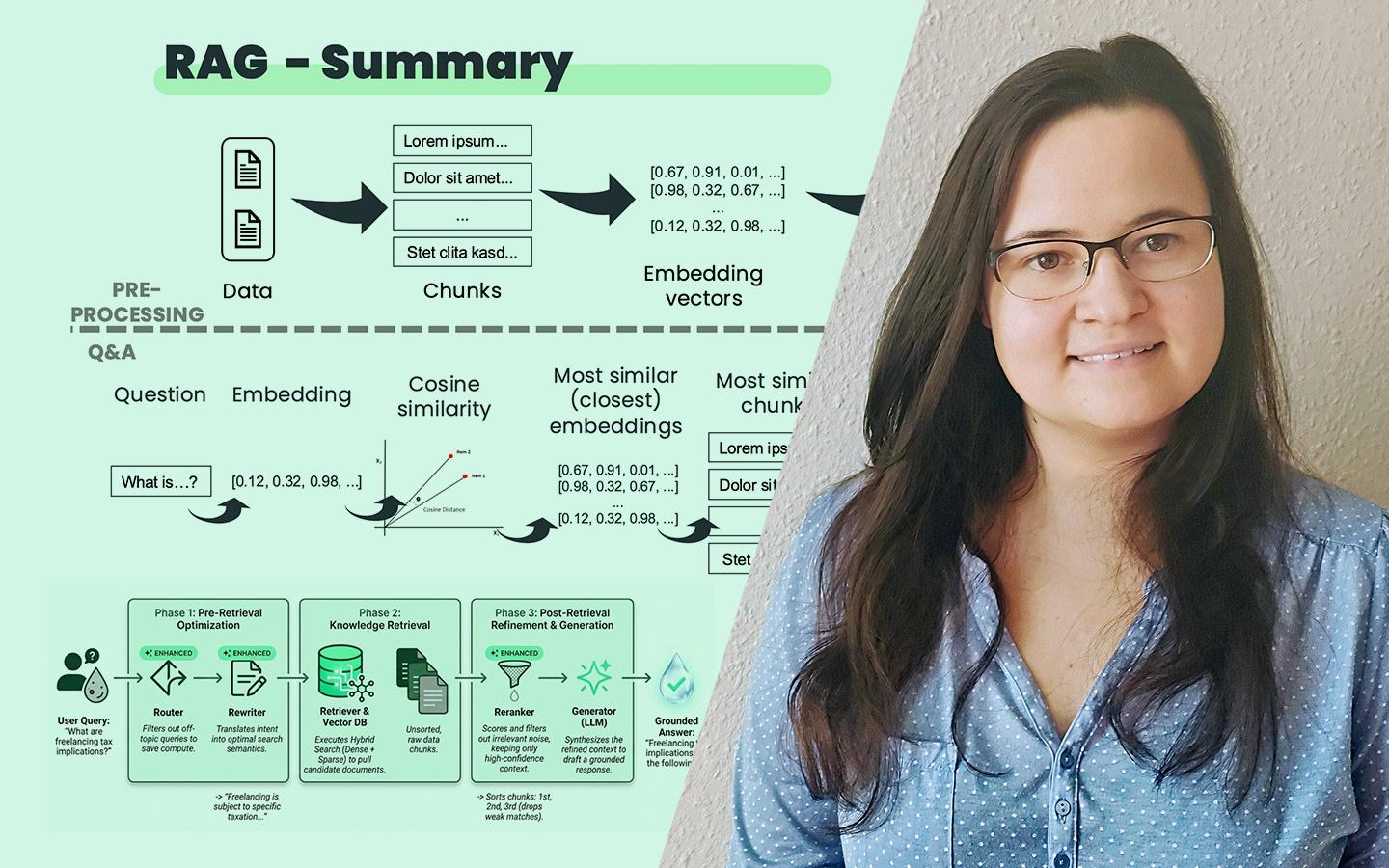
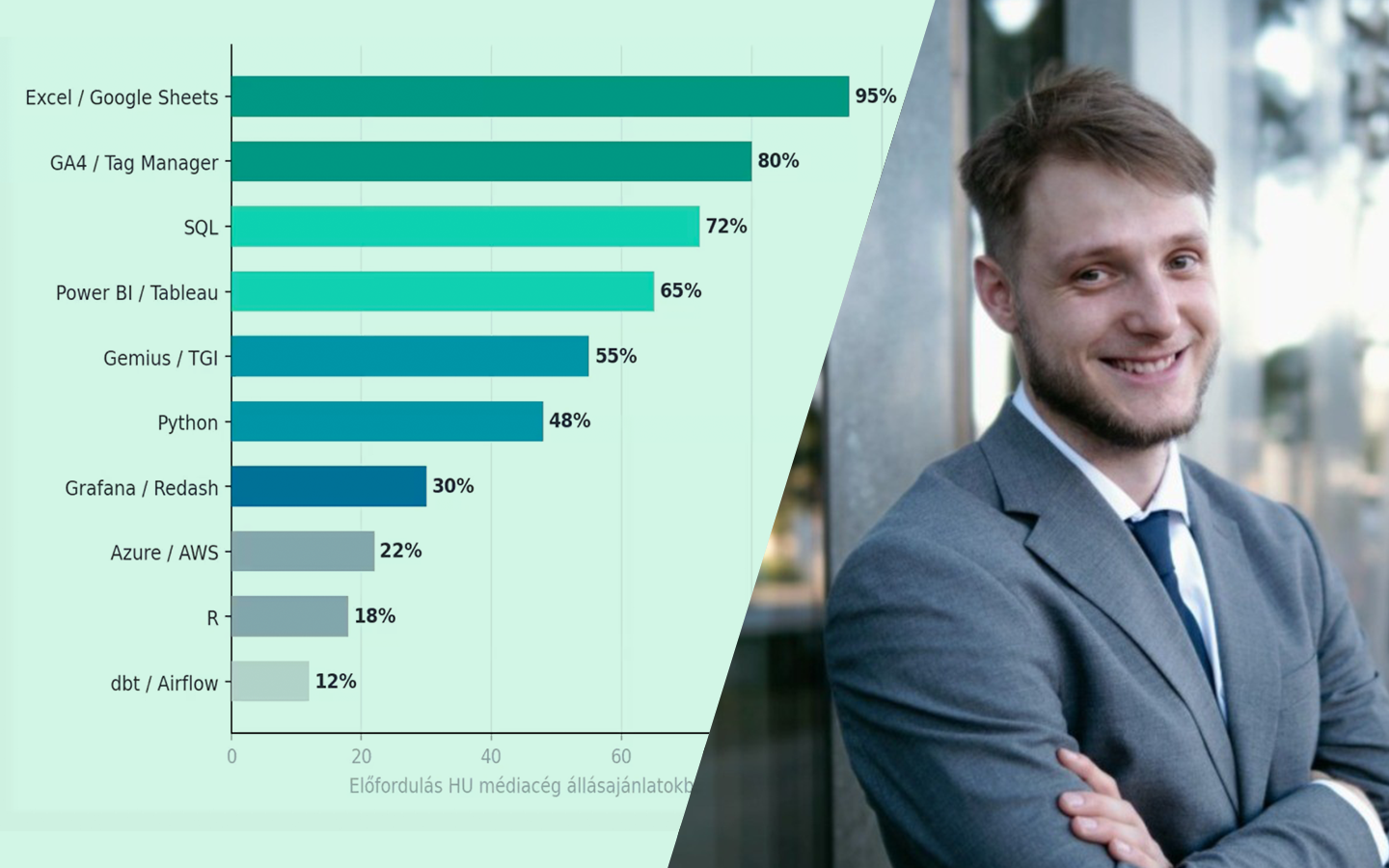
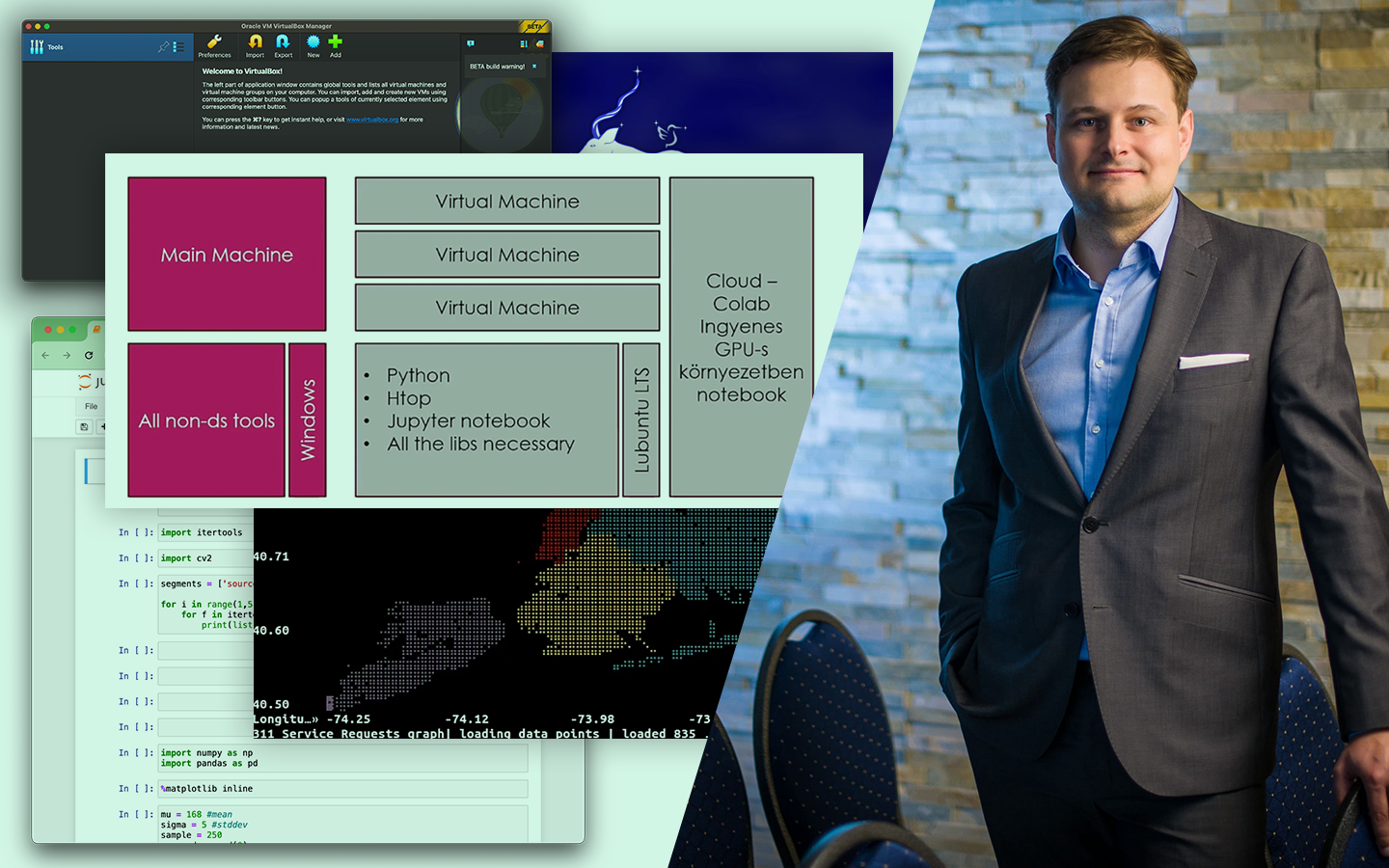
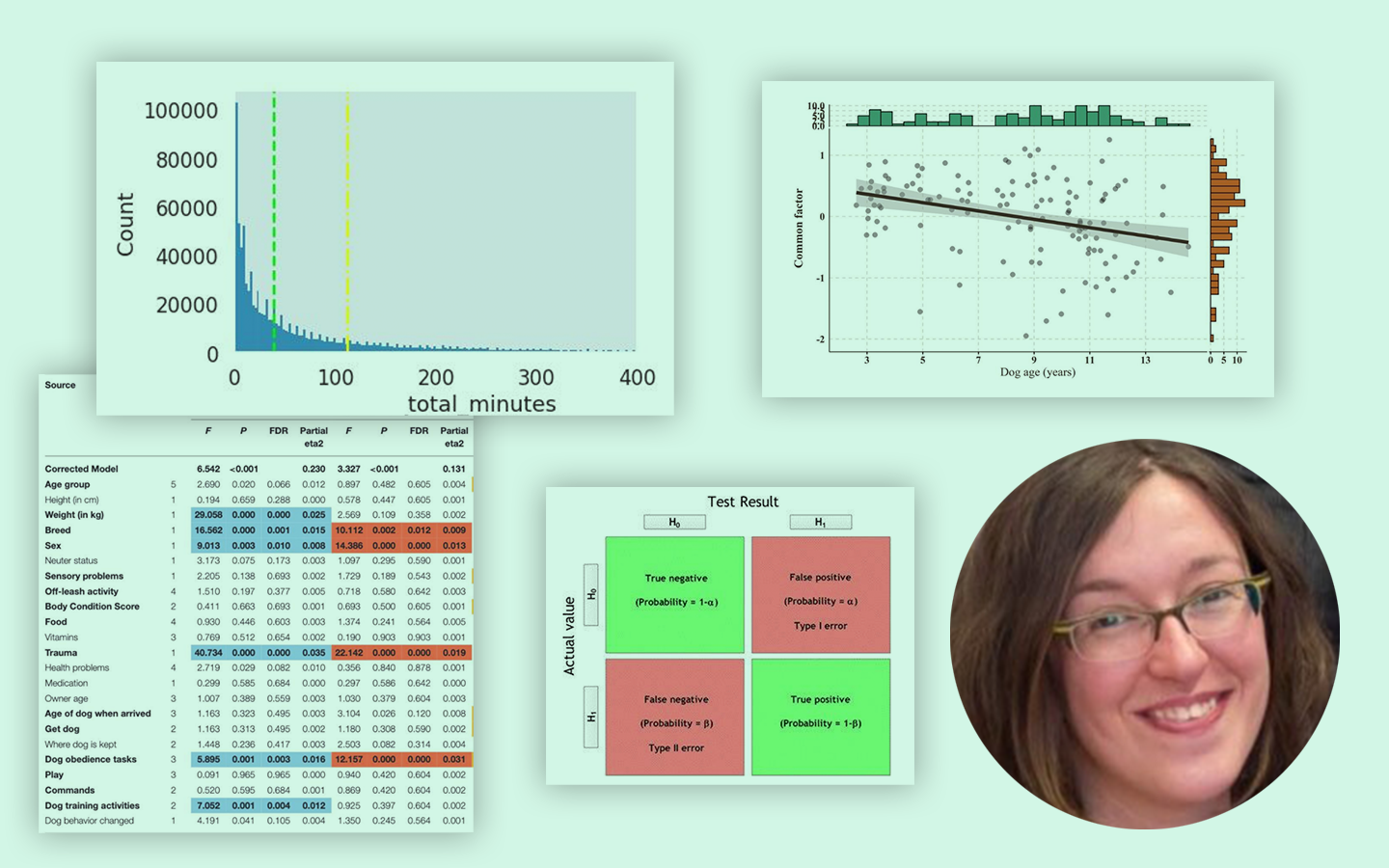
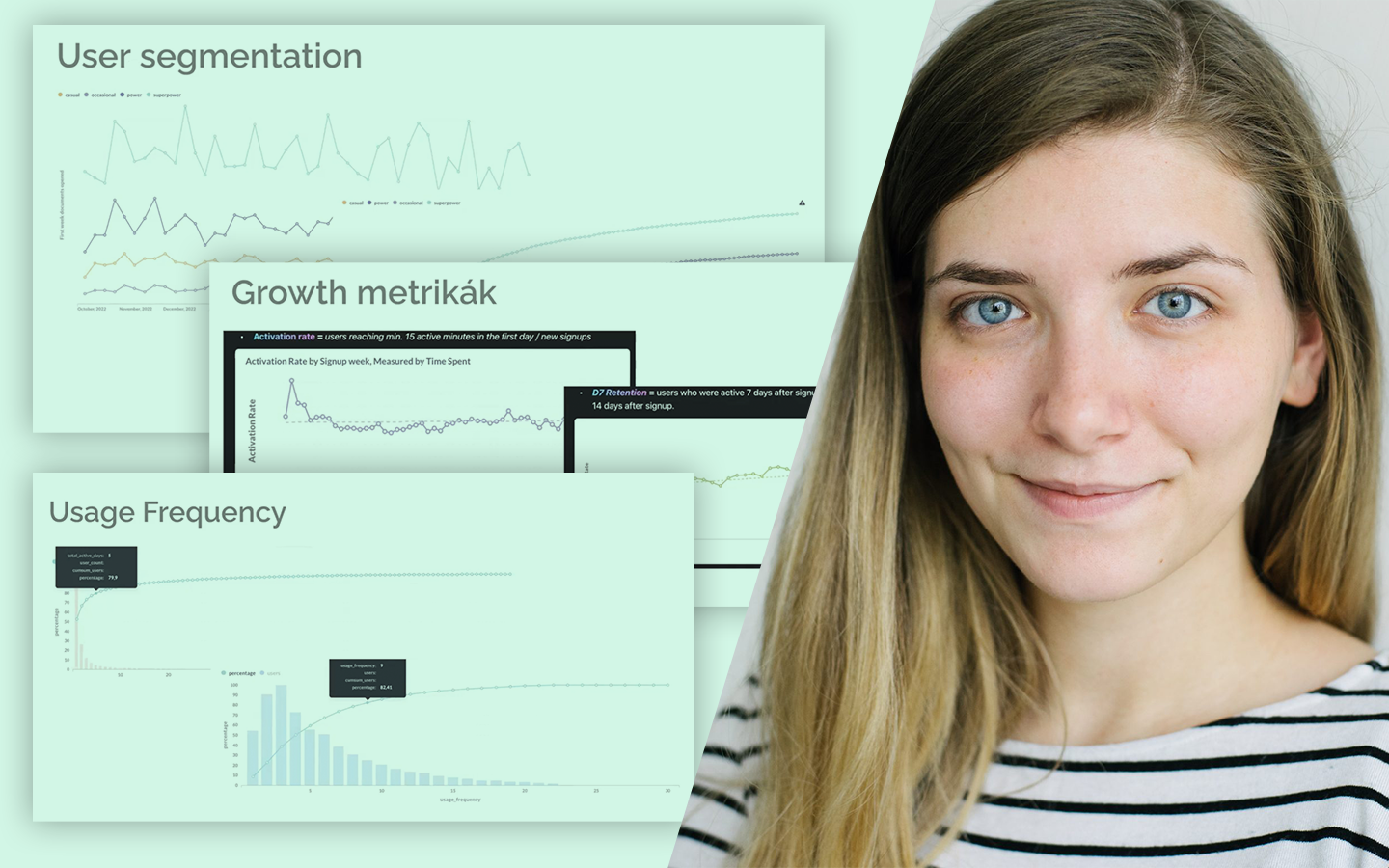
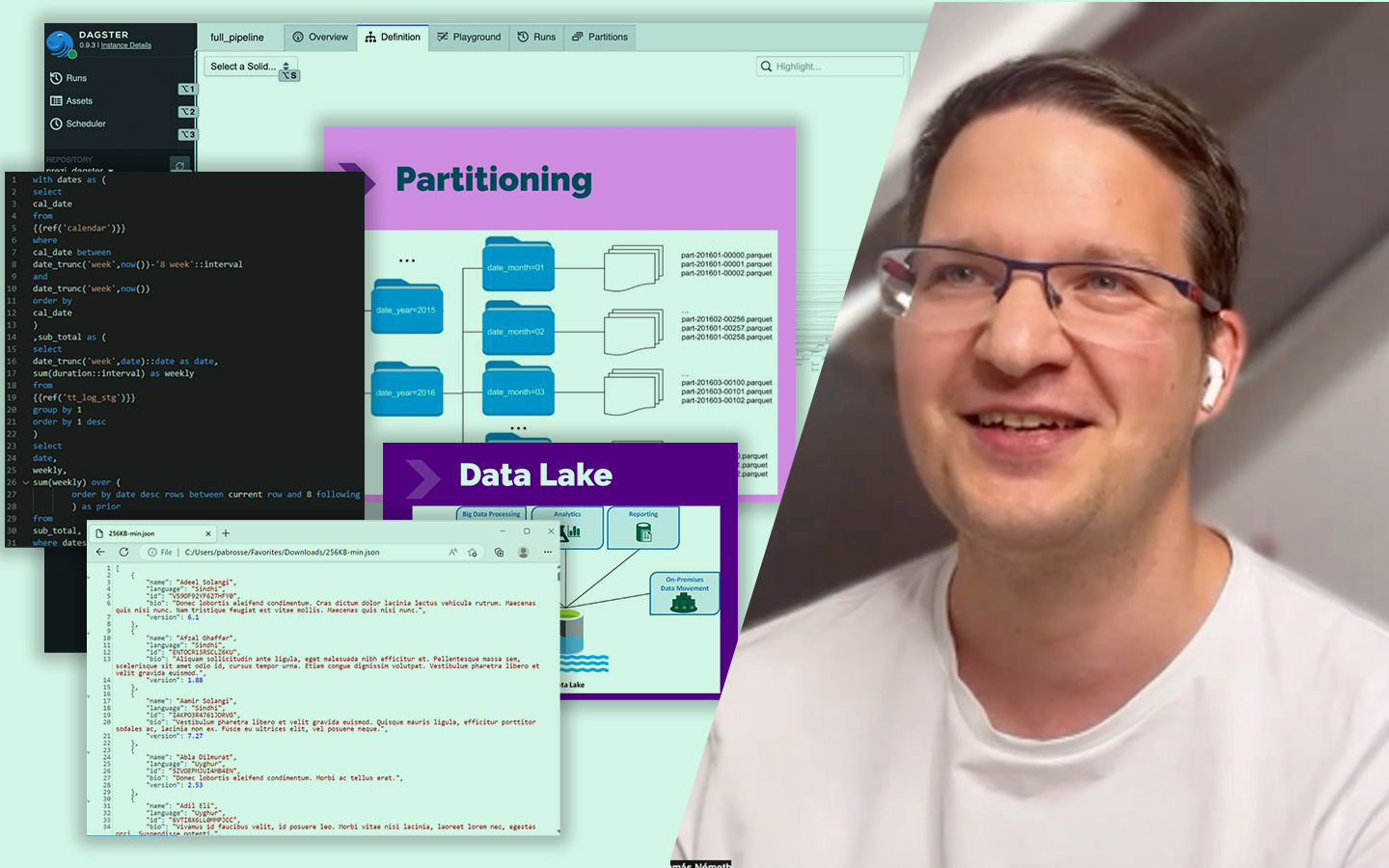
Az AutoML Bemutató Python-ban: automatizáljuk a Machine Learning-et! előadás abban