A „Feature Engineering elmagyarázva (gyakorlati példákkal)” előadásból megtudod, hogyan lesz a nyers adatokból olyan bemenet, amivel a modellek valóban jól tudnak dolgozni, különösen a kategorikus (szöveges) változók esetén. Radó László (Lead Data Scientist, BT) érthetően végigveszi a feature engineering szerepét a modellezésben, majd Jupyter Notebookos példákon mutatja be a leggyakoribb kódolási és átalakítási módszereket. Közben nemcsak az előnyökre és hátrányokra tér ki, hanem a projektekben tipikusan előjövő buktatókra is, például az ismeretlen kategóriák kezelésére, a dimenziónövekedésre, az overfittingre és az adatszivárgás elkerülésére. A példák Pythonban, valószerű adatokon futnak, a kódbázist pedig az előadás után megkapod.
Milyen főbb témákról van szó az előadásban?
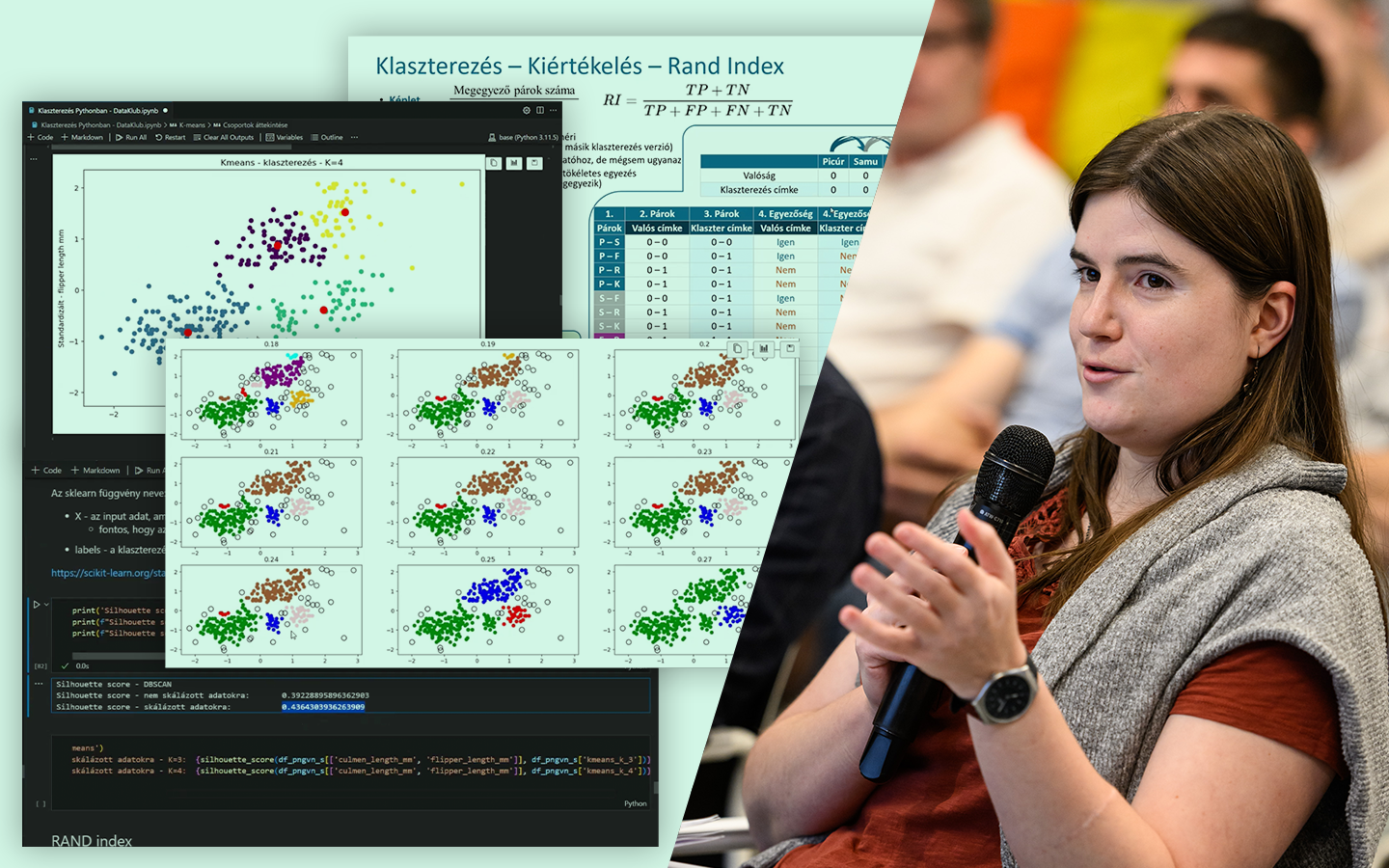
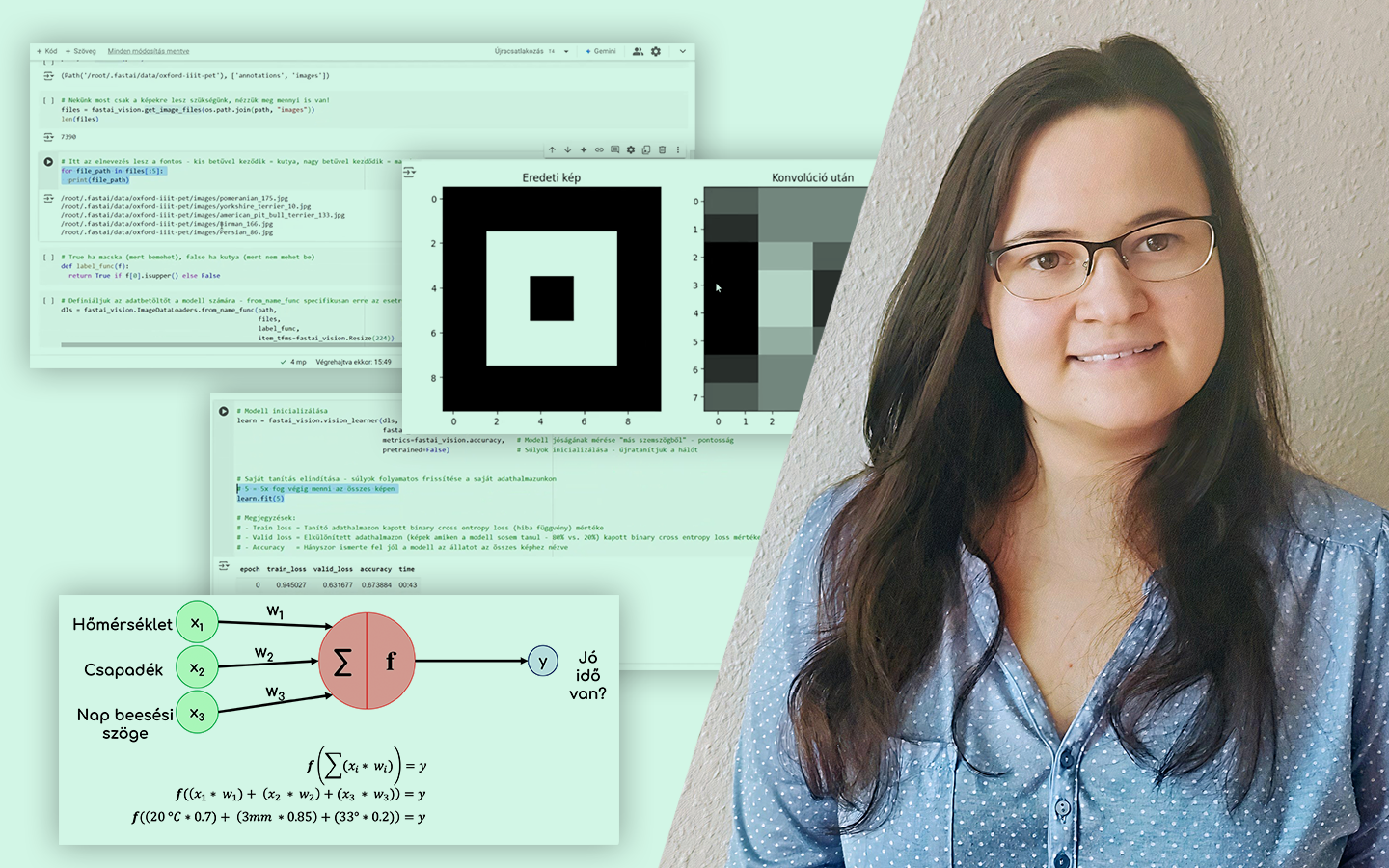
- Mit jelent a „feature” és a „feature engineering” a modellezésben? Rövid, tiszta definíciók és a szerepük: mikor elég egy nyers oszlop, és mikor érdemes vagy szükséges új változókat képezni.
