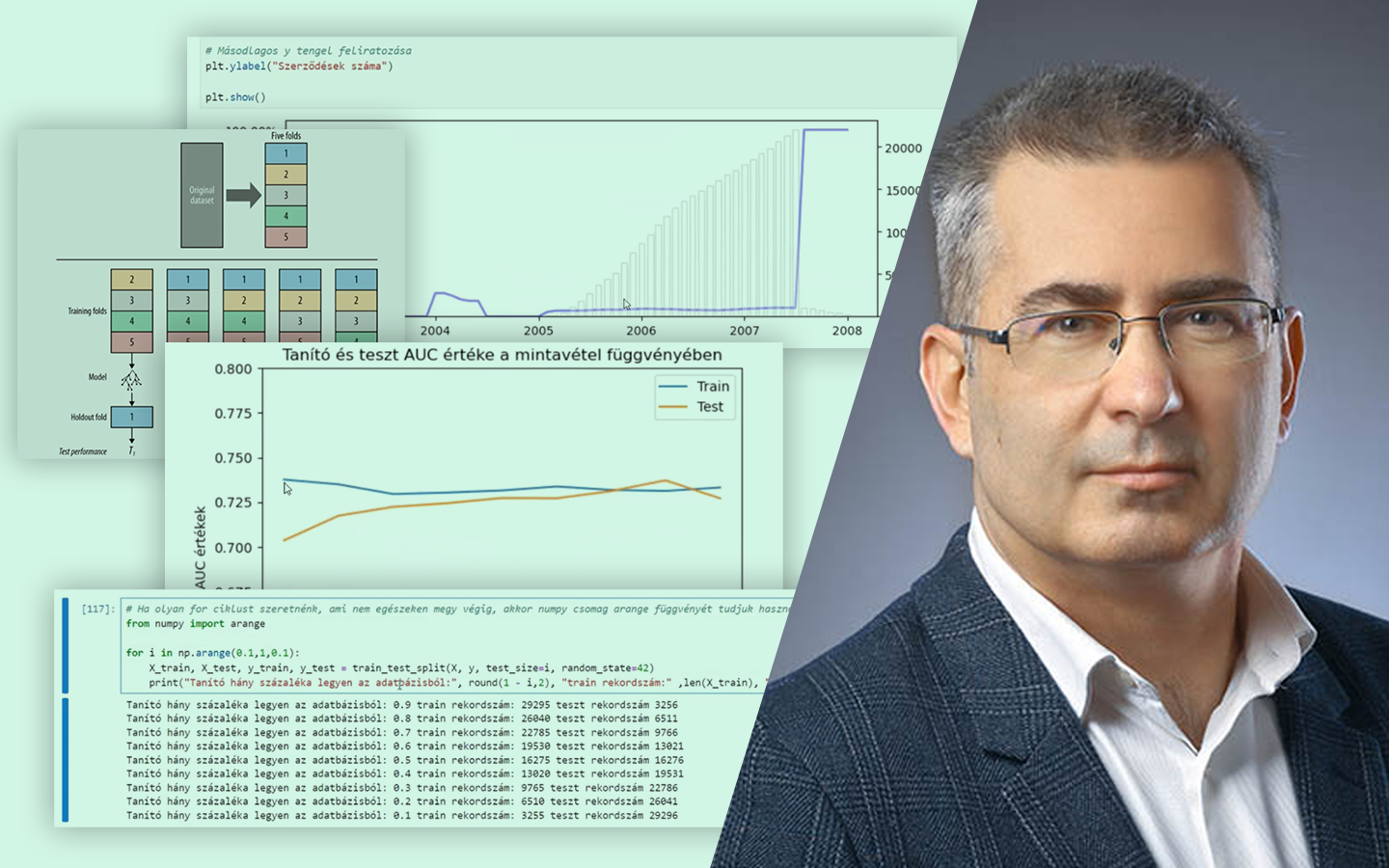
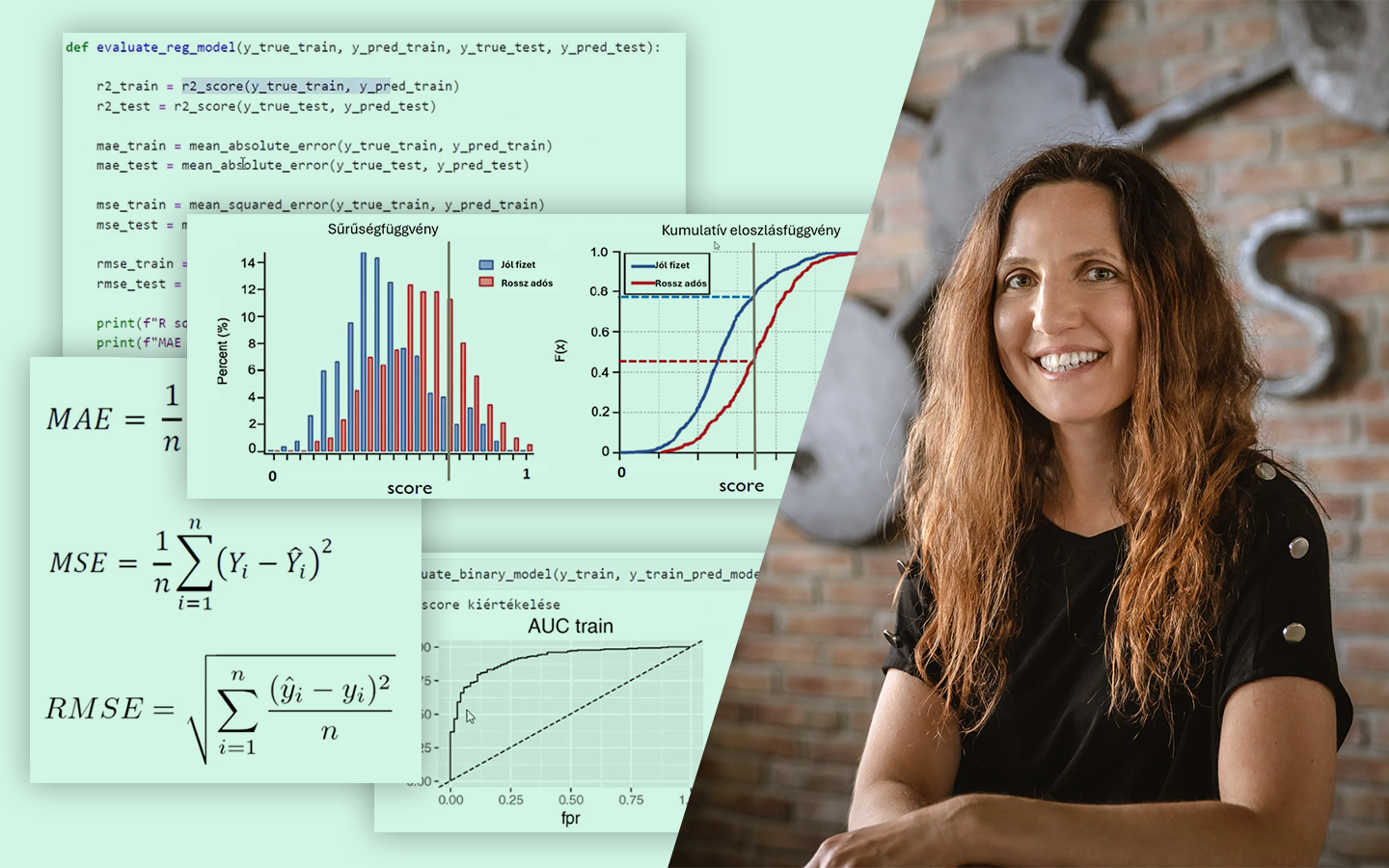
A Feature Engineering elmagyarázva 2. RÉSZ (gyakorlati példákkal) abban segít, hogy ne csak „átalakítsd” az adatokat, hanem célzottan olyan jellemzőket hozz létre, amelyekhez a választott modell valóban hozzáfér. Radó László (Lead Data Scientist, BT) kisméretű, jól követhető példákon mutatja meg, mikor érdemes transzformációkat, arányokat, összegeket, interakciókat vagy aggregációkat használni, és hogyan gondolkodj a lineáris modellek és döntési fák működéséről. Az előadás gyakorlati fókuszú: Pythonban, Jupyter Notebookkal dolgozik, a kódbázis pedig elérhető lesz, így a látottakat azonnal kipróbálhatod a saját projektjeidben.
