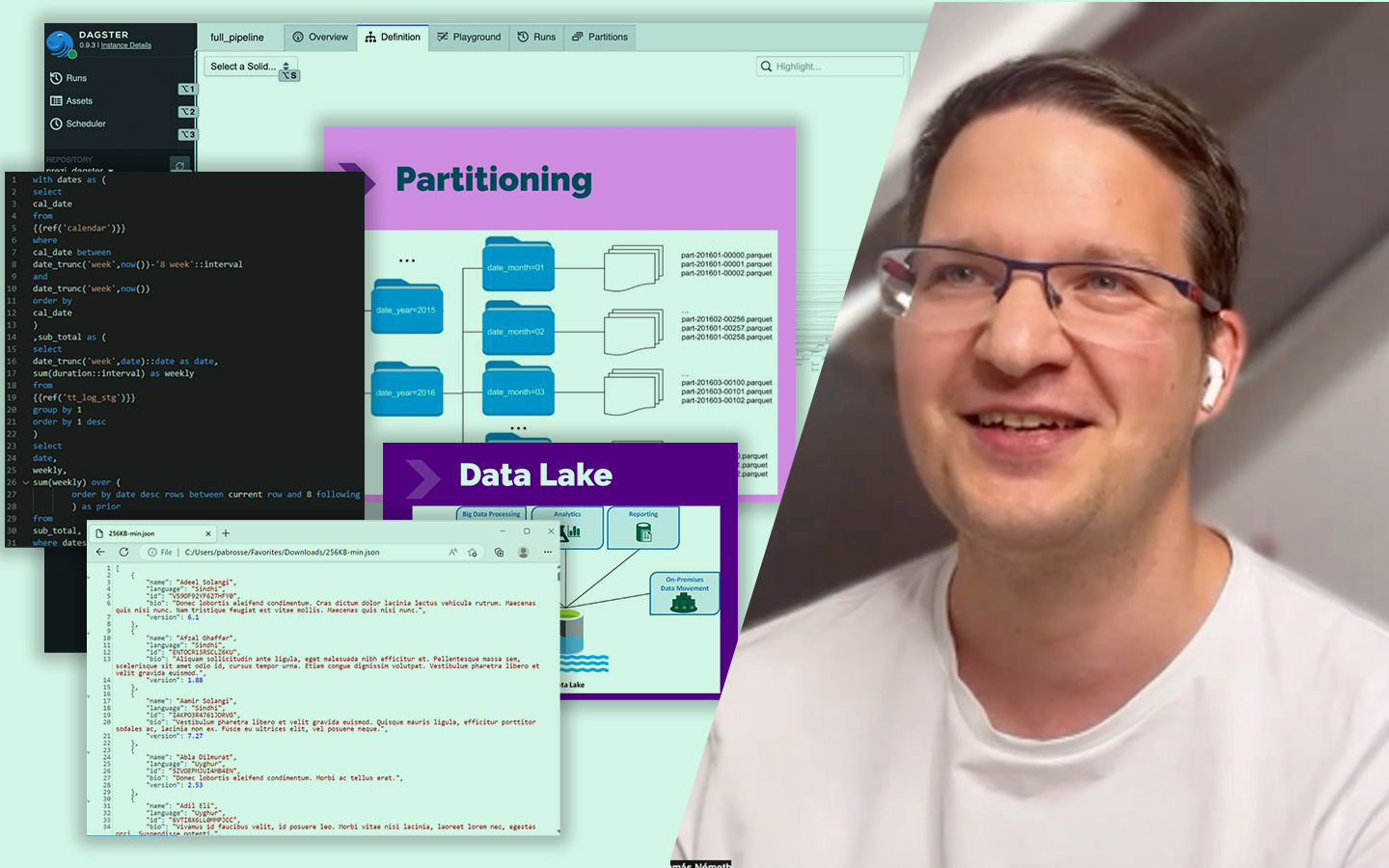
A „Data Engineering Elmagyarázva” előadásban Németh Tamás (ex-Prezi, Acryl Data) közérthetően mutatja meg, mi történik a láthatatlan háttérben, mielőtt egy riport, dashboard, elemzés vagy modell egyáltalán megbízhatóan működhet. Lépésről lépésre megérted, miért nem skálázódik a „rákérdezünk a production adatbázisra” megközelítés, hogyan jut el egy cég a skálázhatóbb dataplatformig, és miért lesz ettől gyorsabb, biztonságosabb és stabilabb az adatelemzés. Áttekintést kapsz a data lake és data warehouse alapjairól, az adattárolási döntések hatásáról, valamint az ütemezés, függőségek és a data catalogok szerepéről is, hogy kevesebb hibával és tisztább felelősségekkel tudj adatokkal dolgozni.
Milyen főbb témákról van szó az előadásban?
- A data engineering szerepe a gyakorlatban: a „konyhai” analógián keresztül, miért az adatok előkészítésének minősége határozza meg a végeredményt (riport, dashboard, elemzés).