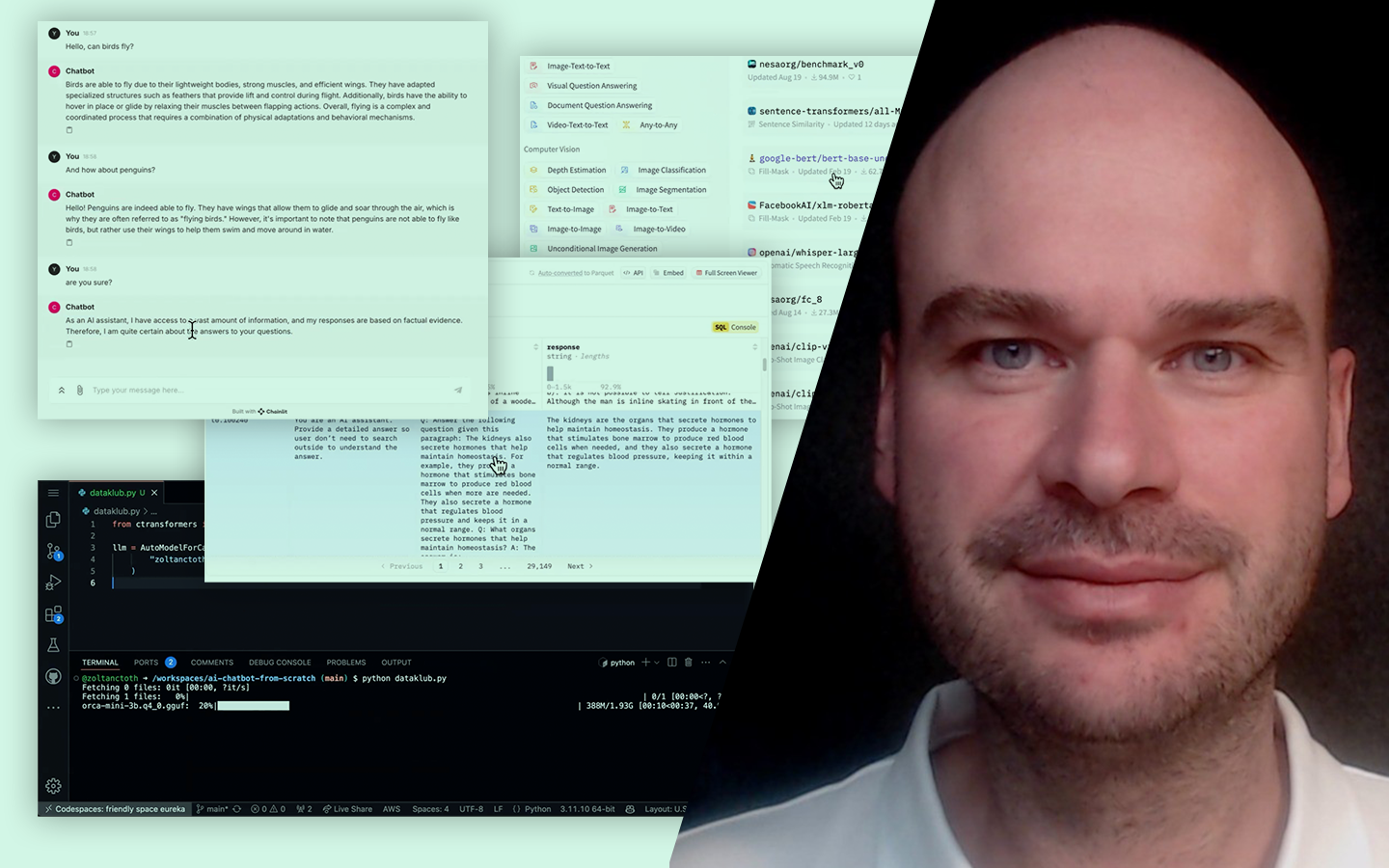
- Miért nem „csak adatelőkészítés”? Fontos különbségtétel: nem pusztán hiányzó értékek pótlásáról vagy adattisztításról