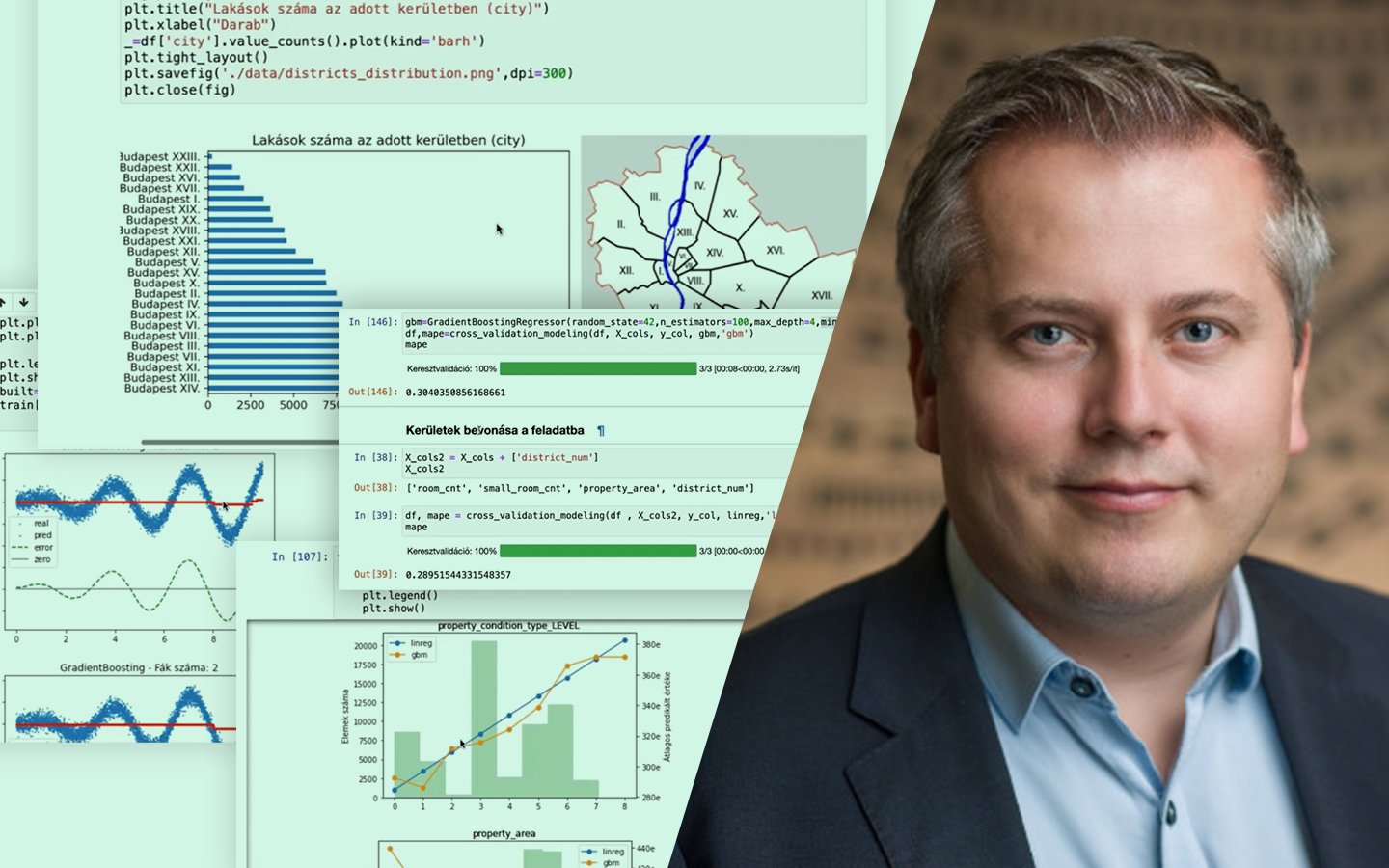
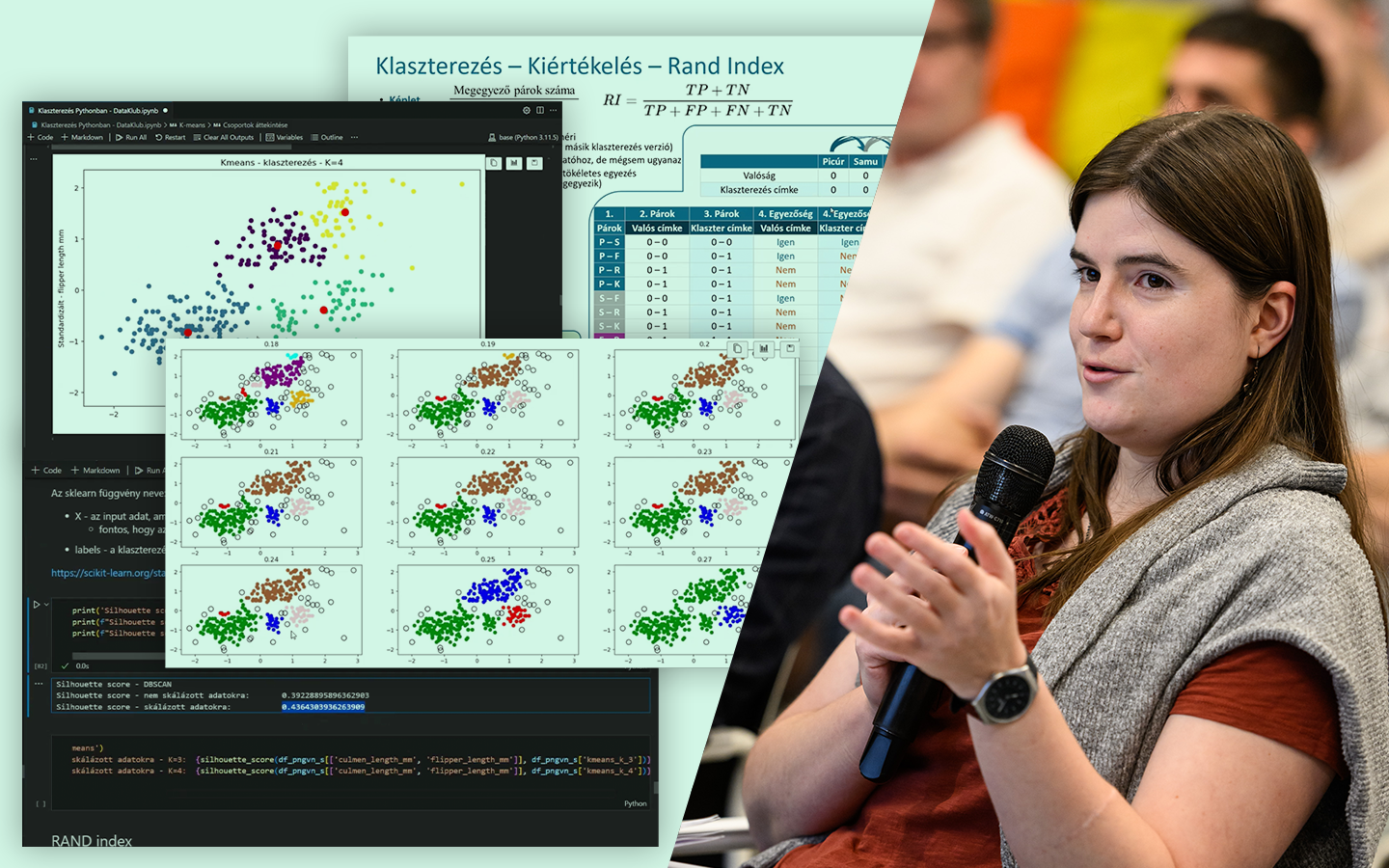
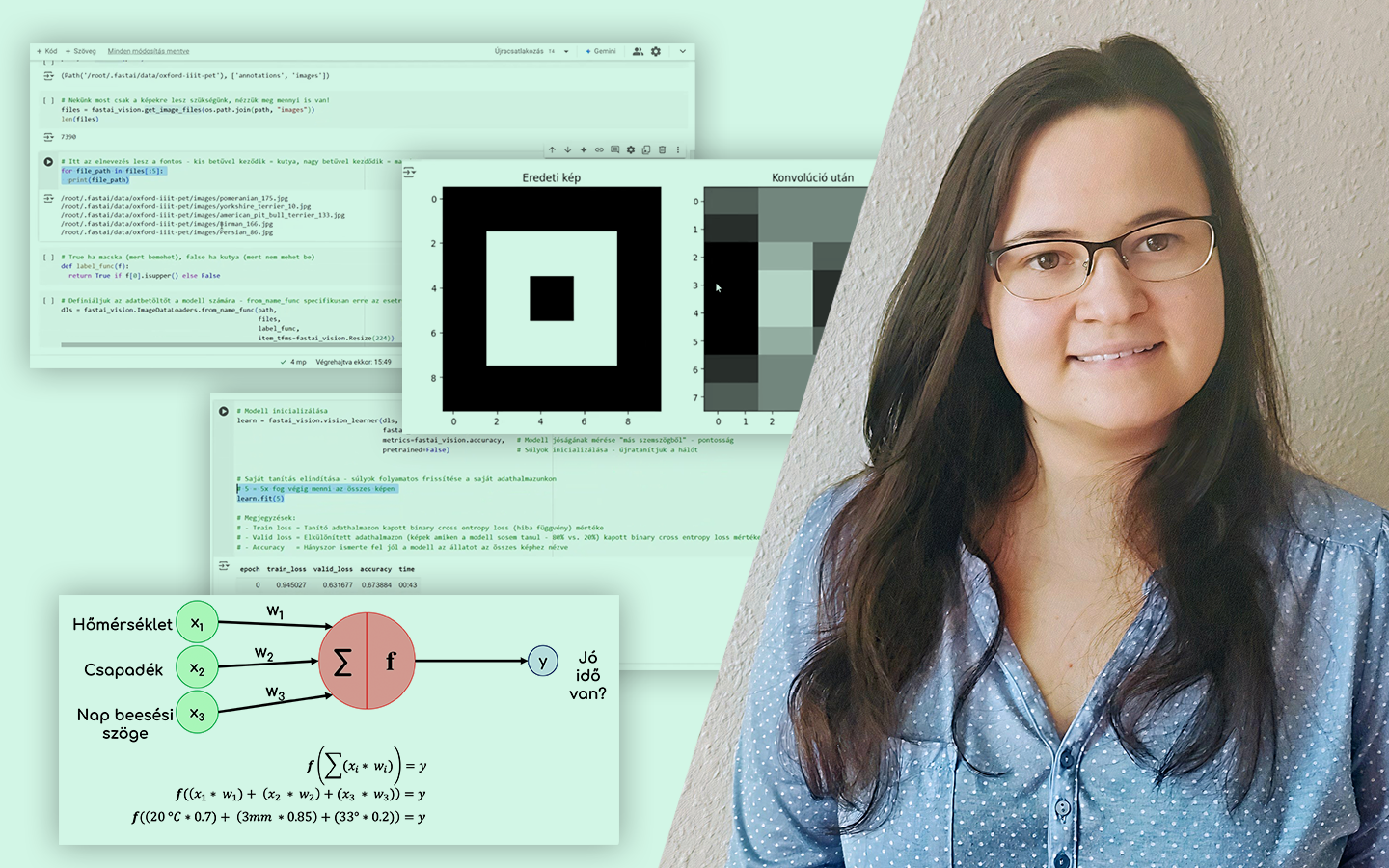
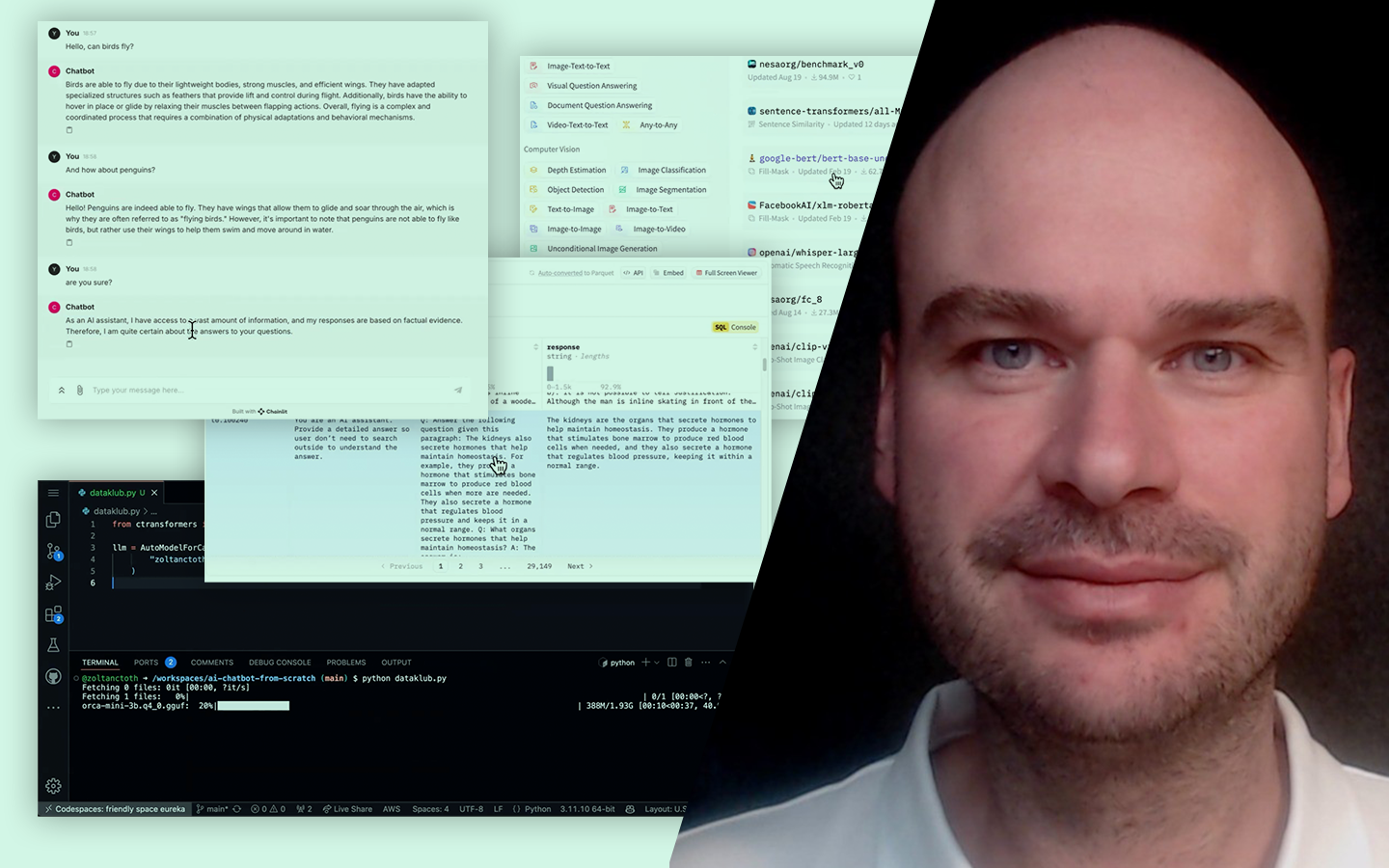
Ha szeretnéd megérteni, miért nem elég „csak” modellt építeni, ezt az előadást érdemes megnézned. Az Adatelőkészítés – és Hatása a Modellezés Pontosságára lépésről lépésre mutatja meg, hogyan változik egy modell teljesítménye attól függően, hogyan készítjük elő az adatokat. Gáspár Csaba (senior data scientist @dmlab) egy valós, budapesti ingatlanhirdetési adathalmazon keresztül, Pythonban, egy IPython notebook mentén vezeti végig a folyamatot. Konkrétan megmutatja, mely előkészítési döntések javítanak ténylegesen a becsléseken, és melyek nem hoznak érdemi eredményt. Így nemcsak technikákat kapsz, hanem egy üzleti céllal is jól használható gondolkodásmódot a mérhető pontosságjavuláshoz.
Milyen főbb témákról van szó az előadásban?
- Cél és üzleti kontextus tisztázása (CRISP-DM szemlélet): miért nem mindegy, mire készíted elő az adatot (például új hirdetések közül az alulértékeltek azonosításához).