Milyen főbb témákról van szó az előadásban?
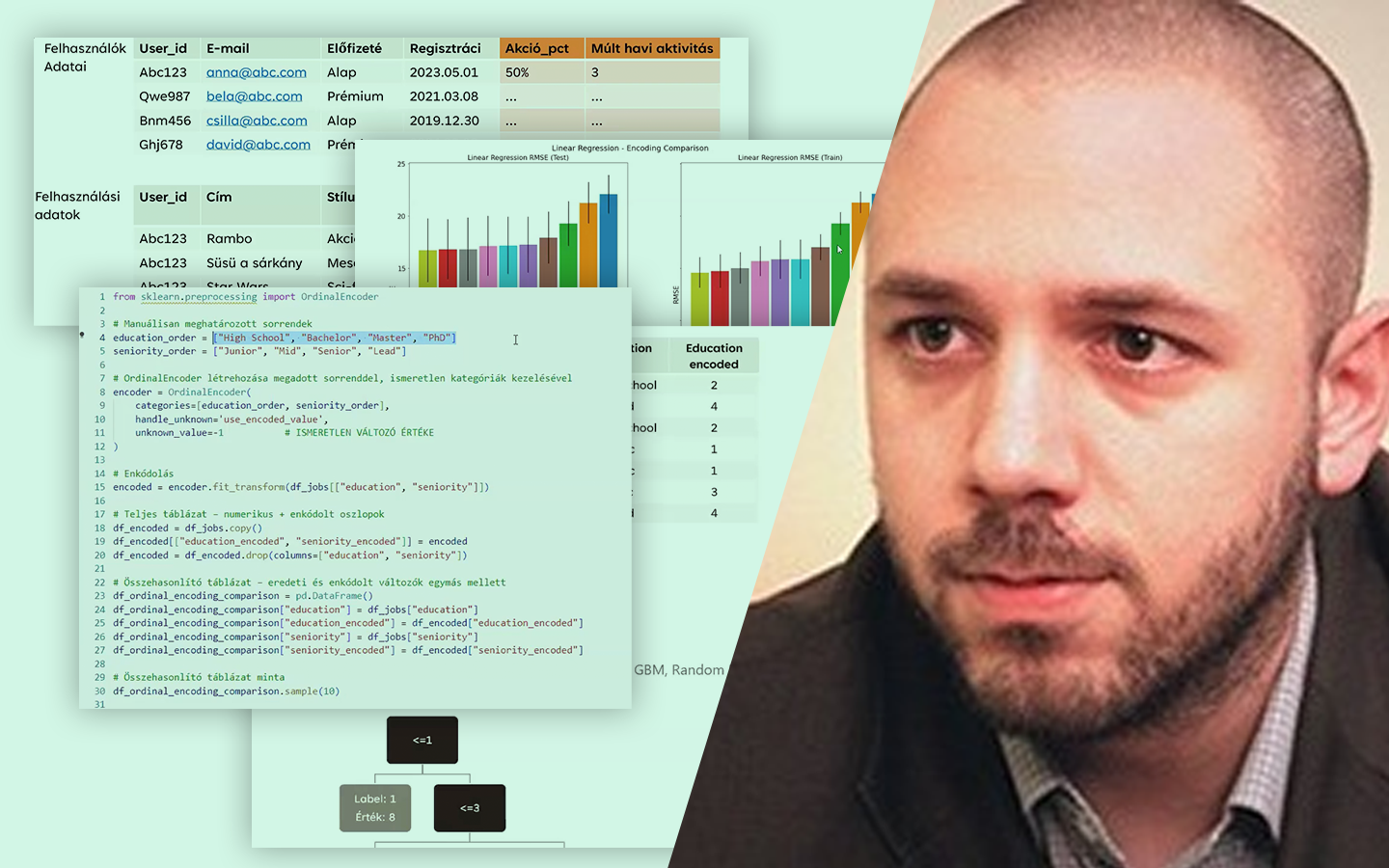
- Alapfogalmak tisztázása: mi a feature/jellemző, és mit jelent a feature engineering a gyakorlatban (származtatott változók létrehozása nyers adatokból).