van szó, hanem arról, hogyan tesszük az adatot a modell számára értelmezhetővé és hasznossá.
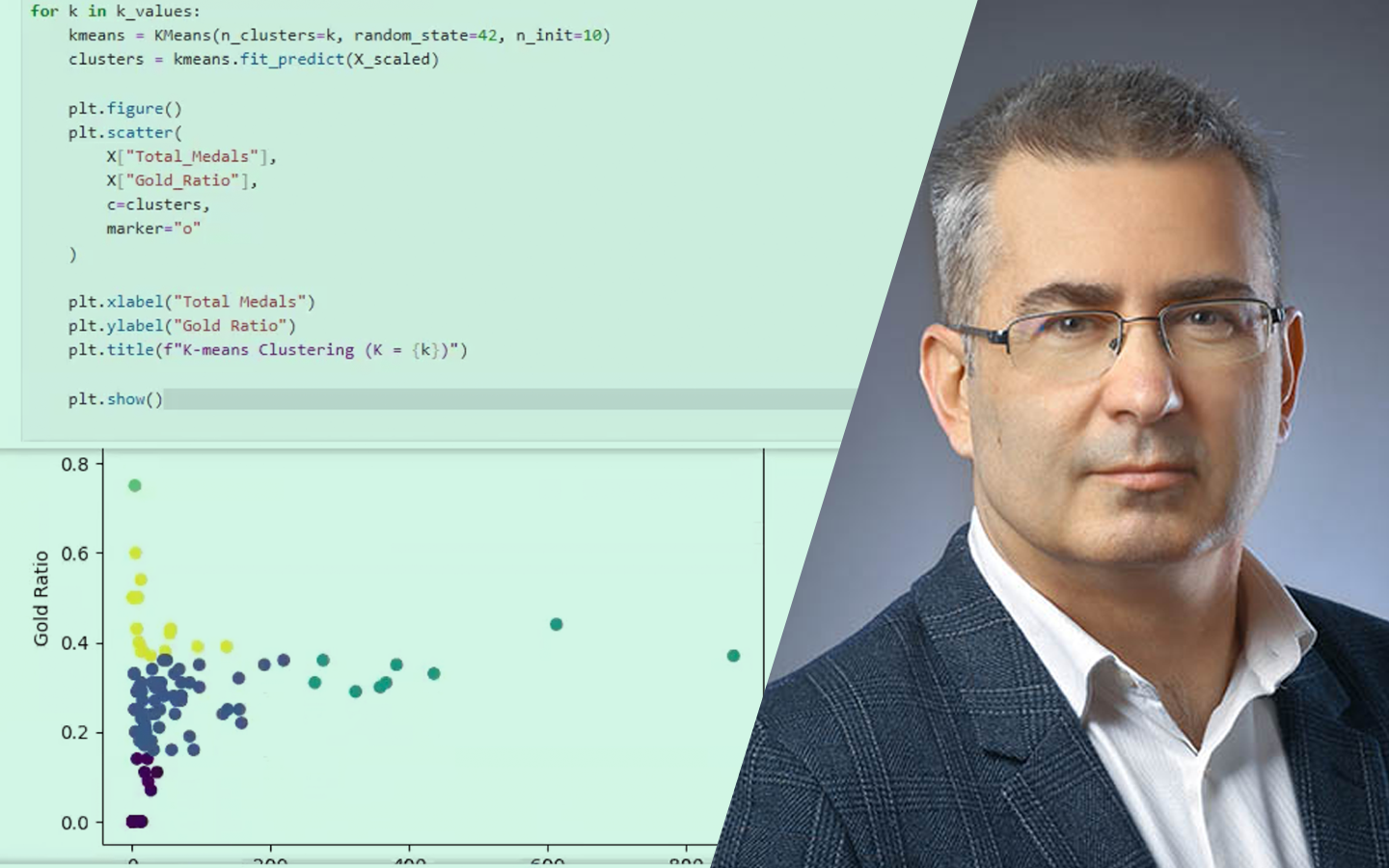
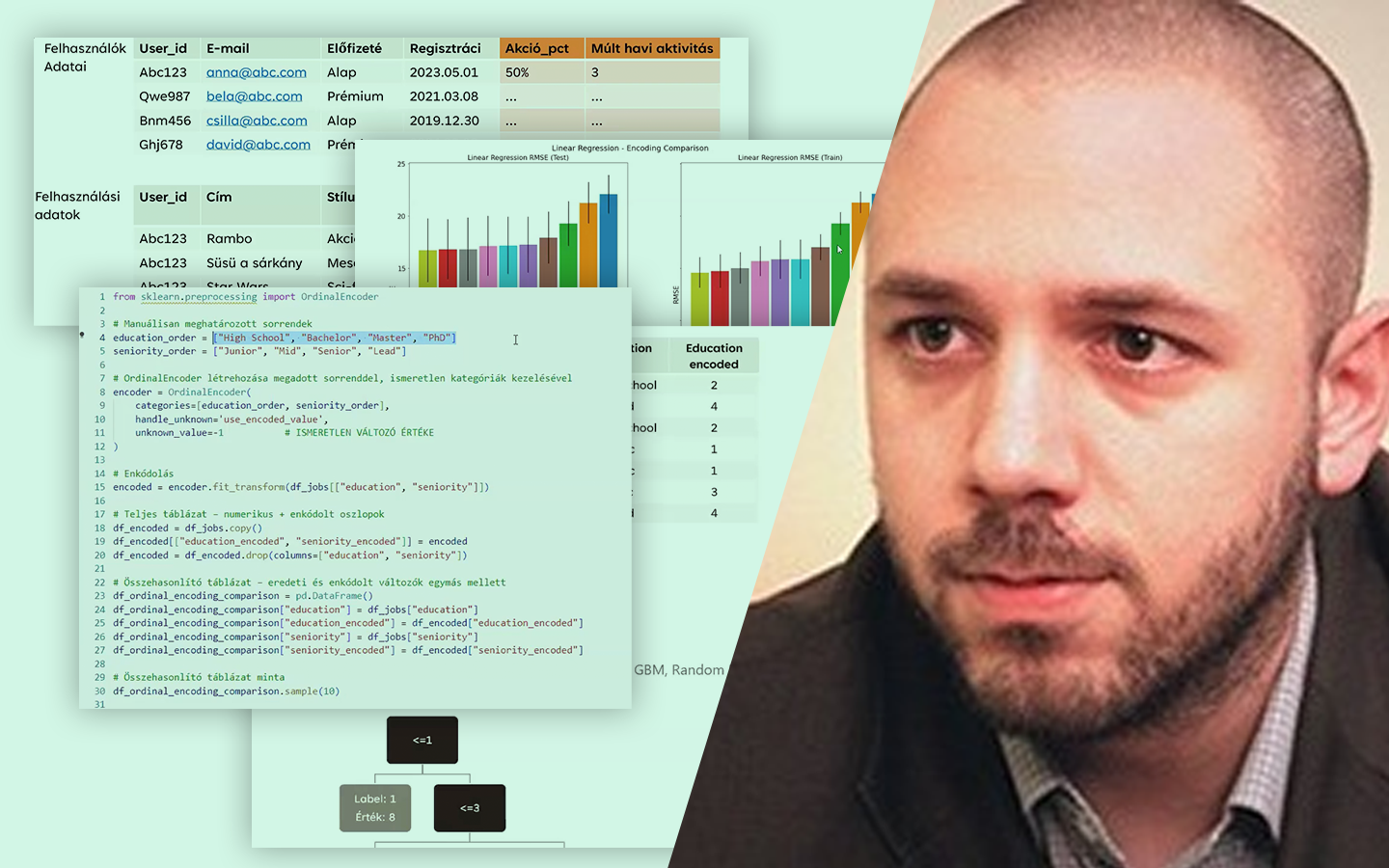
