Az adattisztítás ritkán látványos, mégis gyakran ezen múlik, hogy egy elemzésből valóban használható következtetés szülessen. Az „Adattisztítási Példák Valós Projektekből” előadásban Mester Tomi (Data36) 16 tipikus hibán keresztül mutatja meg, hogyan érdemes felismerni, rendszerezni és javítani a problémás adatokat. A néző nemcsak példákat kap, hanem egy gyakorlatban is alkalmazható gondolkodásmódot is: hogyan találjon mintákat, mikor használjon sztenderd megoldást, és mikor kell kreatívan rekonstruálni hiányzó vagy hibás értékeket. Az előadás célja, hogy tisztább adatokkal dolgozz, megbízhatóbb elemzéseket készíts, és kevesebb idő menjen el elkerülhető adatminőségi hibákra.
Milyen főbb témákról van szó az előadásban?
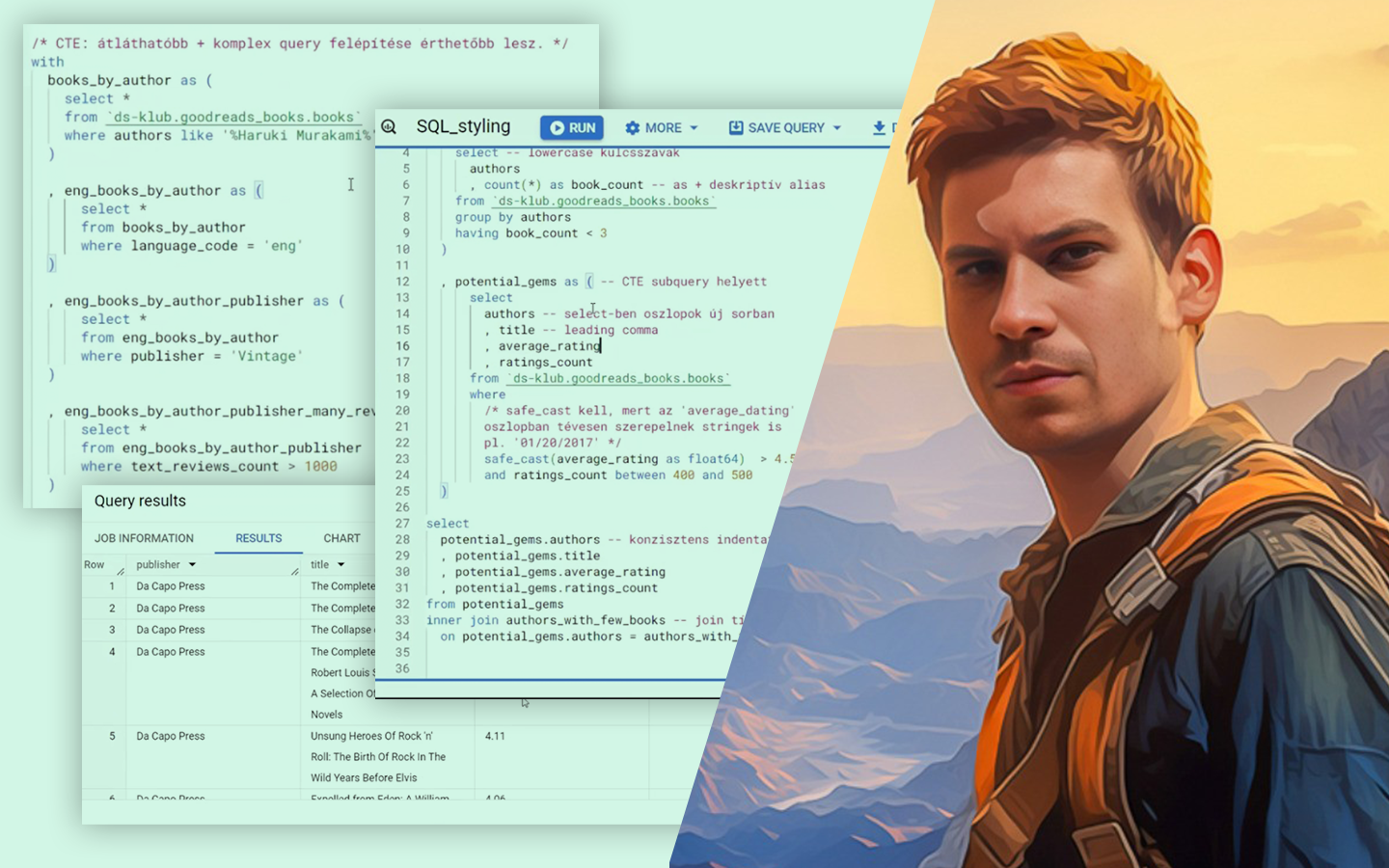
- Adatbeviteli hibák (emberi rögzítésből): elgépelések és „majdnem ugyanaz” szövegek kezelése (például városnevek) hasonlóságméréssel.