- Hogyan nő ki egy dataplatform egy cégben: a közvetlen production lekérdezéstől a skálázhatóbb megoldásokig, és miért veszélyes vagy korlátos a production adatbázisra építeni (outage-kockázat, skálázódási gondok, historikus adatok hiánya).
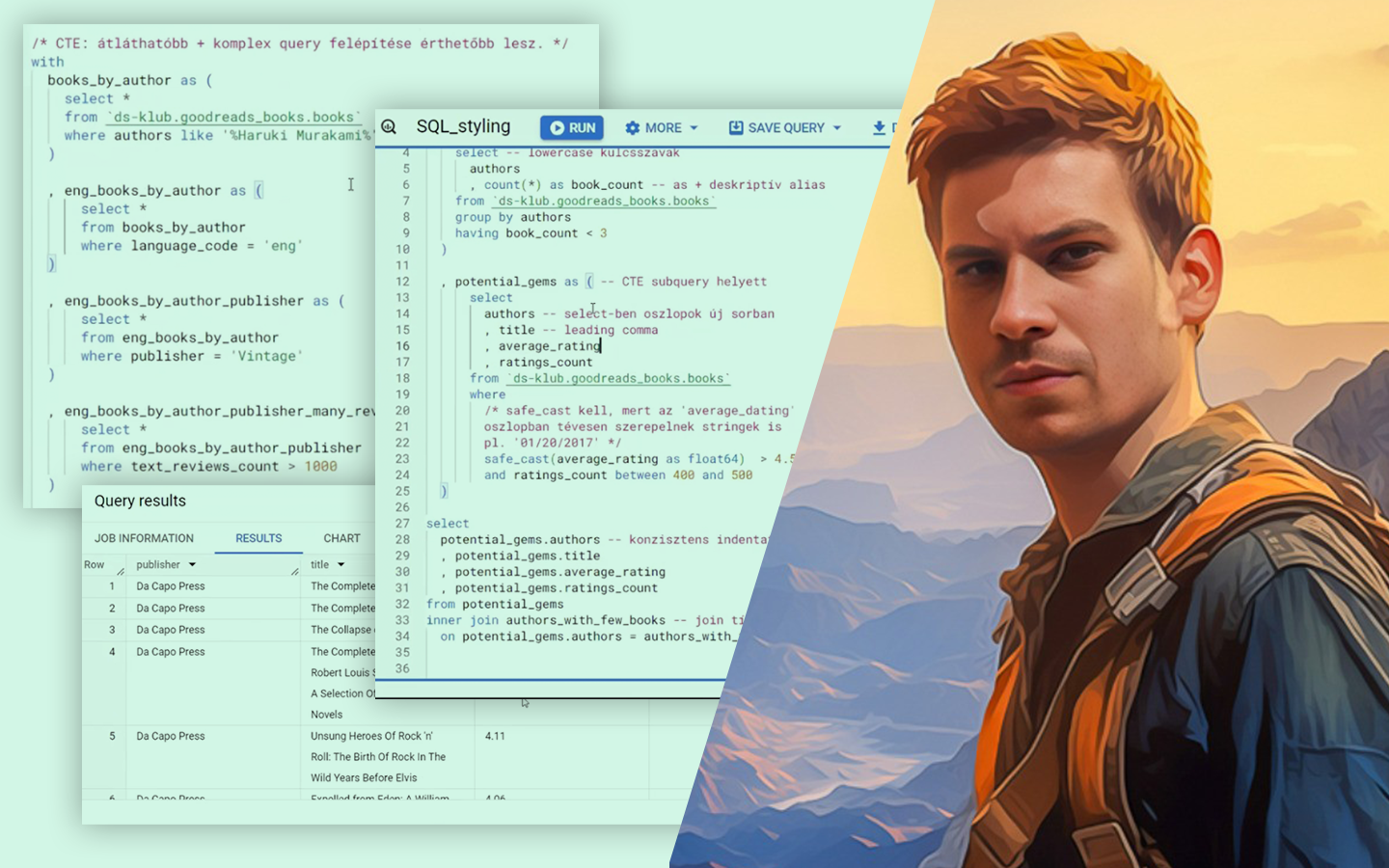
- Data lake és adattárolási alapok: formátumok összevetése (log/CSV/JSON vs. Parquet/ORC), és hogy ez miért számít teljesítményben, sémakezelésben és feldolgozhatóságban.
- Gyakori ingestion problémák és megoldások: partícionálás, deduplikáció, kompaktálás, valamint data quality szempontok (validitás, teljesség, időszerűség) – tipikus hibák, amelyek rossz riportokhoz vezetnek.
- Data warehouse és modellezés: miben más egy analitikus adatbázis (pl. Redshift/BigQuery/Snowflake), hogyan lesz a nyers adatokból dashboard-barát táblastruktúra, és miért fontosak a konvenciók.
- Orchestration és adatkatalógus: miért kell ütemezés és függőségkezelés (pl. Airflow/DBT), és hogyan segít egy data catalog abban, hogy tudd, hol van az adat, kié, miből jön, és mit érint, ha változik.