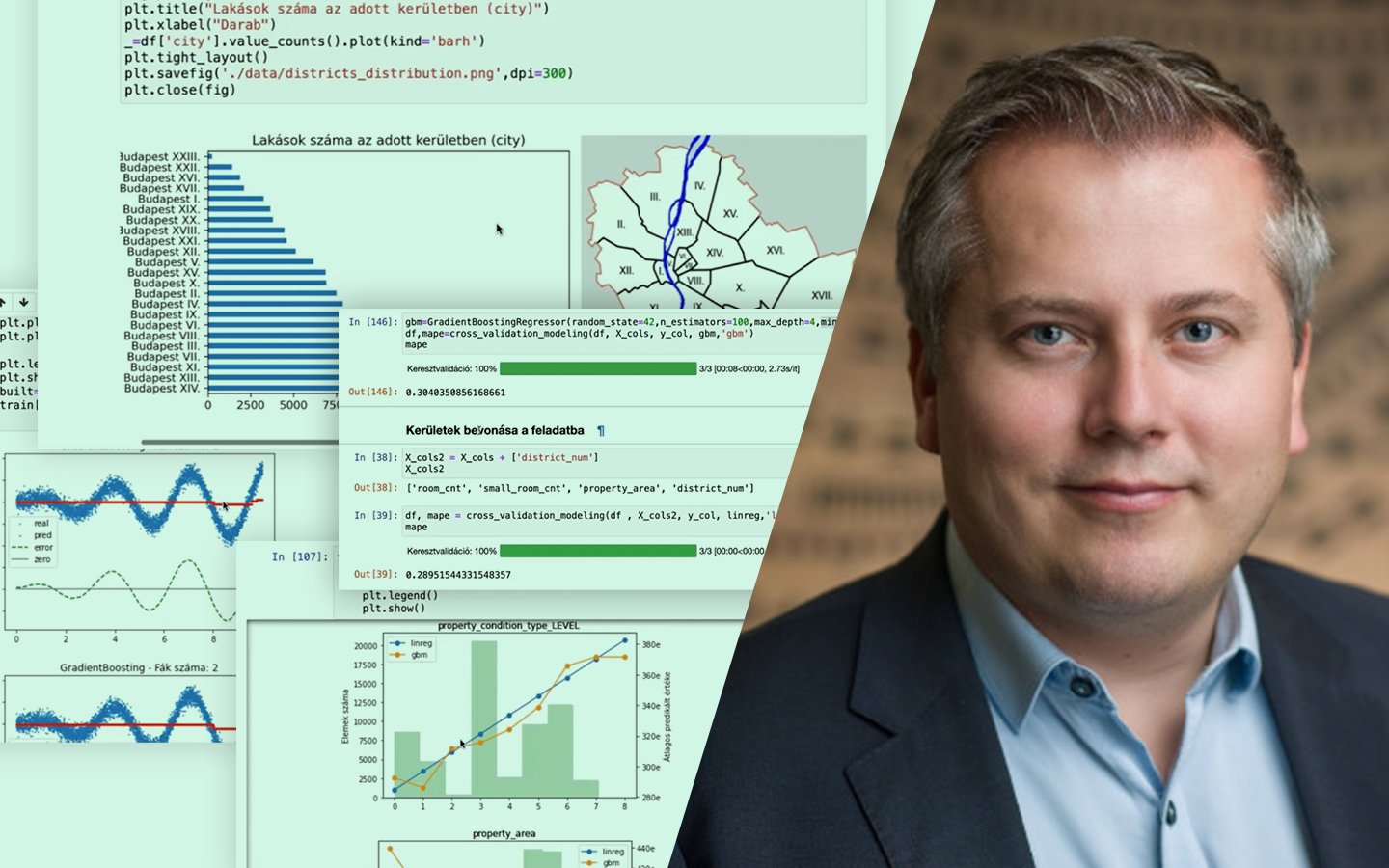
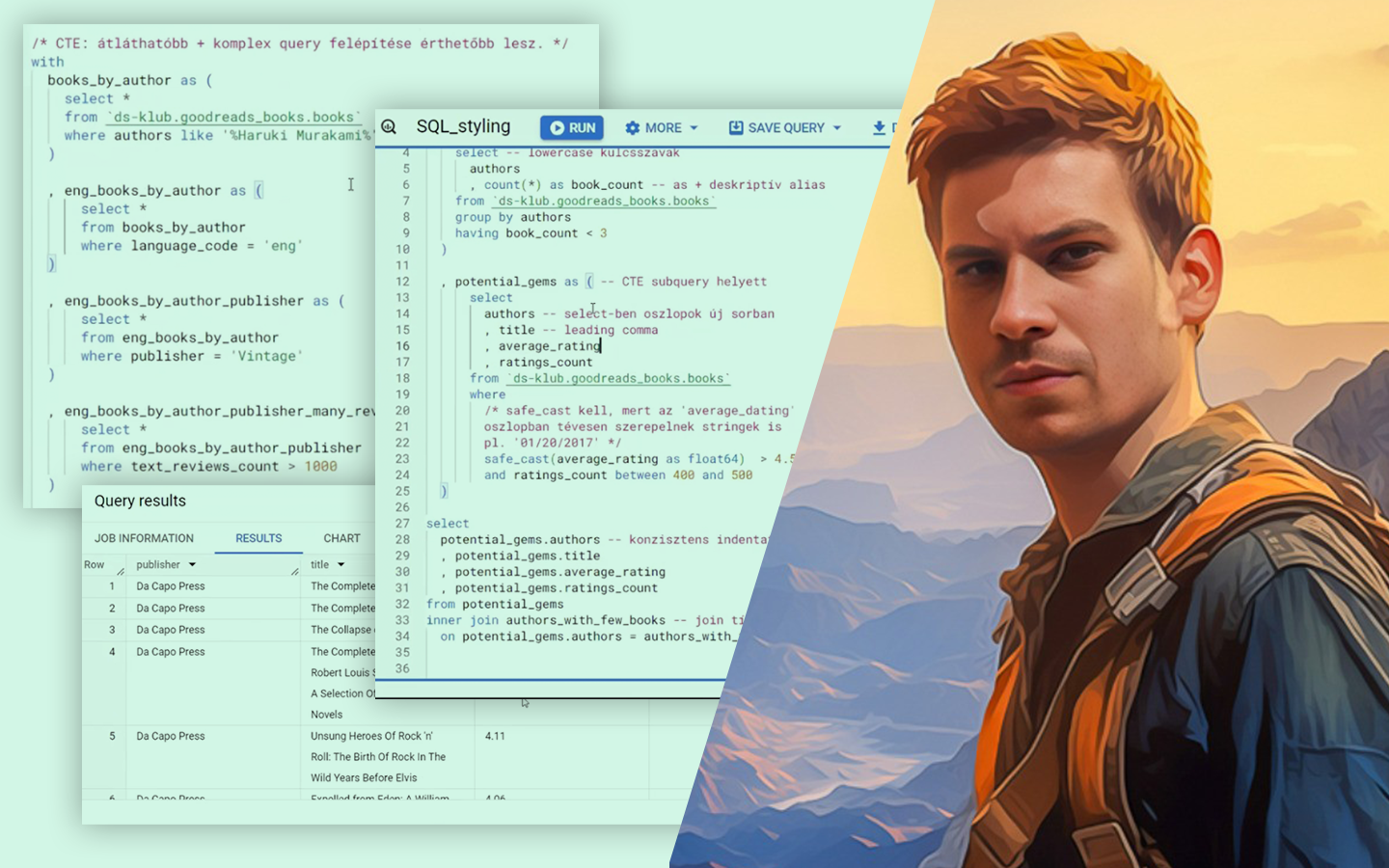
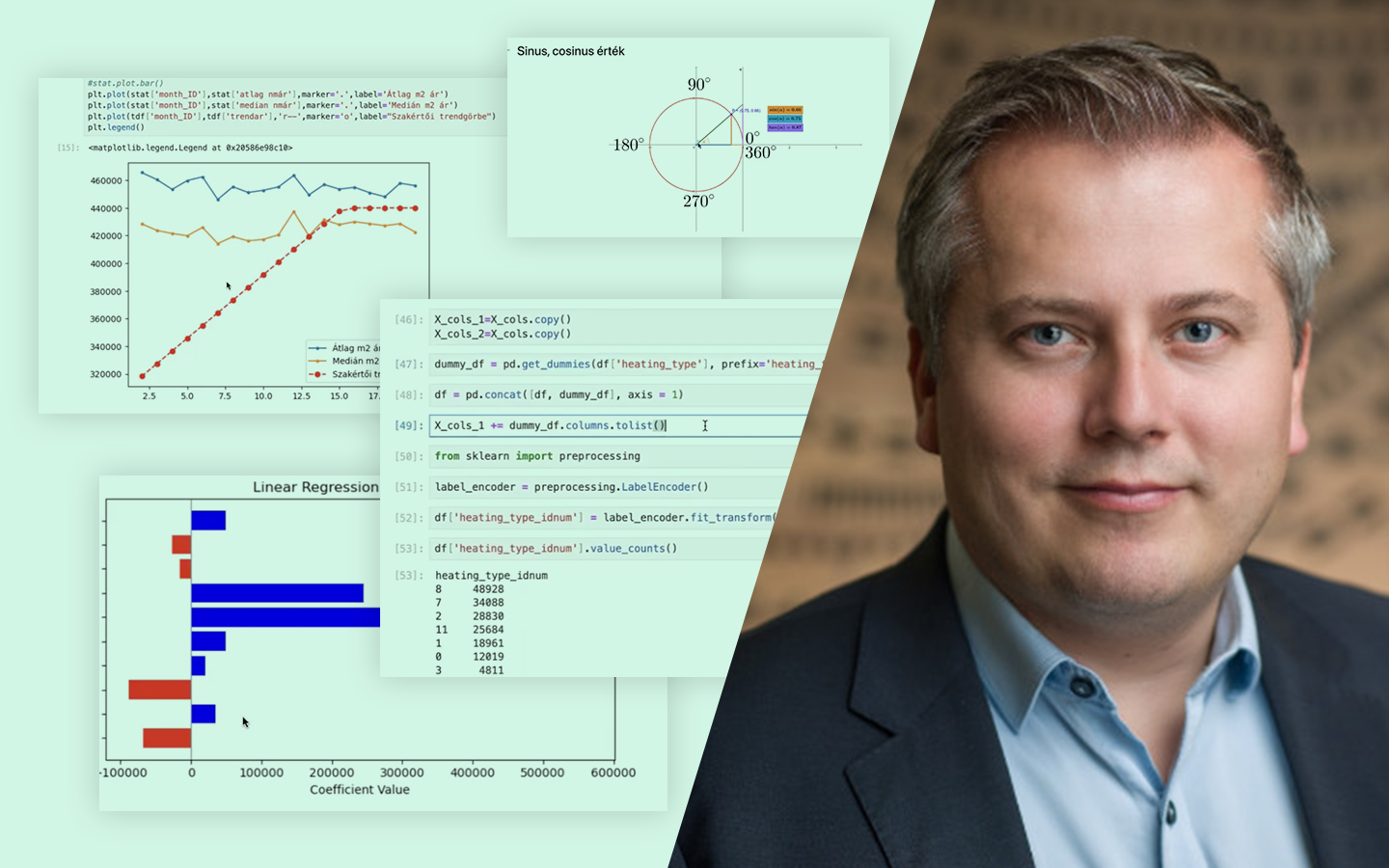
- Kategorikus változók