- A feature engineering két fő célja: (1) az adat „modell-kompatibilissé” tétele (pl. numerikus forma), (2) a nehezen tanulható információk kiemelése, amelyeket a modell önmagától nem biztos, hogy megtalál.
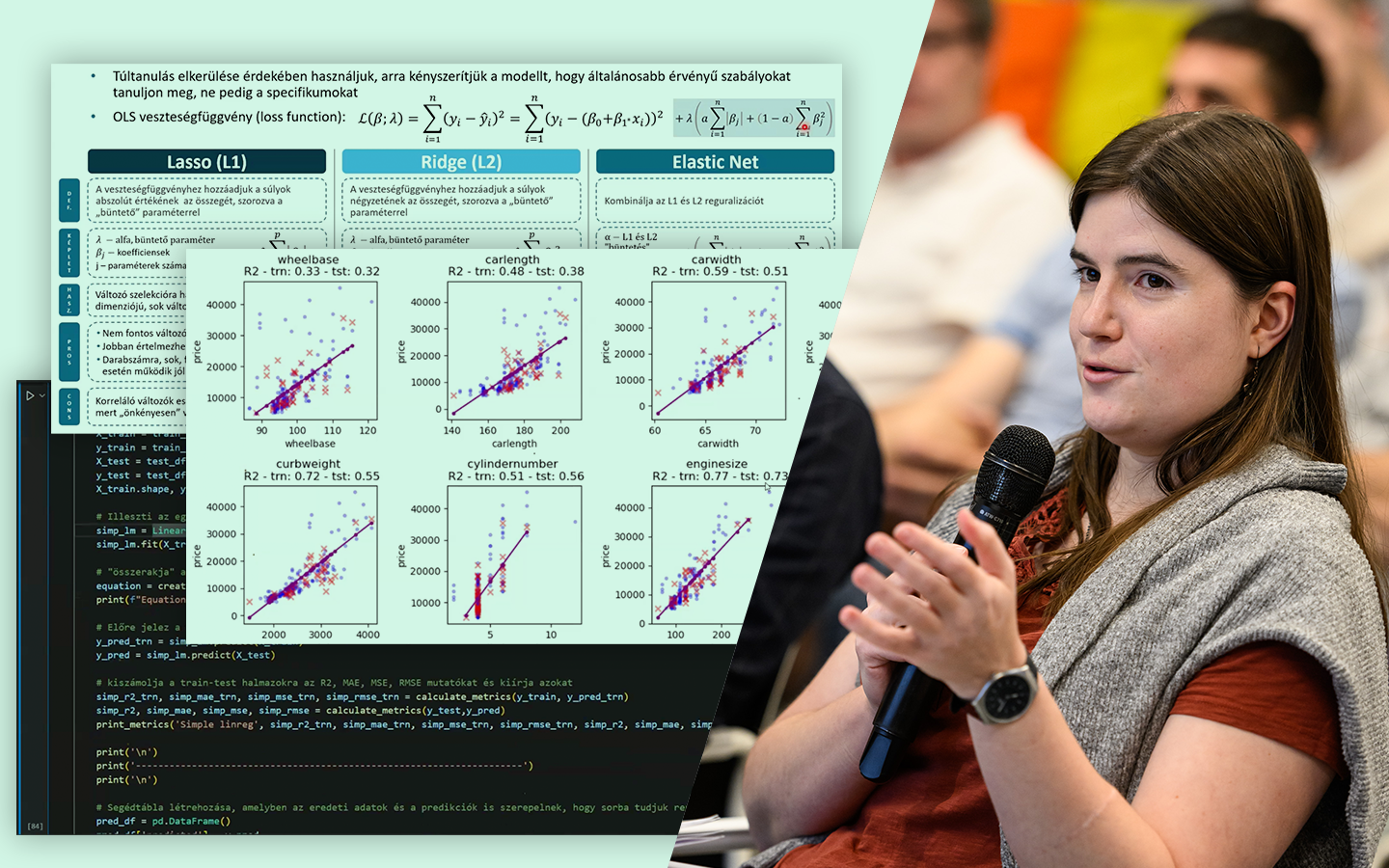