- Célváltozó megválasztása: lakásár helyett a négyzetméterár becslése, és ennek hatása a tanulhatóságra.
- „Rossz adatok” életszerű kezelése: extrém vagy hibás értékek (0 m², irreális ár, 215 szoba, túl nagy erkély) – mikor jelölsz, mikor zársz ki, és miért veszélyes a szűrés „túloptimalizálása”.
- Időbeli torzítások és trendek: több hónapnyi adatnál ártrend-korrekció, hogy a régi hirdetések ne húzzák félre a mai becslést.
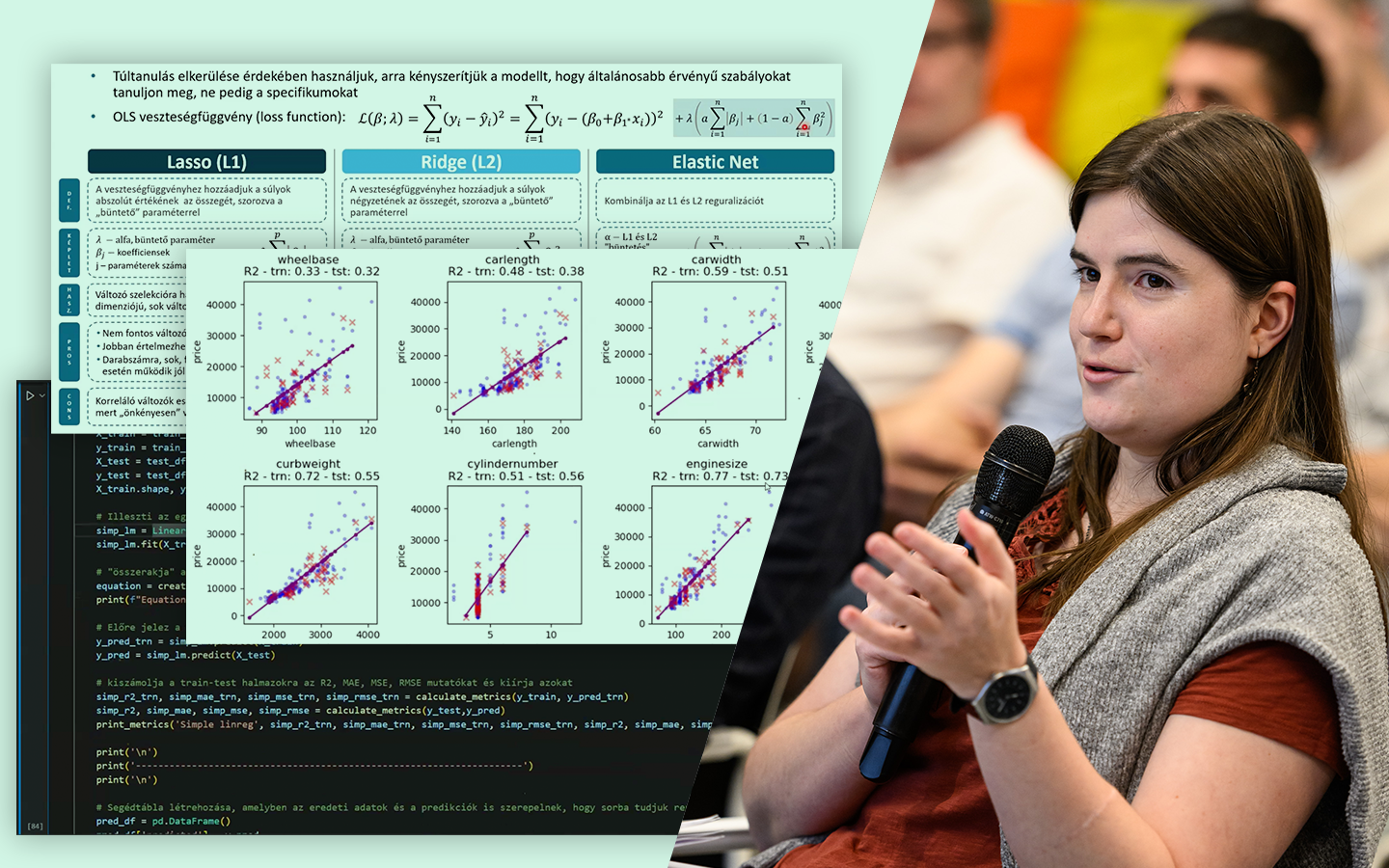
- Feature engineering lépésről lépésre: változók fokozatos hozzáadása (panel vs tégla, fűtéstípus, erkély/kert, szobaméret, kerület, emelet, tájolás).