kódolása Jupyter Notebookban: label encoding, ordinal encoding, one-hot encoding, quantile binning (két megközelítés), target encoding.
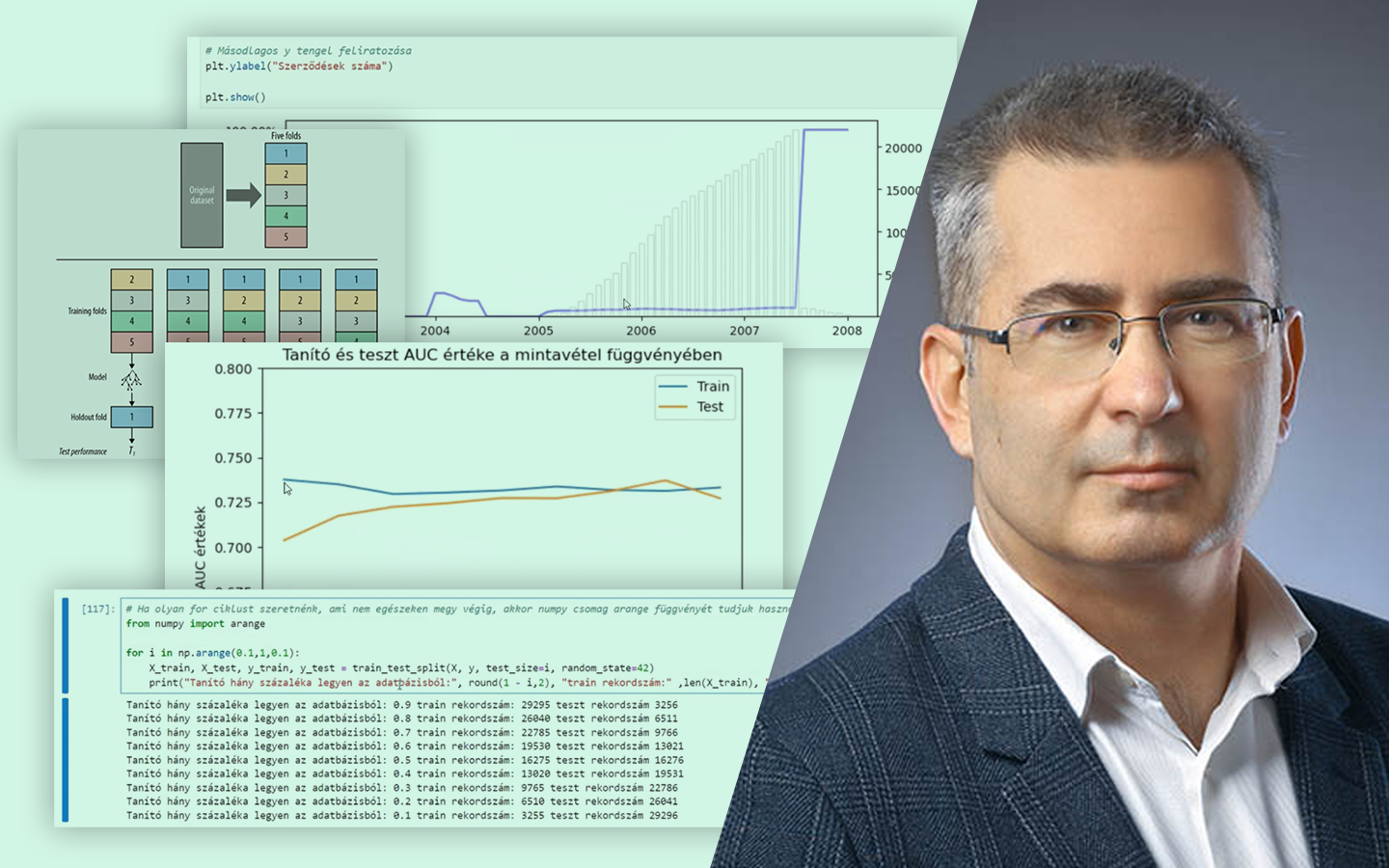