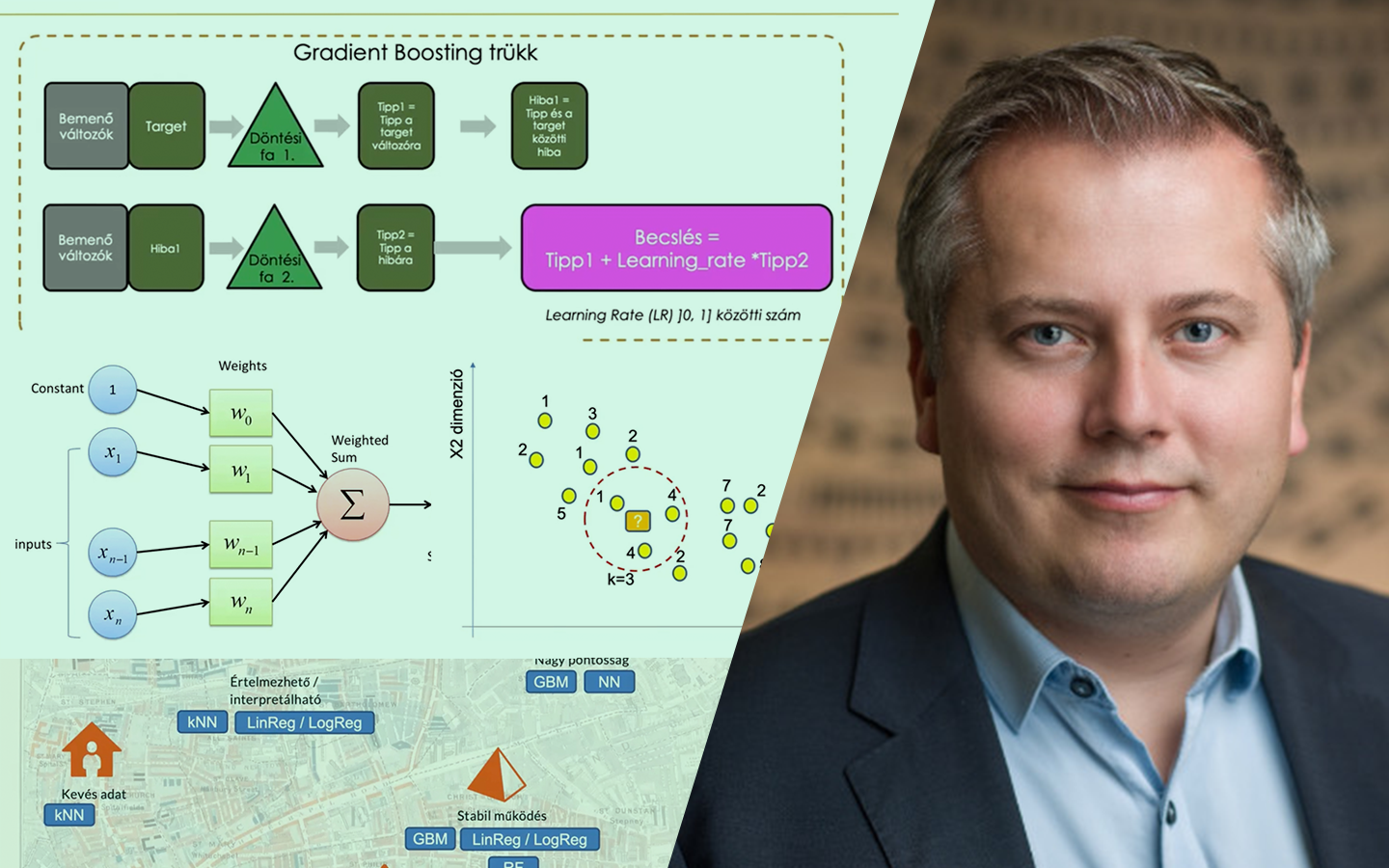
- Modellek megértése a jobb jellemzőkért: intuitív összehasonlítás lineáris regresszió, döntési fa és érintőlegesen neurális háló között – mikor melyik mire képes, és ez mit jelent a jellemzők tervezésében.