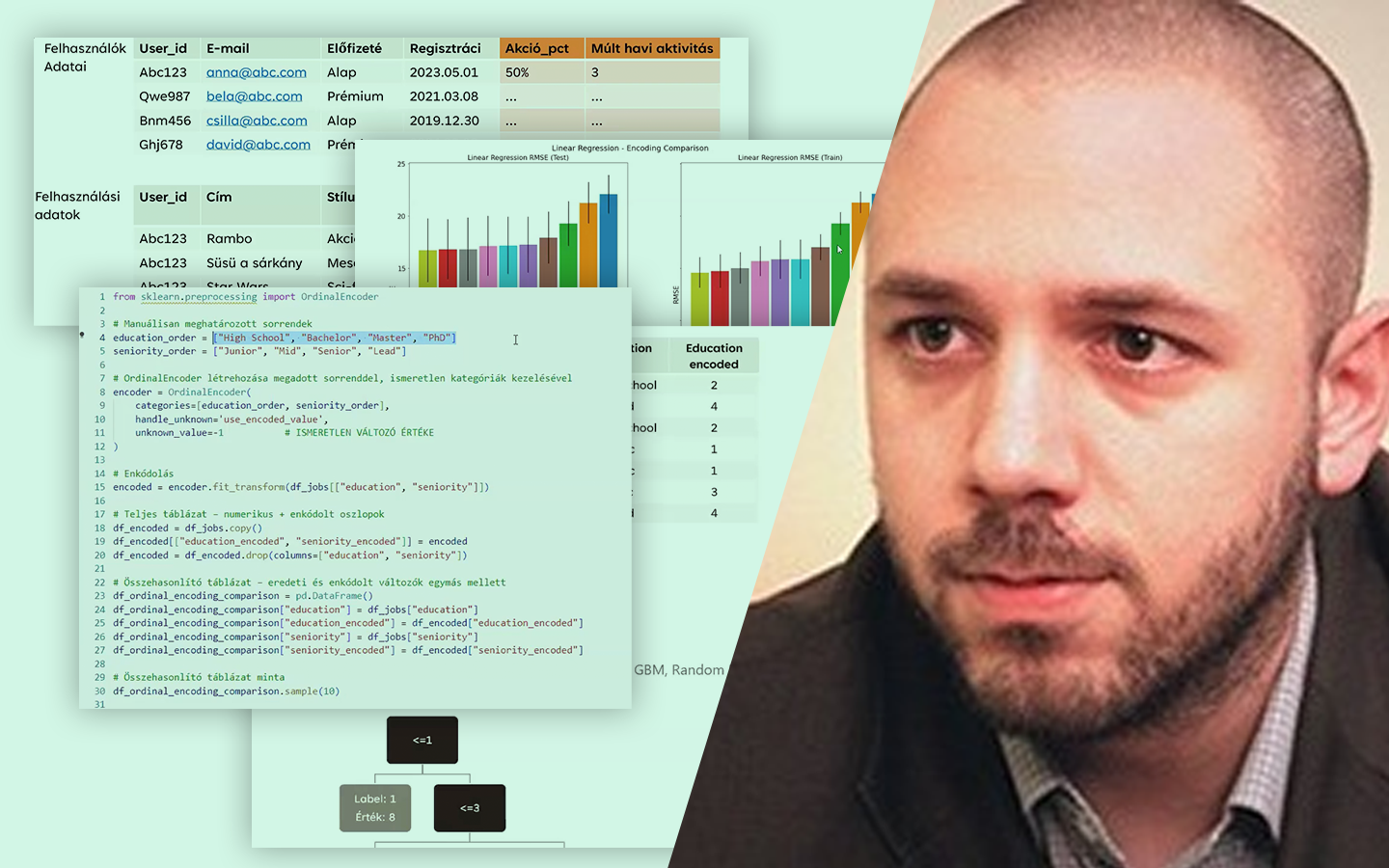
- Kódolási stratégiák összevetése: dummy vs label encoding, különösen GBM és lineáris regresszió esetén.