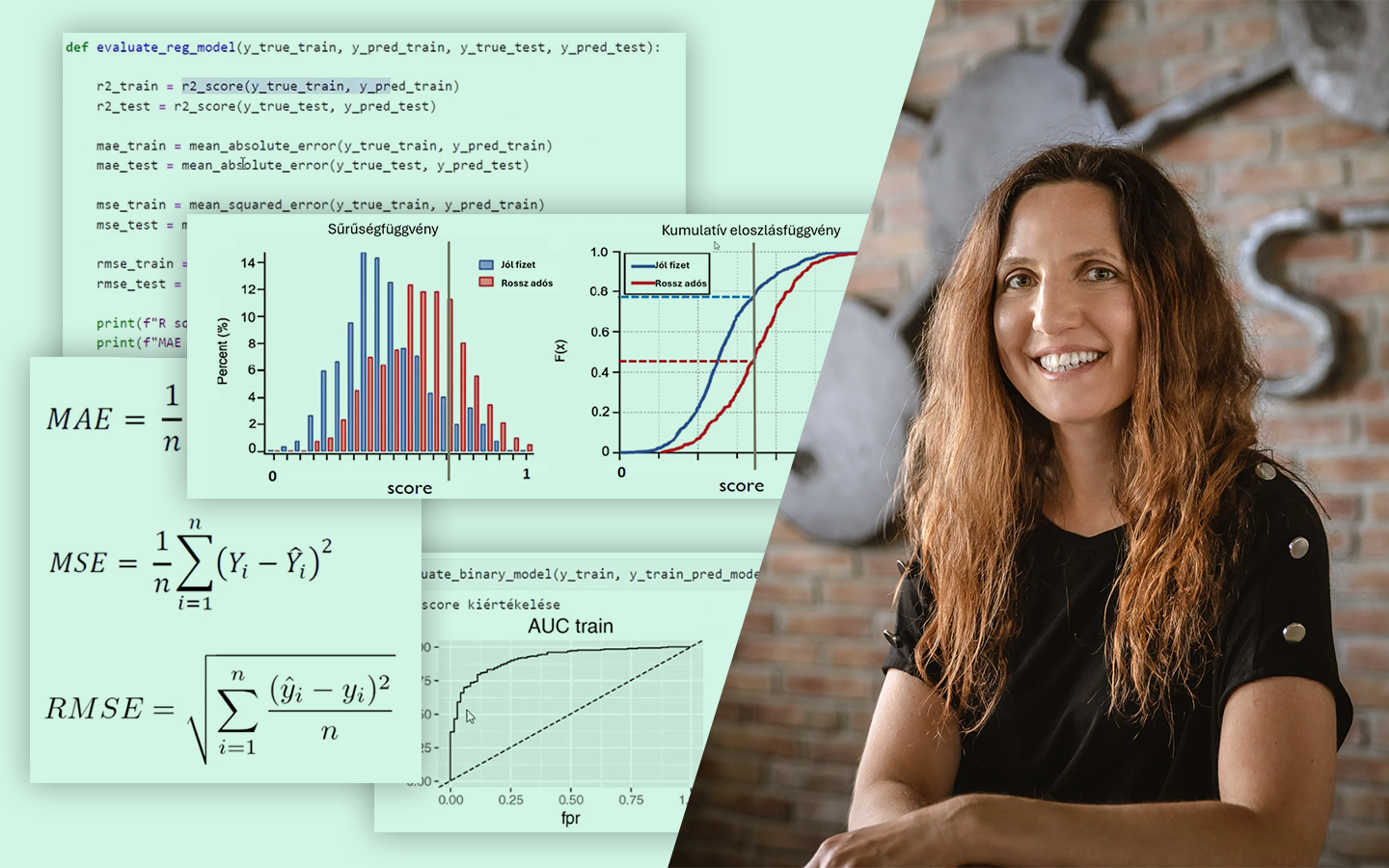
- Gyakorlati döntési szempontok, amik projektekben tényleg számítanak: dimenziónövekedés sok kategória esetén, ismeretlen kategóriák kezelése, modellkompatibilitás (lineáris modellek vs. döntési fák), overfitting és adatszivárgás, valamint ezek elkerülésének alapelvei.