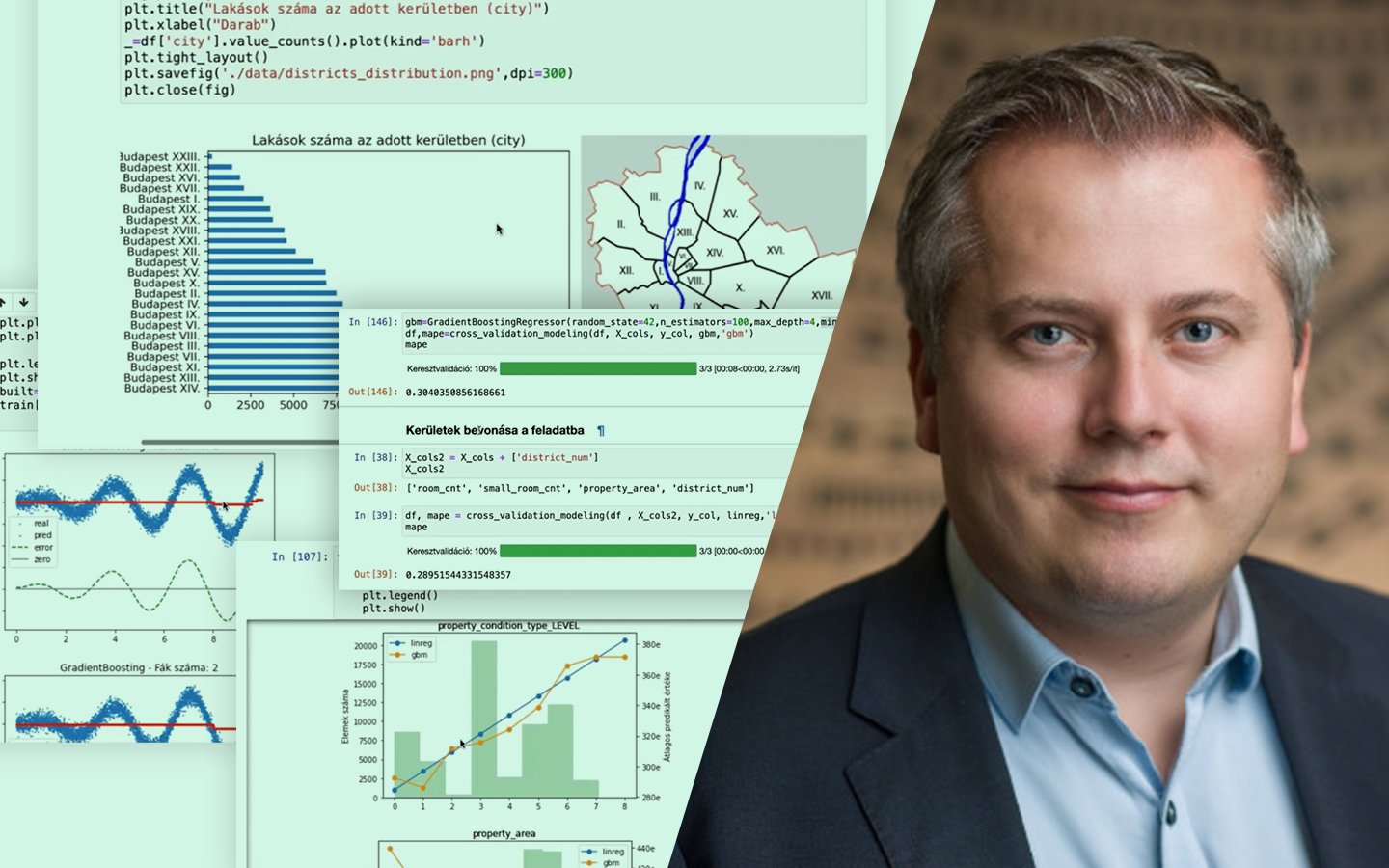
- Nemlinearitások kezelése: logaritmikus és más transzformációk, illetve hogyan kezeli natívan a döntési fa a bonyolultabb görbéket (pl. autó MPG példa).
- Időciklusok és csúcsidők modellezése: csúcsidős dummy-k, one-hot kódolás órák szerint, majd Fourier / szinusz-koszinusz transzformációk – robusztusság vs. értelmezhetőség trade-off.
