Ha már építettél modelleket tananyagból, de szeretnéd látni, hogyan néz ki mindez egy valódi, üzleti célhoz kötött folyamatban, ez az előadás neked szól. A „Logisztikus Regresszió Python-ban egy Valós Projektből (Hitelbedőlés Vizsgálat Machine Learning-gel)” lépésről lépésre végigvezet egy banki hitelbedőlés-előrejelzési projekten Jupyter Notebookban. Megismered, hogyan kapcsolódnak össze az adatok, hogyan készülnek rolling window jellegű változók, miért kritikus az ügyfélszintű train–test szeparálás, és hogyan történik a modellértékelés (ROC, KS). Windhager Eszter (Head of Data Science, Starschema) azt is bemutatja, hogyan lesz a predikcióból kézzelfogható döntéstámogatás, például várható veszteség és céltartalék számítás.
Milyen főbb témákról van szó az előadásban?
- Valós banki use case és üzleti cél: hogyan lesz az adatokból használható, döntéstámogató modell, és miért fontos előre jelezni, hogy 6 hónapon belül bekövetkezik-e a default (5-ös státusz).
- Hitel-szkórkárd típusok: az applikációs és a viselkedési (behavior) szkórkárd közti különbségek, és ezek szerepe a banki döntésekben.
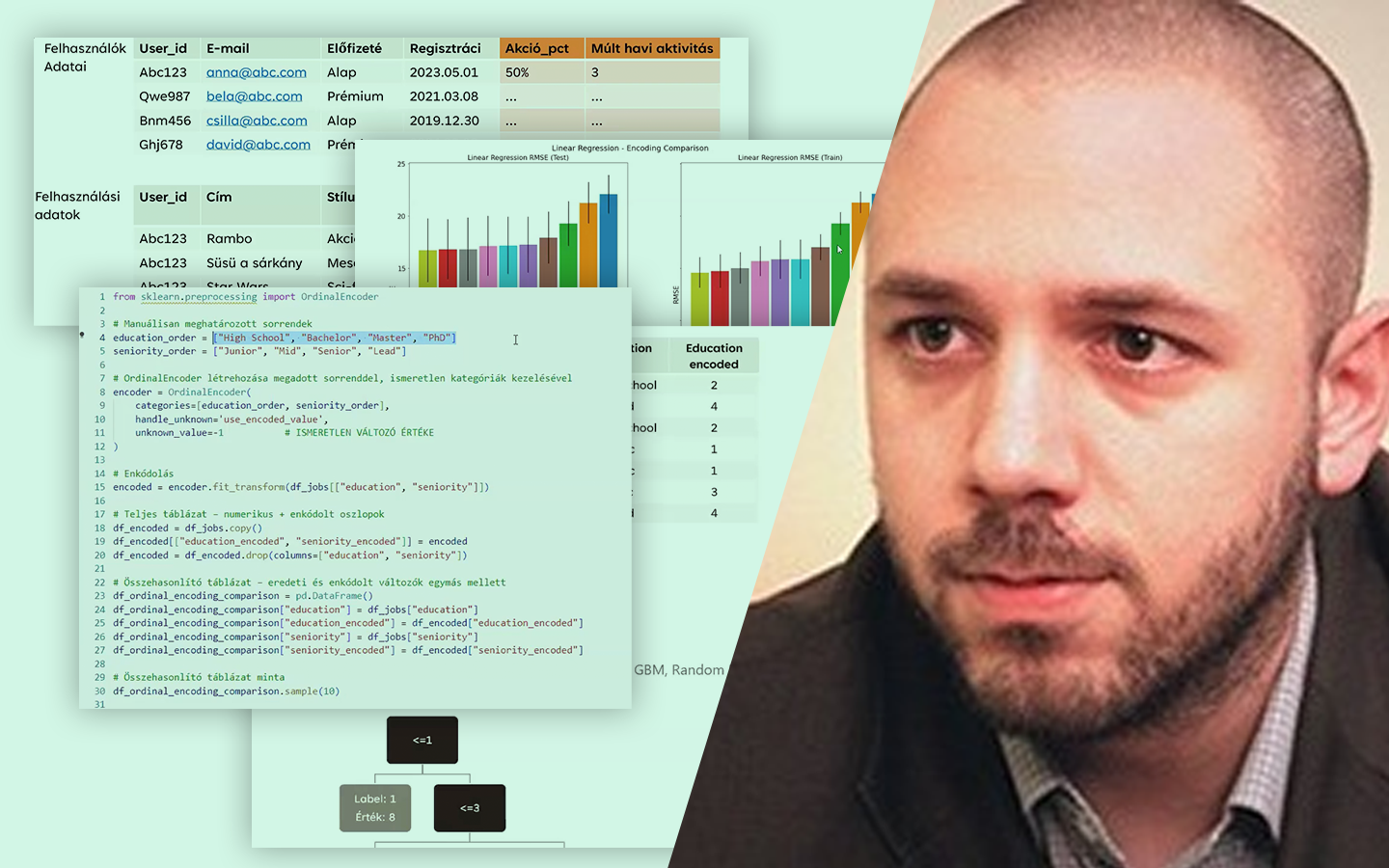
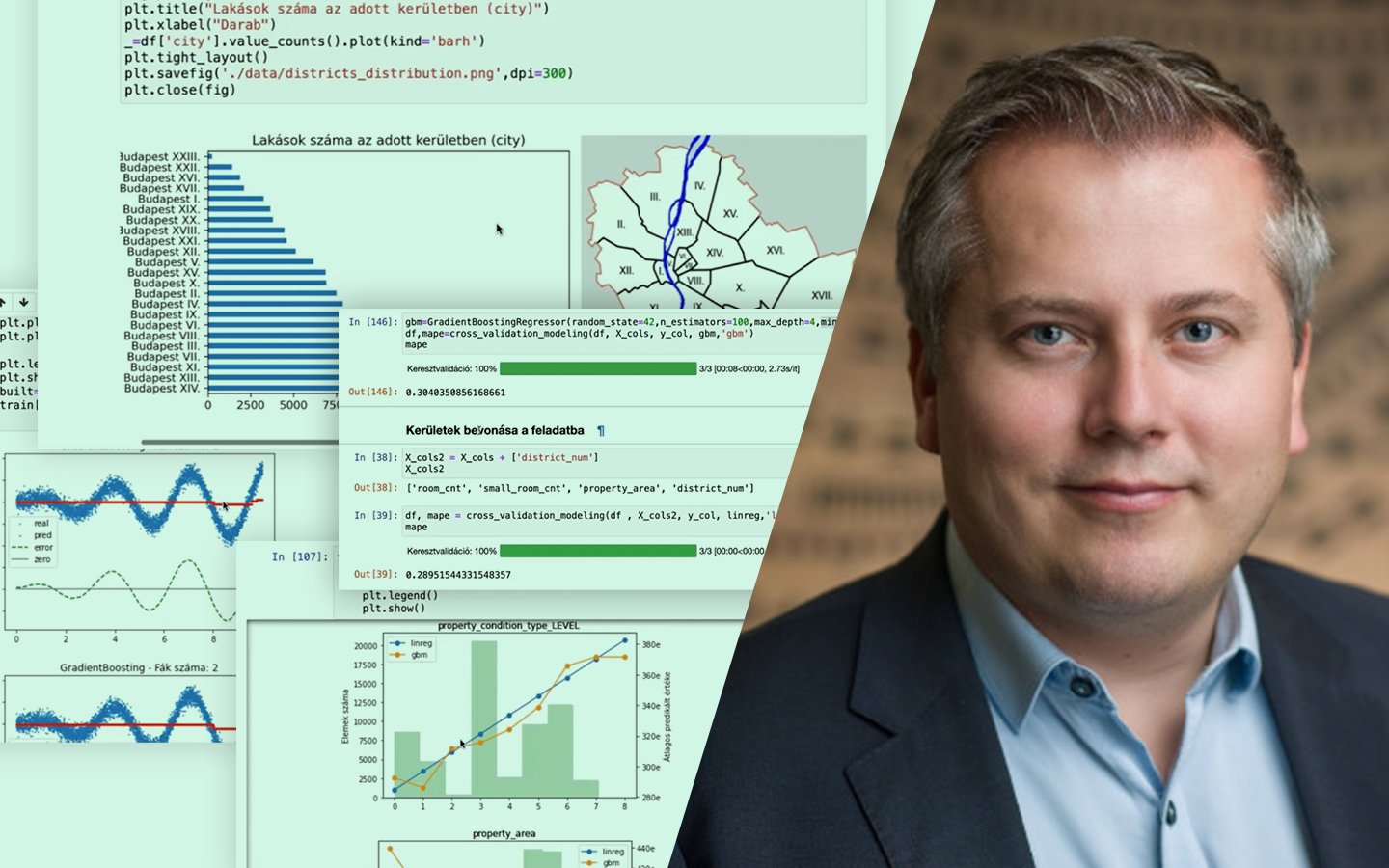
- Adatok felépítése és összekapcsolása: havi törlesztési idősorok (MaxDelay, 1–5 státusz) és ügyfél/ügylet jellemzők, például hitelösszeg, futamidő, fizetési mód, autó kora és márkája, lakóhely.