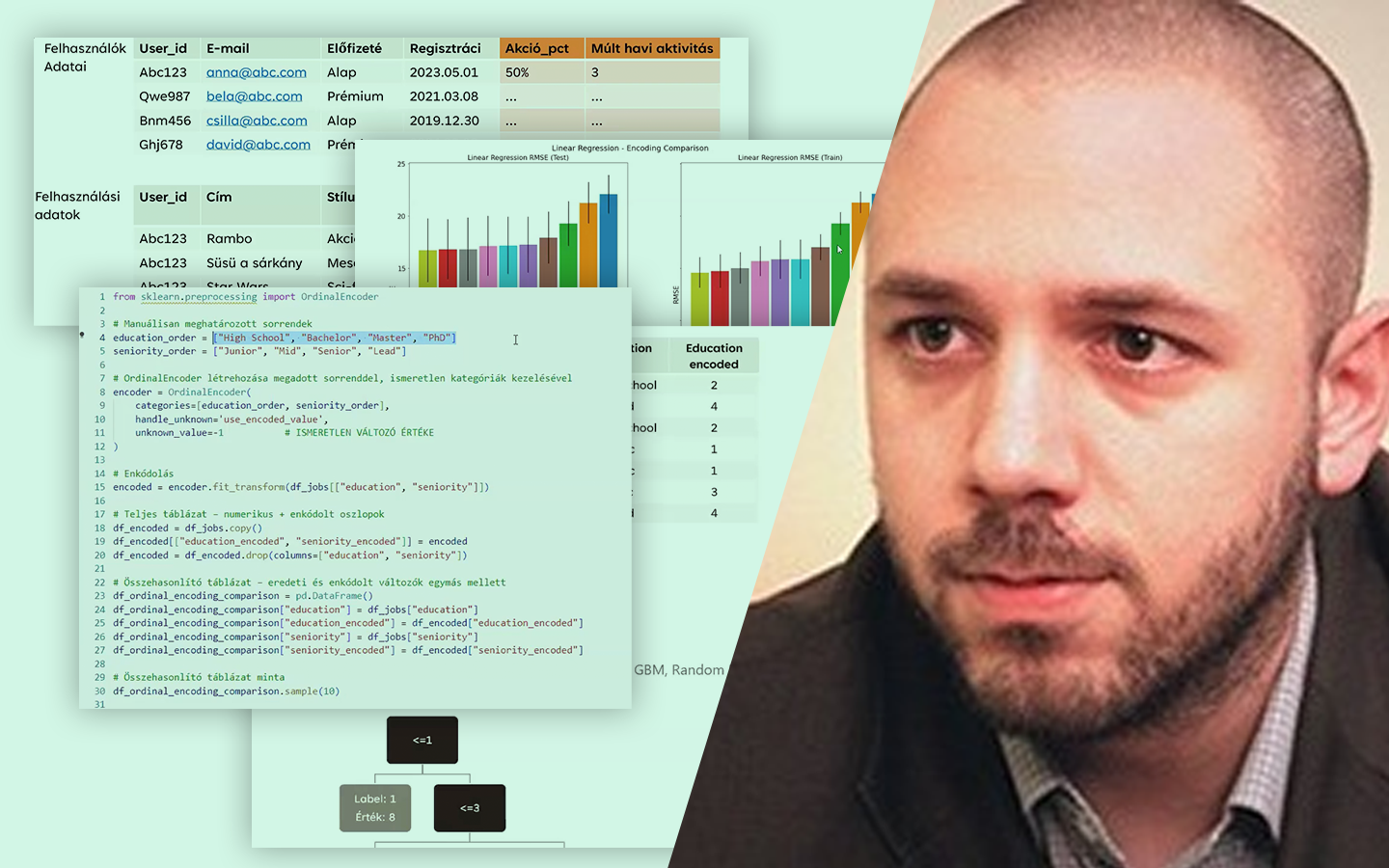
- Adatbeviteli hibák: nem konzisztens kategórianevek (pl. F/N/M, male/female) egységesítése, és visszakövetkeztetés külső adatforrás bevonásával (például keresztnév alapján).
- Adatbeviteli hibák: nem konzisztens adattípusok és hiányzó értékek (None vs. „none” vs. üres cella), valamint dátumformátumok tipikus csapdái.
- Adatgyűjtési hibák (szkriptek, szenzorok, logolás): duplikátumok felismerése, amikor „ugyanaz” a mérés többször kerül be, akár minimális időeltéréssel.
- Adatgyűjtési hibák: hiányzó mezők és hiányzó sorok kezelése: mi pótolható redundanciából, és mi az, ami végleg elveszett (például AB-teszt logolás kiesése).
- Infrastruktúra / rendszertervezési hibák: visszafordíthatatlan vagy nehezen kezelhető transzformációk elkerülése (például kötőjelek eltávolítása URL-ekből).
- Infrastruktúra / rendszertervezési hibák: nehezen olvasható logformátumok, rossz mezőelválasztók (vessző-probléma) és karakterkódolási gondok.
- Infrastruktúra / rendszertervezési hibák: sémaváltozás miatti elcsúszások (például oszlopszám változik), és miért érdemes név szerint dolgozni.