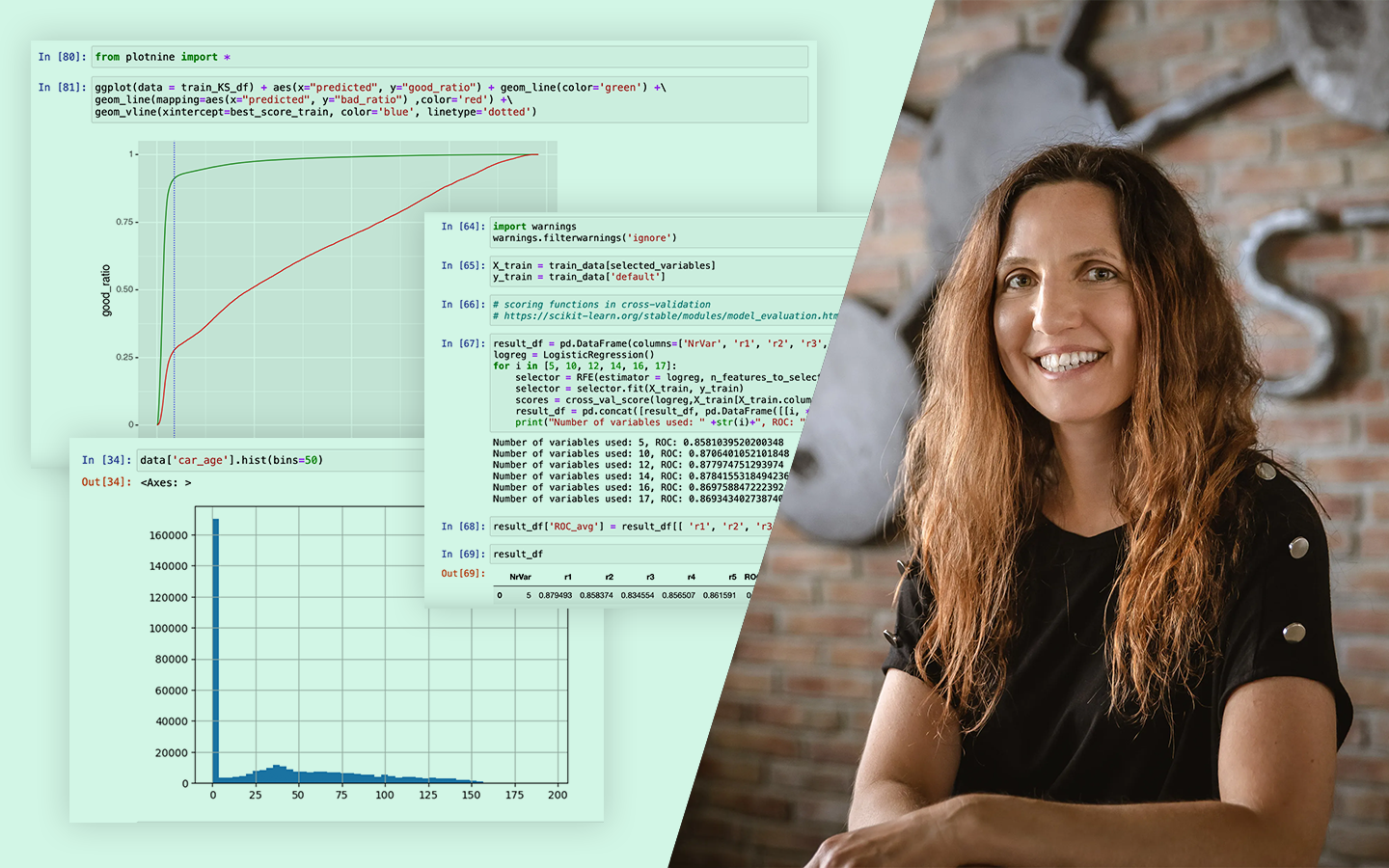
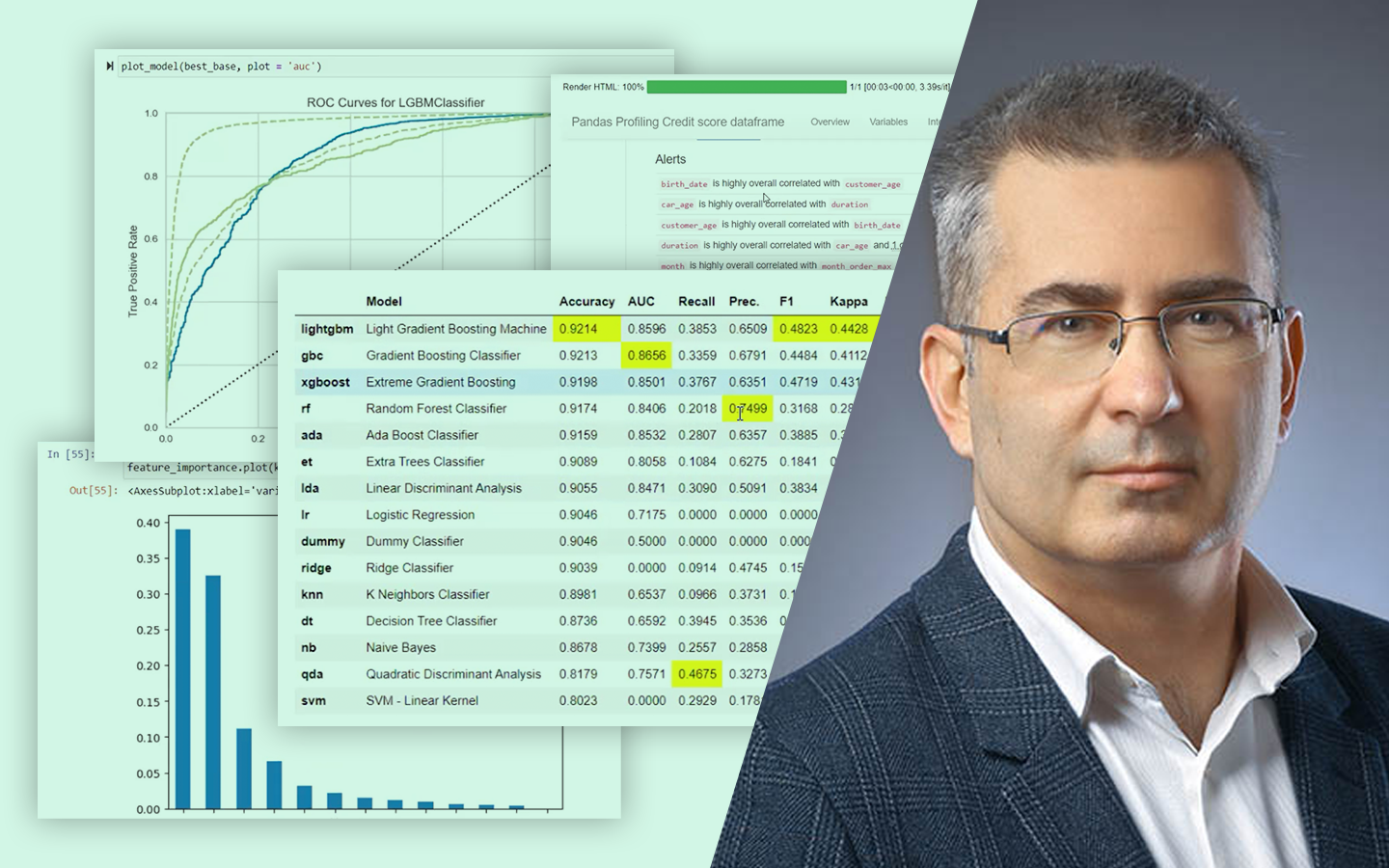
- Mérés és validálás: MAPE, 5-fold cross-validation, az utolsó hónap külön kezelése, hogy reális „éles” tesztet kapj.
- Eredmények értelmezése: mikor segít egy átalakítás, mikor nem, és hogyan áll össze a végén egy használható lista a potenciálisan alulértékelt hirdetésekről.