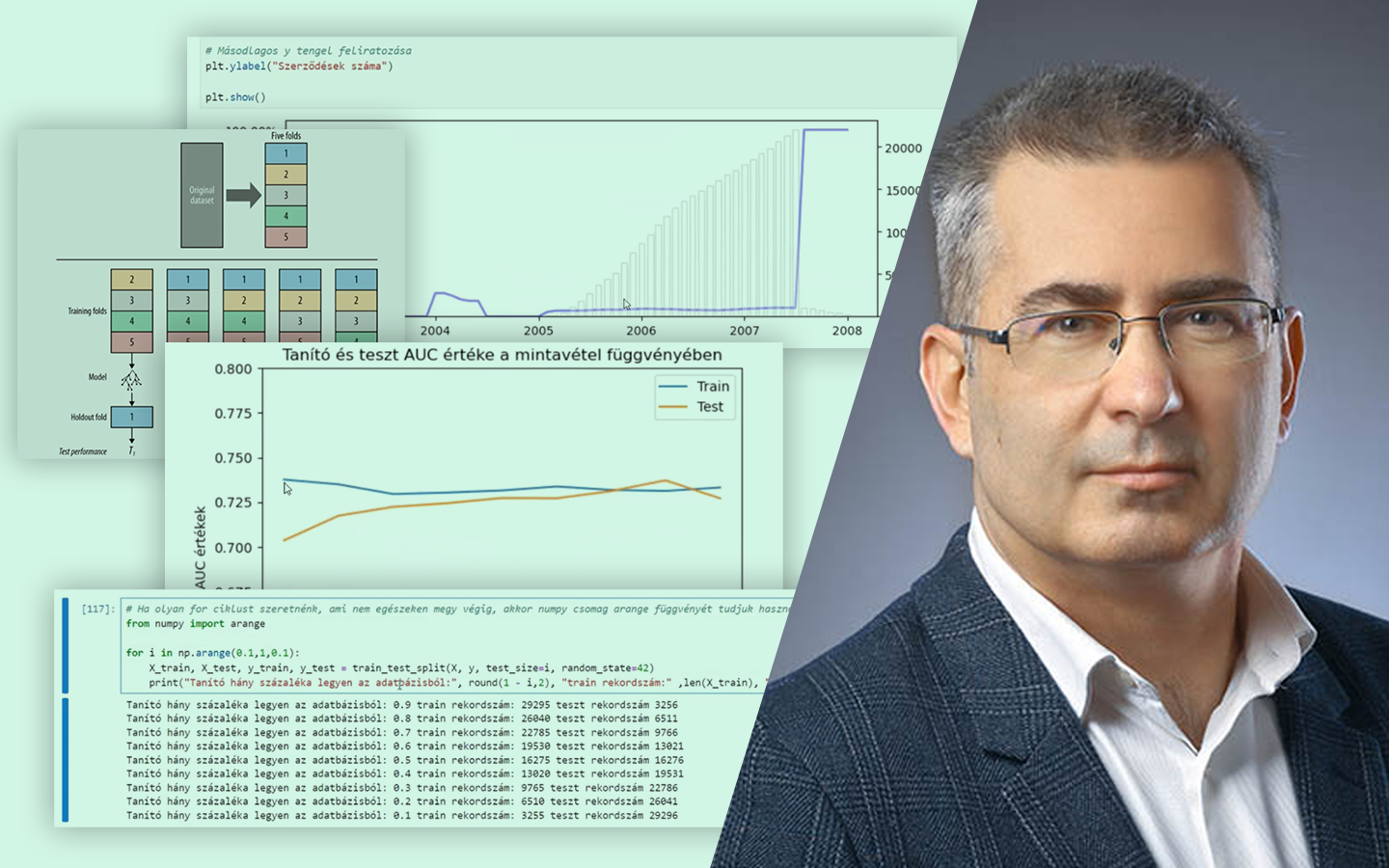
- Feature engineering rolling window statisztikákkal: az elmúlt 6 hónap viselkedéséből képzett változók (késések száma, átlag/max késedelem, max státusz), valamint a célváltozó előállítása a következő 6 hónap eseményeiből.