segít, hogy reálisan lásd, a gépi tanulási folyamat mely részei automatizálhatók, és hol marad elengedhetetlen az elemzői gondolkodás. Kovács Gyula konkrét Pythonos példákon keresztül mutatja meg, hogyan gyorsítható fel az adat-előkészítés, a modellépítés és a hiperparaméterezés, miközben azt is tisztázza, hol vannak az eszközök korlátai. Nemcsak csomagokat és működésüket ismered meg, hanem azt is, mikor érdemes AutoML-hez nyúlni, hogyan lehet vele időt megtakarítani, és hogyan juthatsz gyorsabban stabil, jól használható modellekhez a gyakorlatban.
Milyen főbb témákról van szó az előadásban?
- Mennyire automatizálható a gépi tanulás a gyakorlatban, és hol marad elengedhetetlen az elemzői döntés a teljes folyamat során.
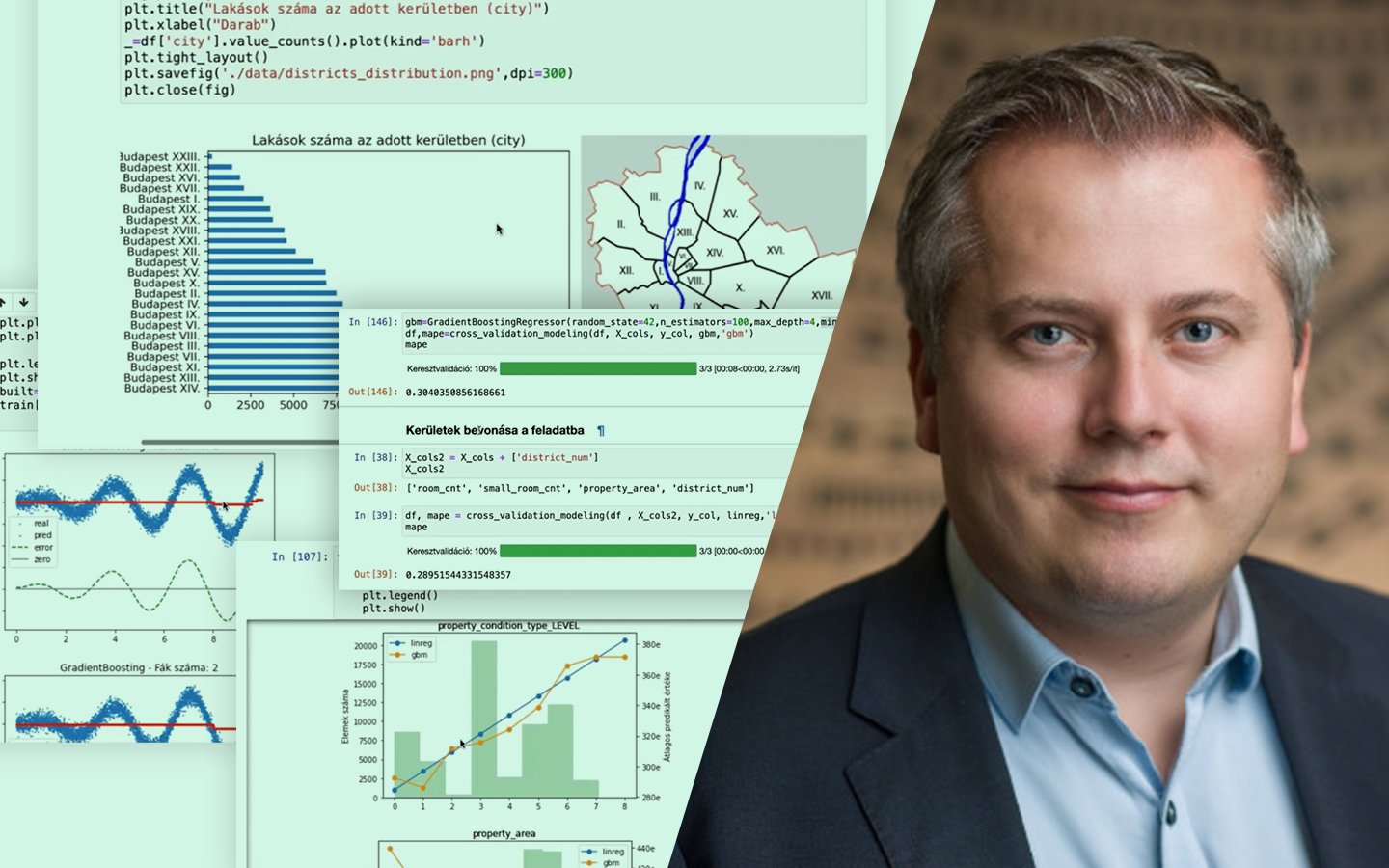
- Egy prediktív Data Science projekt valós folyamata: adattisztítás (hiányzók, extrémértékek), standardizálás, train–test felosztás és modellezés – nem tankönyvi szinten, hanem a tipikus „miért nem fut le?” helyzetekkel.