- Két változó kapcsolatának kifejezése: arányok, összegek/különbségek, interakciók (szorzat) – mikor érdemes ezeket kiszámolni (pl. hitelkockázat, marketing költés, csibék növekedése).
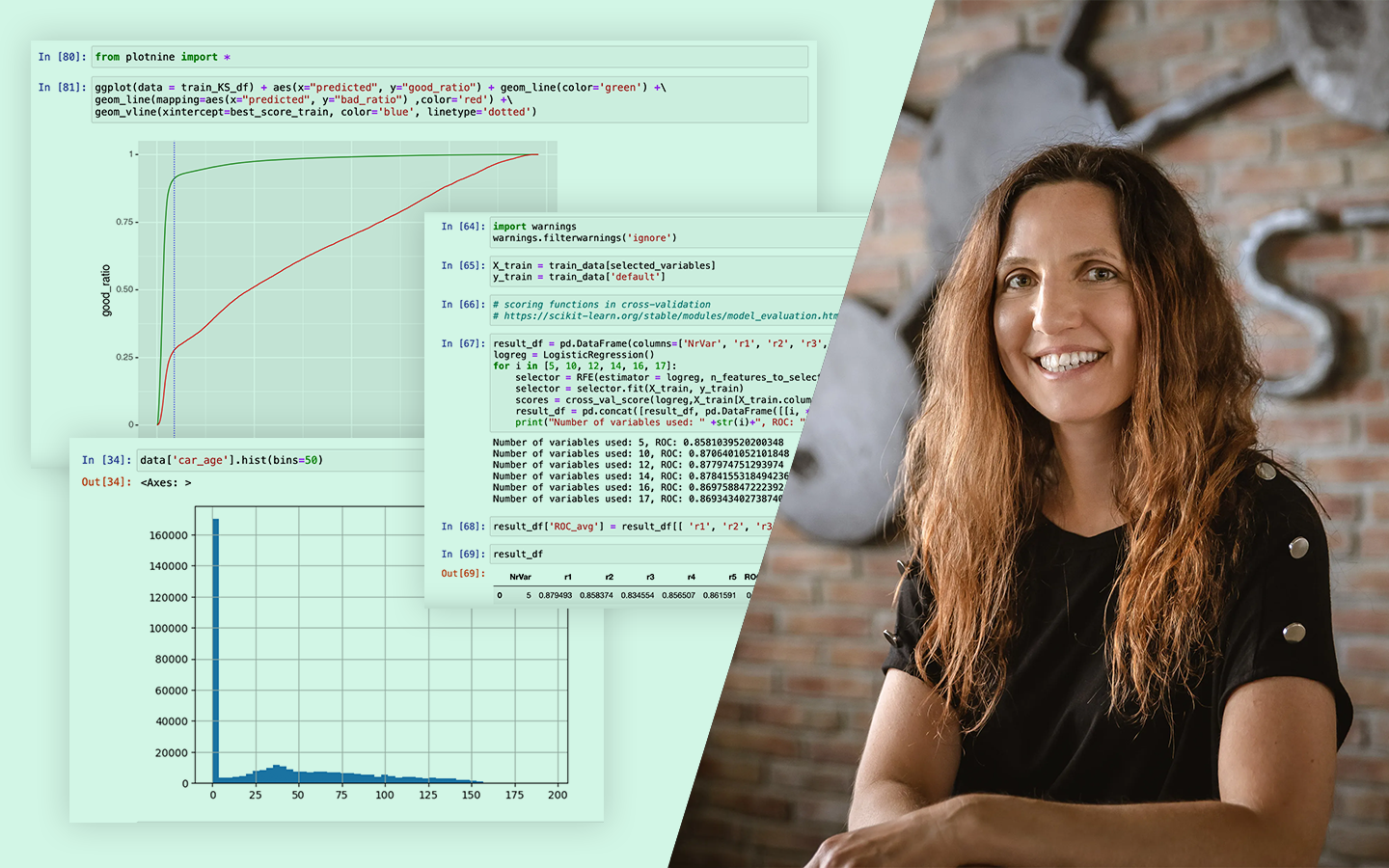
- Aggregációk mint „aranybánya”: user-szintű összegzések (darabszám, átlag, szórás, recency), és miért kell erre külön figyelni, például az adatszivárgás elkerülése miatt.