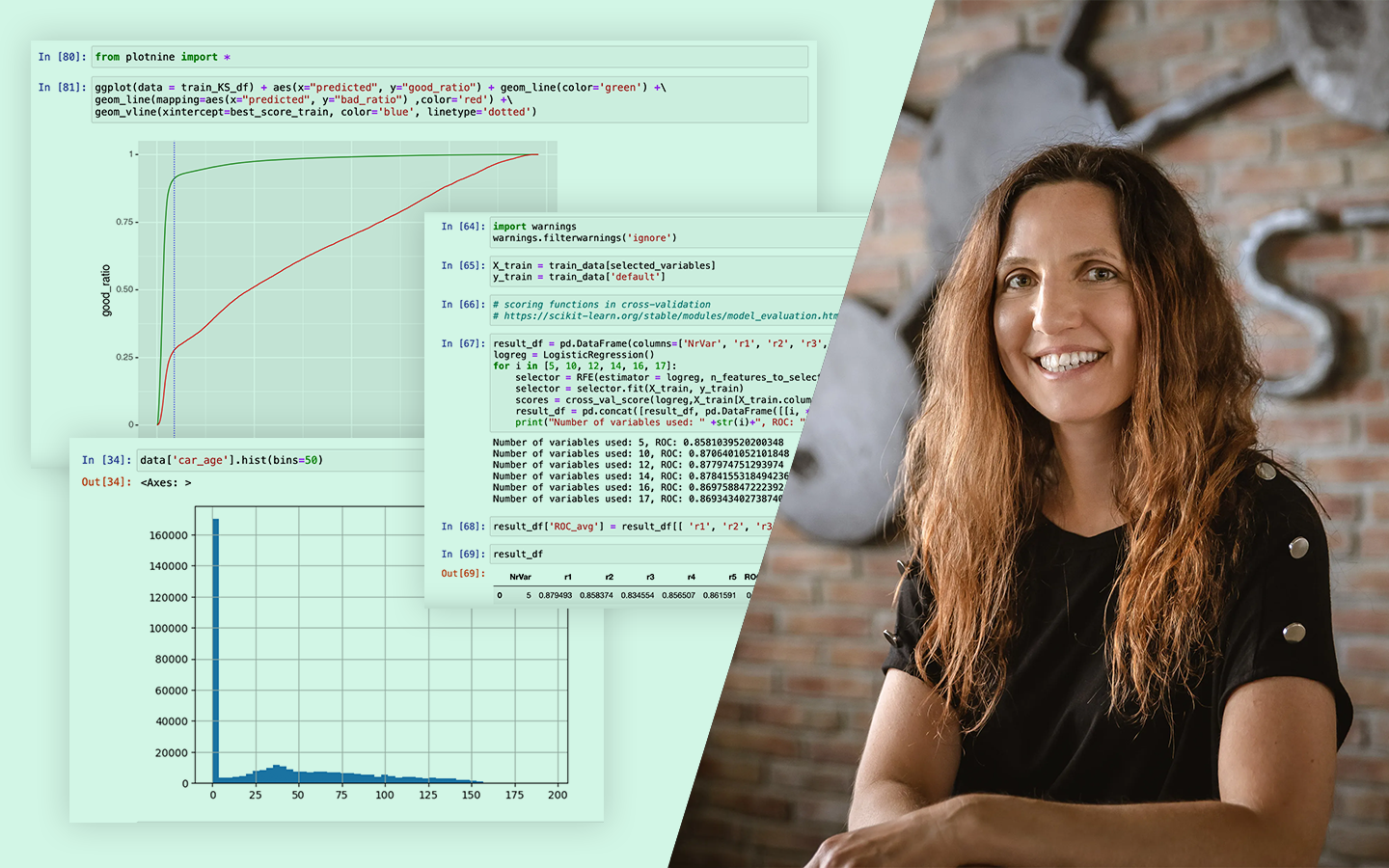
- Helyes train–test bontás ügyfélszinten: miért kell egy ügyfél összes rekordját egy halmazban tartani, hogy a kiértékelés ne legyen túl optimista.