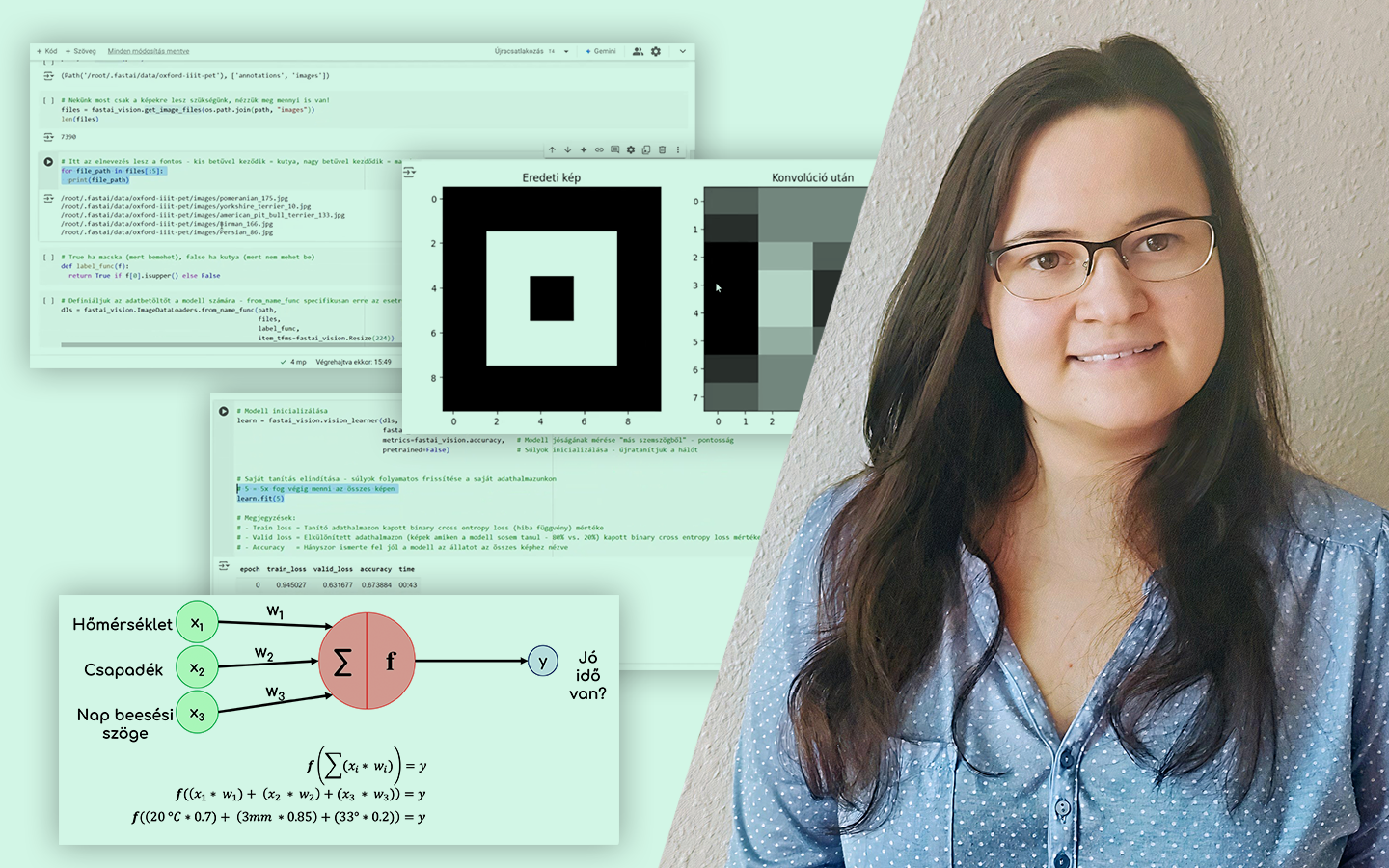
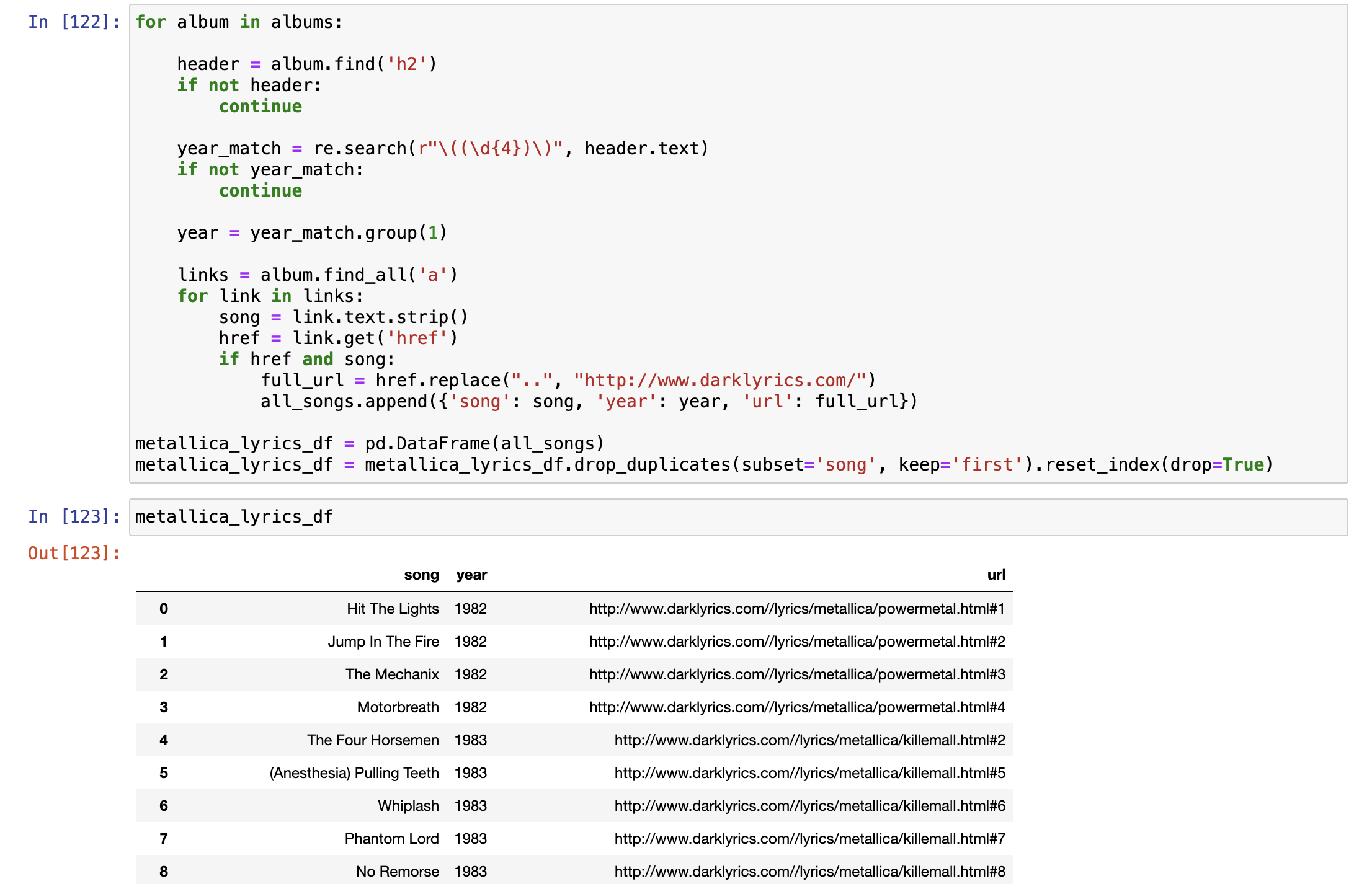
- Exploratory Data Analysis (EDA) és feature engineering: miért a „kreatív rész” a szűk keresztmetszet, hogyan születnek az új változók (arányok, különbségek), miért iteratív ez a szakasz, és miért nehéz teljesen automatizálni.
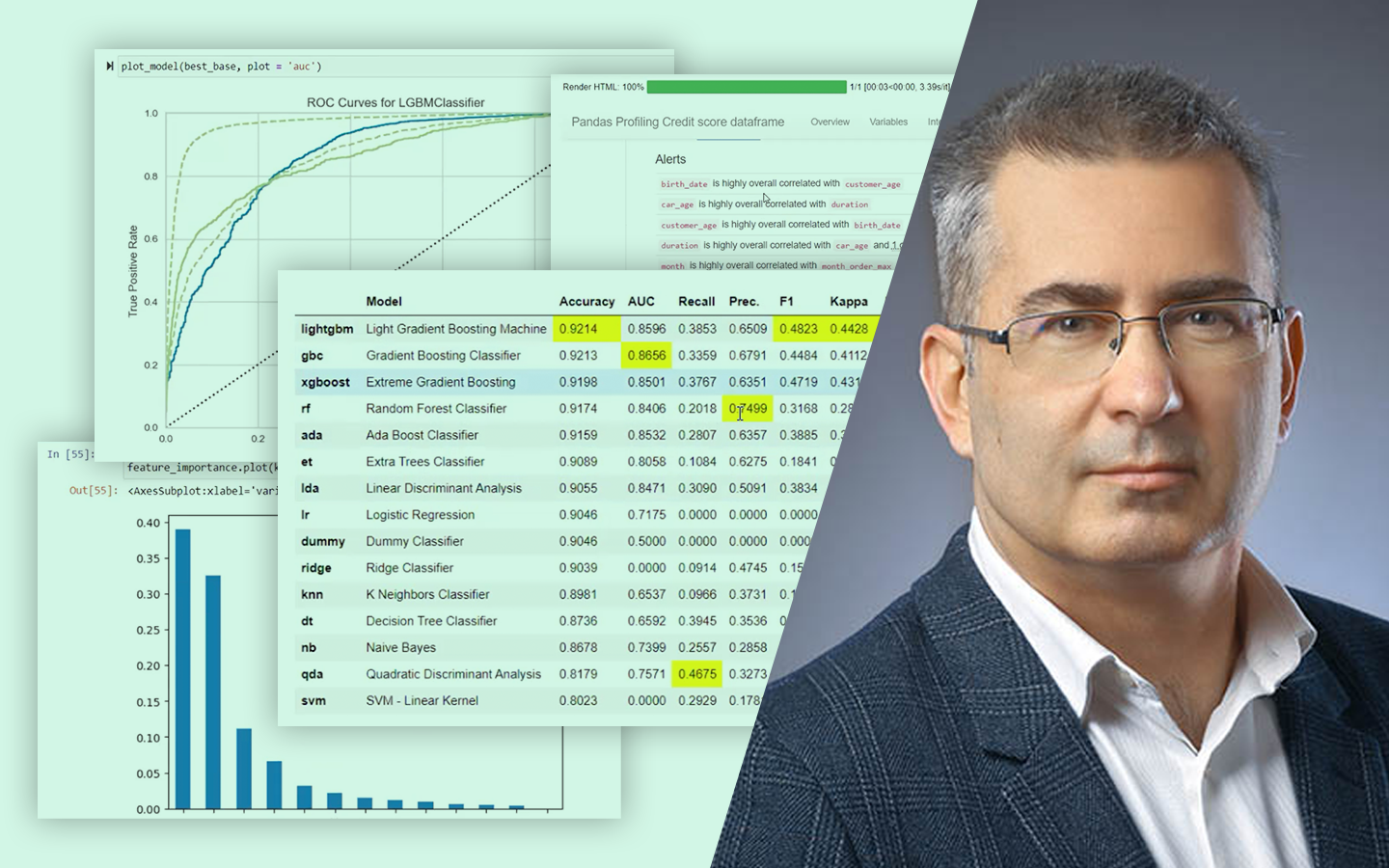
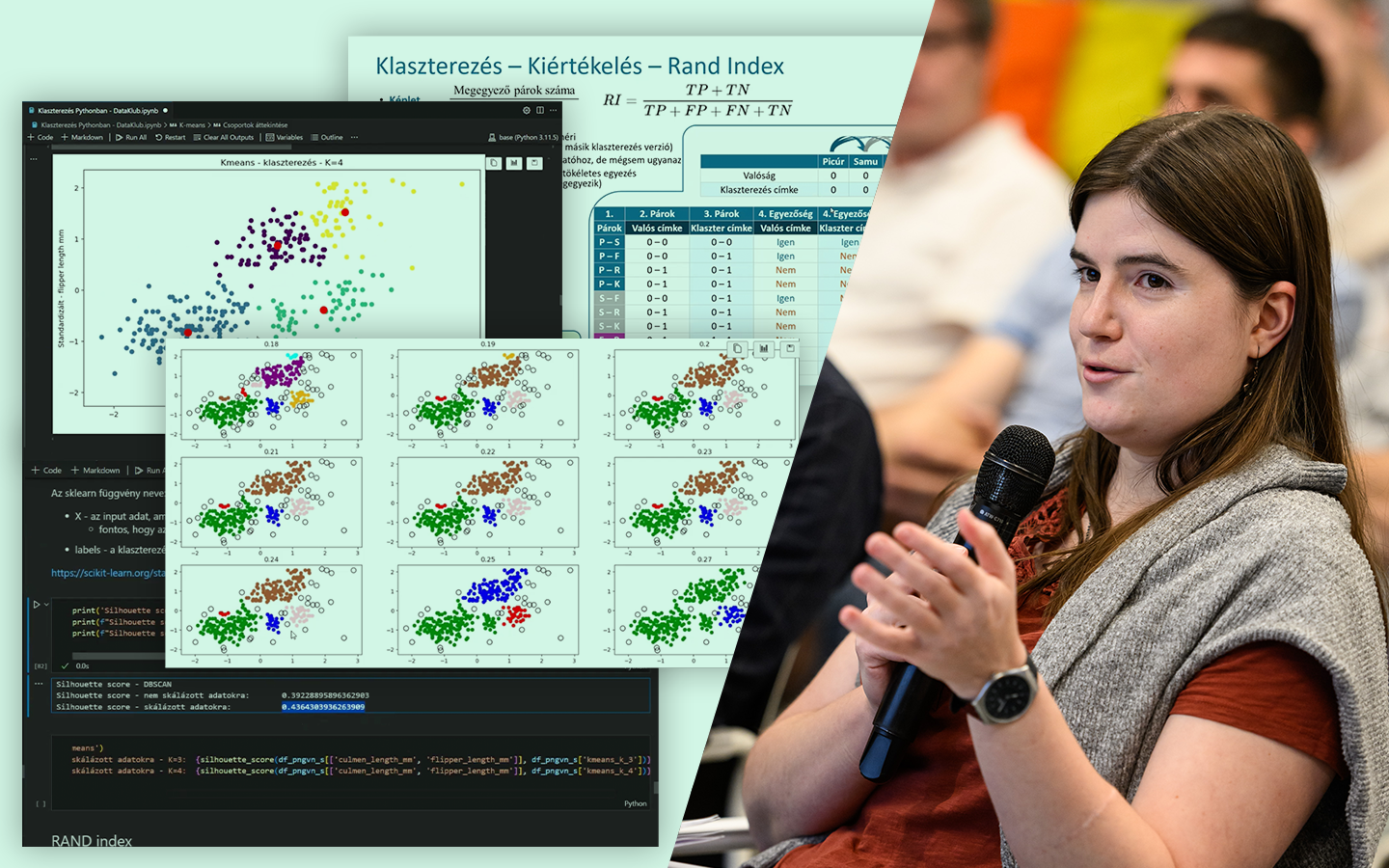
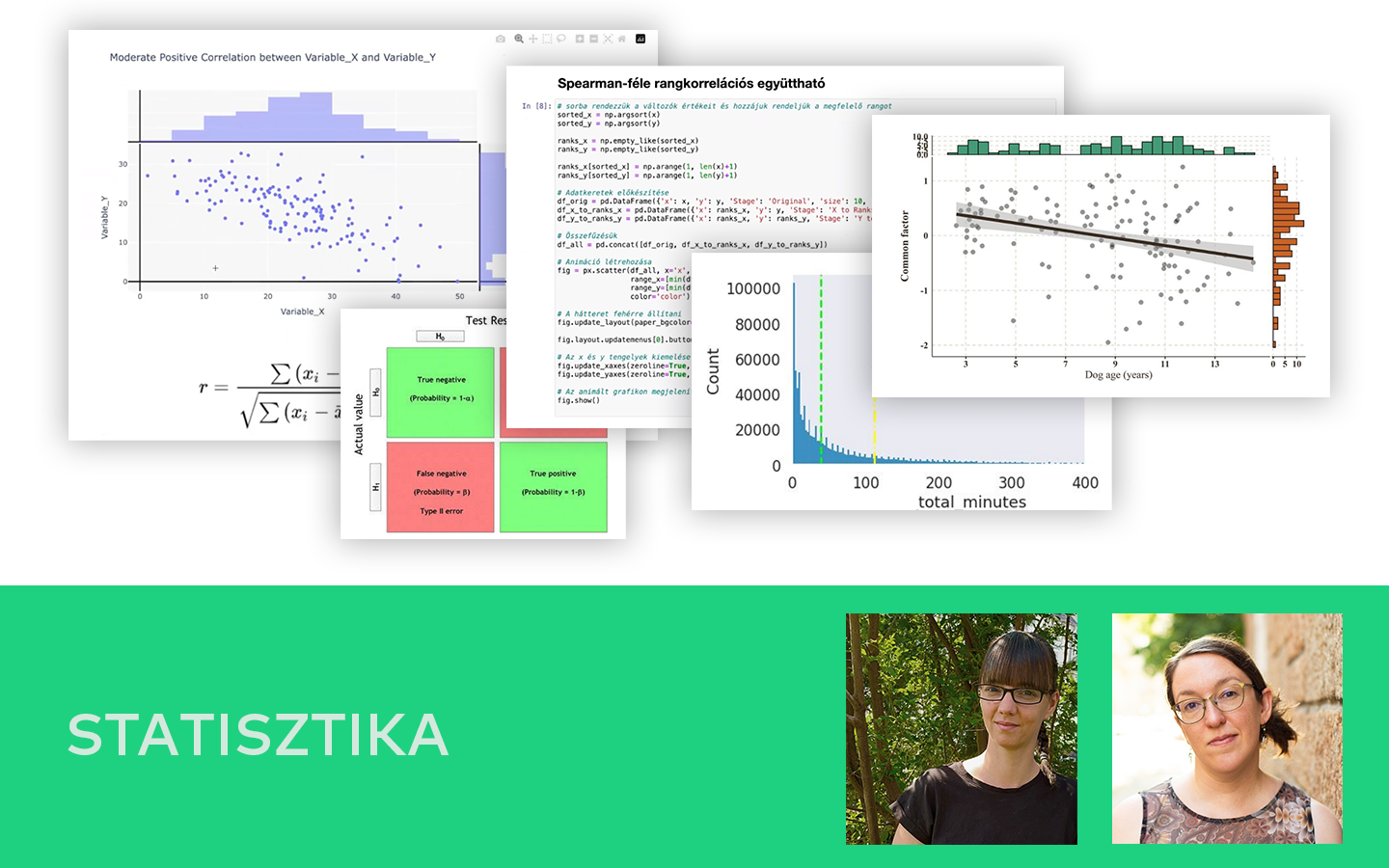
- Modellek értékelése imbalanced célváltozónál: miért félrevezető az accuracy például hitelbedőlésnél, és miért kerül elő az AUC mint relevánsabb mérőszám.