- Kategóriák kezelése és változószelekció: dummy változók, autómárkák csoportosítása tréning adaton bedőlési arány alapján, majd feature-szűkítés.
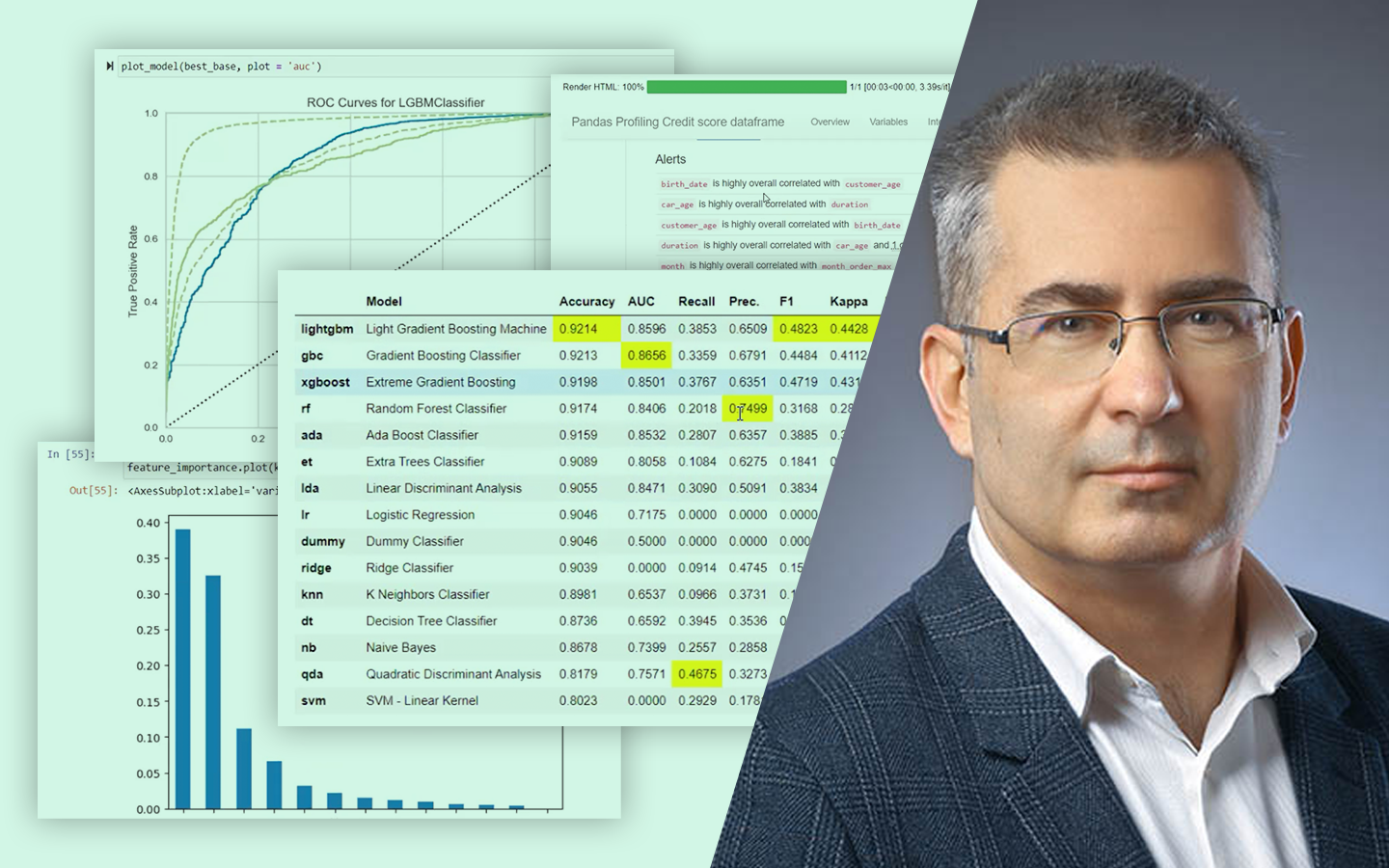
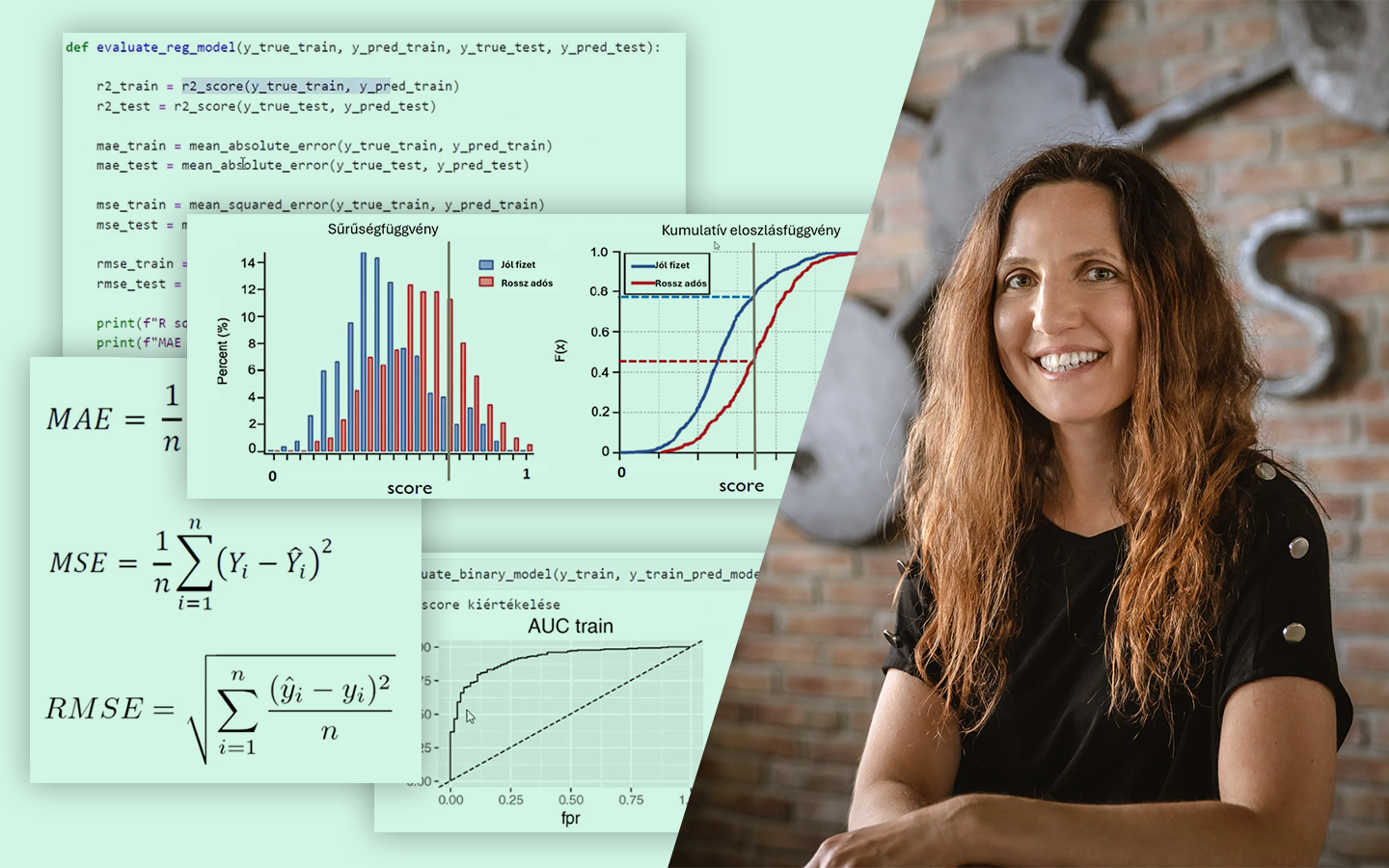
- Logisztikus regresszió és modellértékelés: miért kedvelt banki modell az interpretálhatósága miatt, ROC/AUC és Kolmogorov–Smirnov a szeparáció mérésére, valamint cutoff meghatározás.
- Modellezésből üzleti szám: a predikciók felhasználása várható veszteség és céltartalék számításra (predikció × tőkehátralék → portfóliószintű várható veszteség).