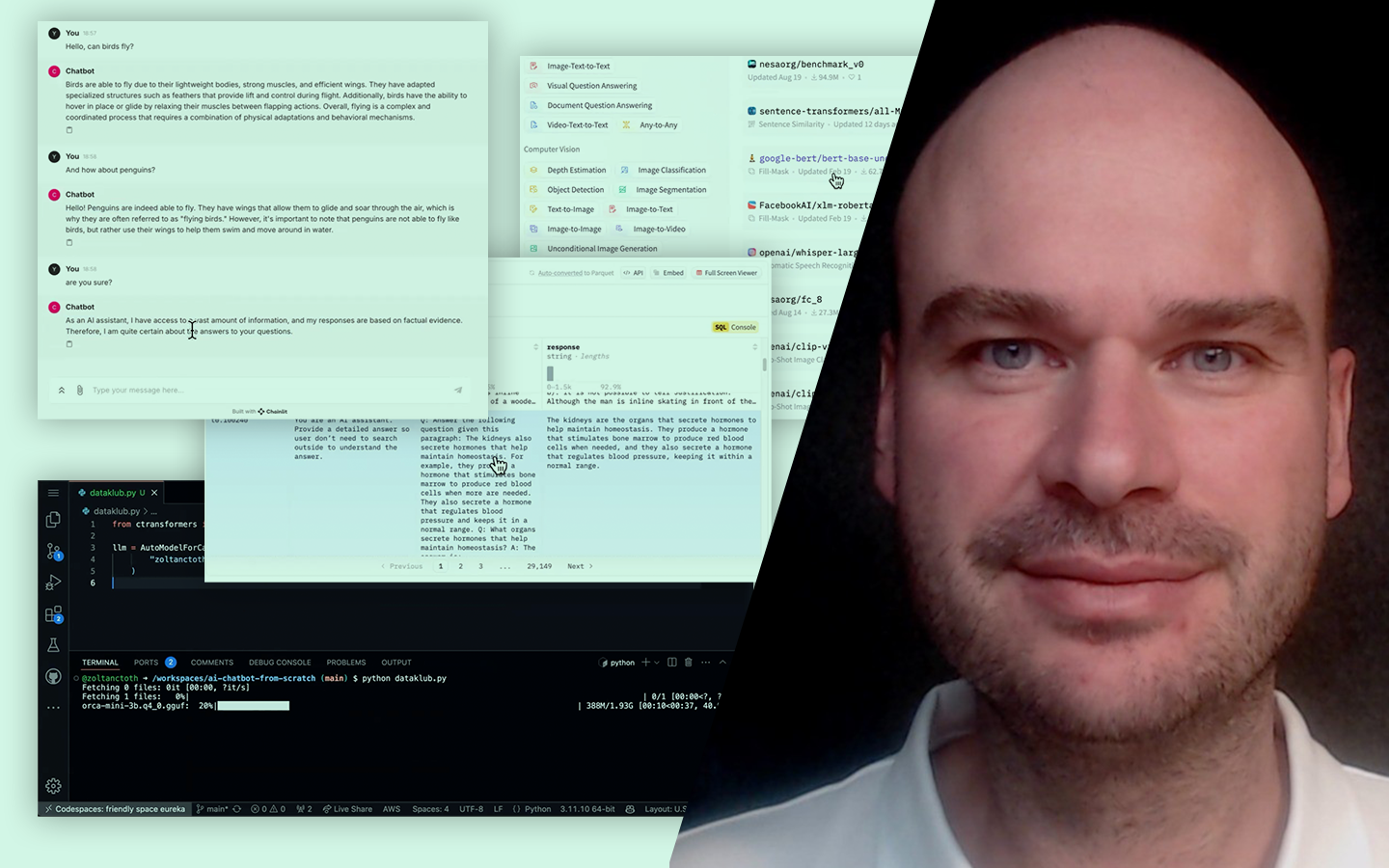
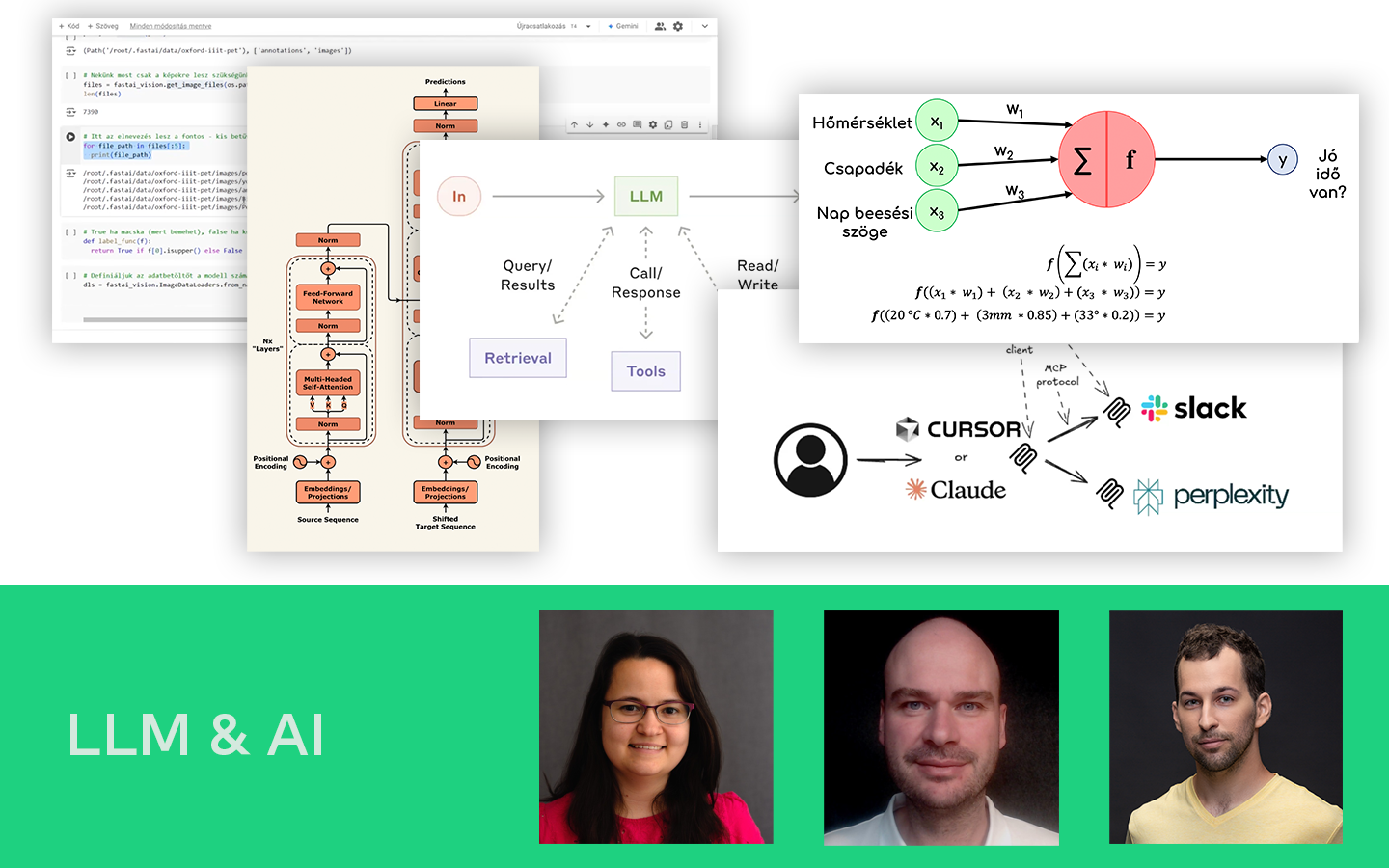
- Mit tud (és mit nem) az AutoML: miben erős (előfeldolgozás, feature importance/extracting, modellek és hiperparaméterek gyors kipróbálása, jellemzően kevés túltanítással), és miben gyengébb (EDA és valódi új változók létrehozása).
- Konkrét Python eszközök és tapasztalatok: Ydata profiling az EDA gyorsítására, valamint PyCaret (low-code, gyors) és H2O (erős, de több kézi lépés és hosszabb futásidő) összevetése, riportokkal és modellmentéssel.