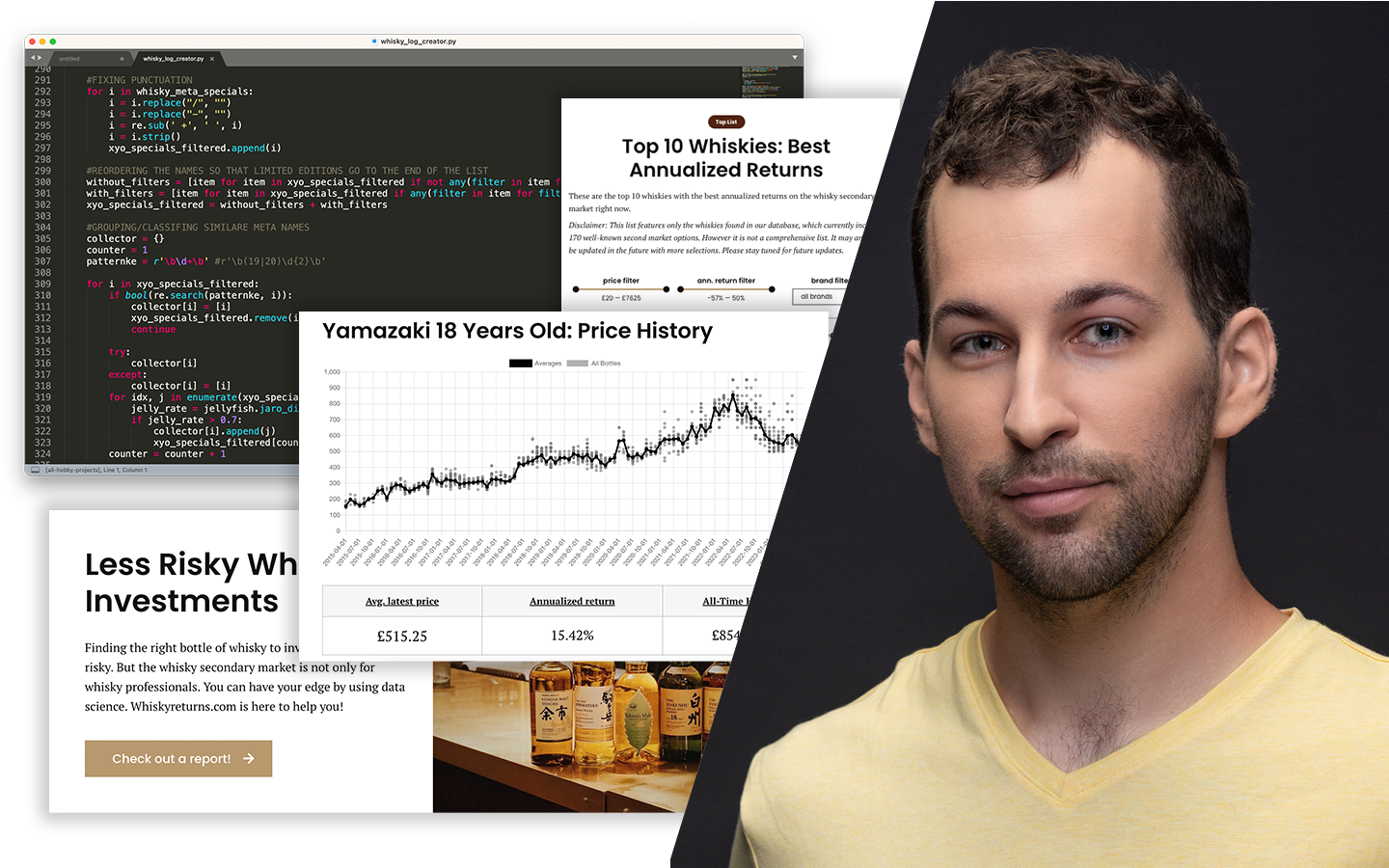
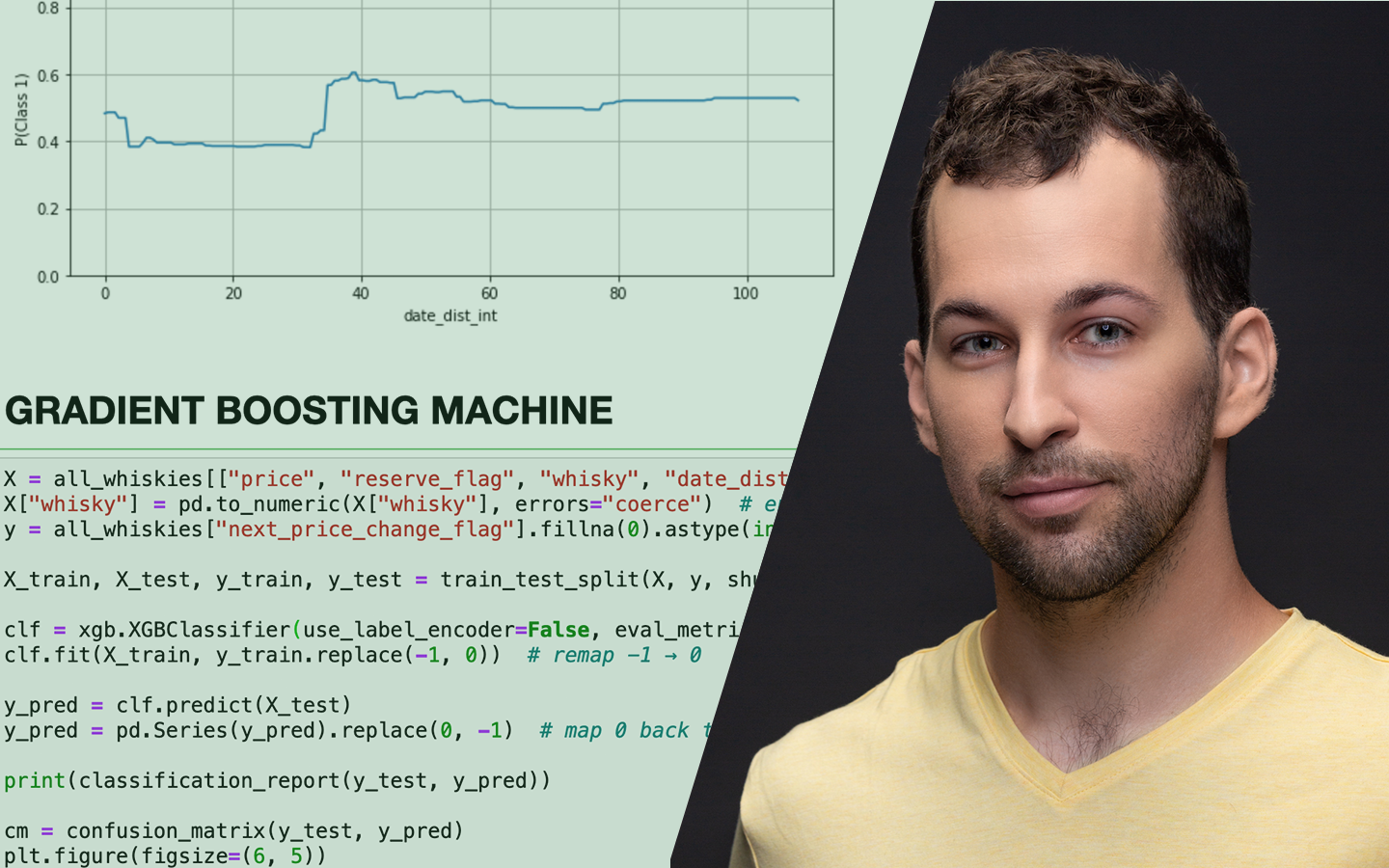
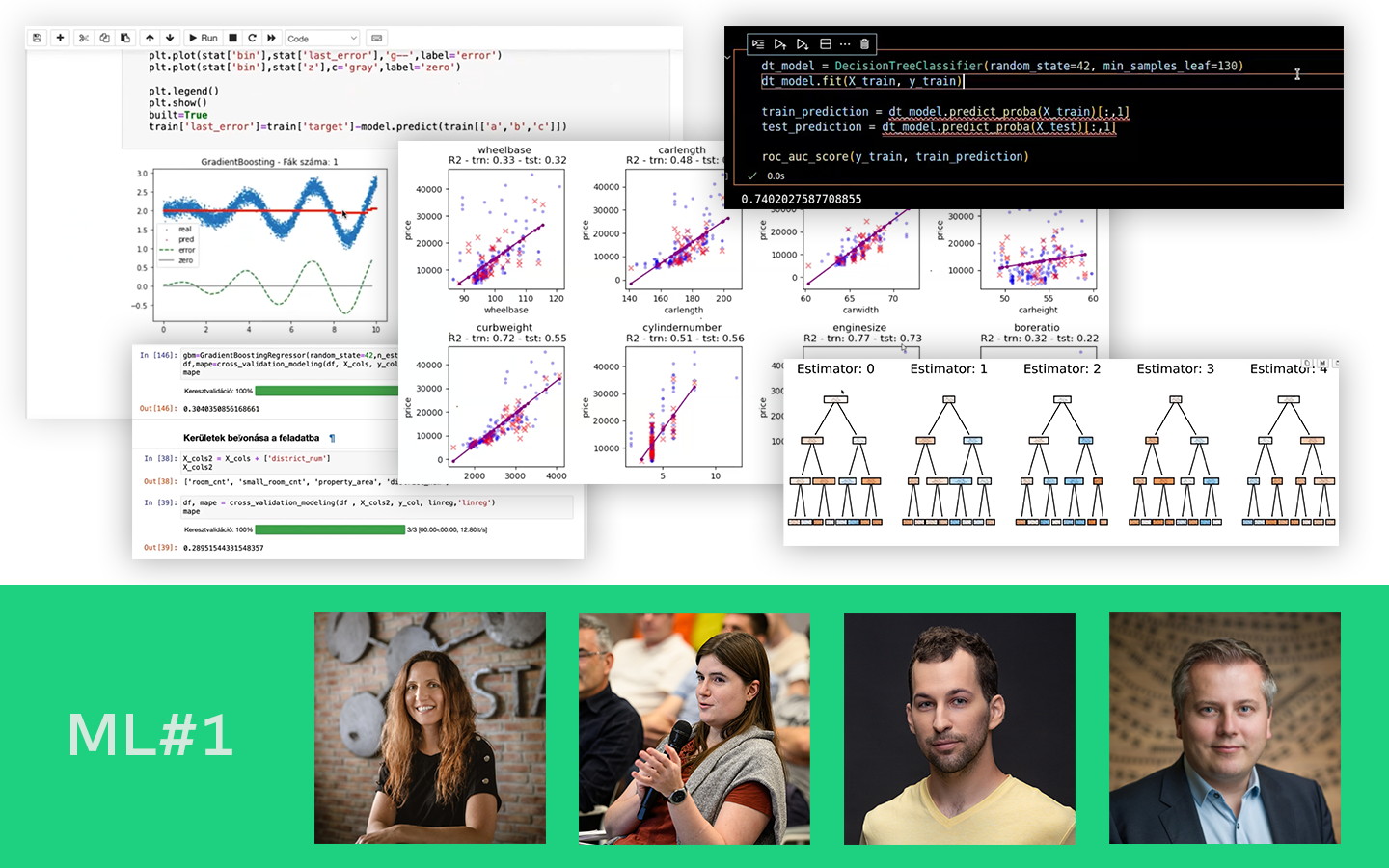
A „Lineáris Regresszió A-tól Z-ig” előadás megmutatja, miért több a lineáris regresszió egy gyorsan lefuttatható alapmodellnél: gépi tanulásos szemlélettel segít megérteni, hogyan épül fel, hogyan tanítható be, és hogyan kerülhetők el a tipikus buktatók, például a túltanulás, a multikollinearitás vagy a nemlineáris összefüggések félrekezelése. Böjte Berta (Senior Data Scientist) lépésről lépésre végigvezet az egyszerű és többváltozós modelleken, a regularizáció gyakorlati hatásán és a polinomiális regresszión. Mindezt Pythonban, Jupyter Notebookban követheted, a végén pedig érteni fogod a koefficiensek és metrikák jelentését, és kapsz egy letölthető, újrafuttatható kódalapot saját projektekhez.
Milyen főbb témákról van szó az előadásban?
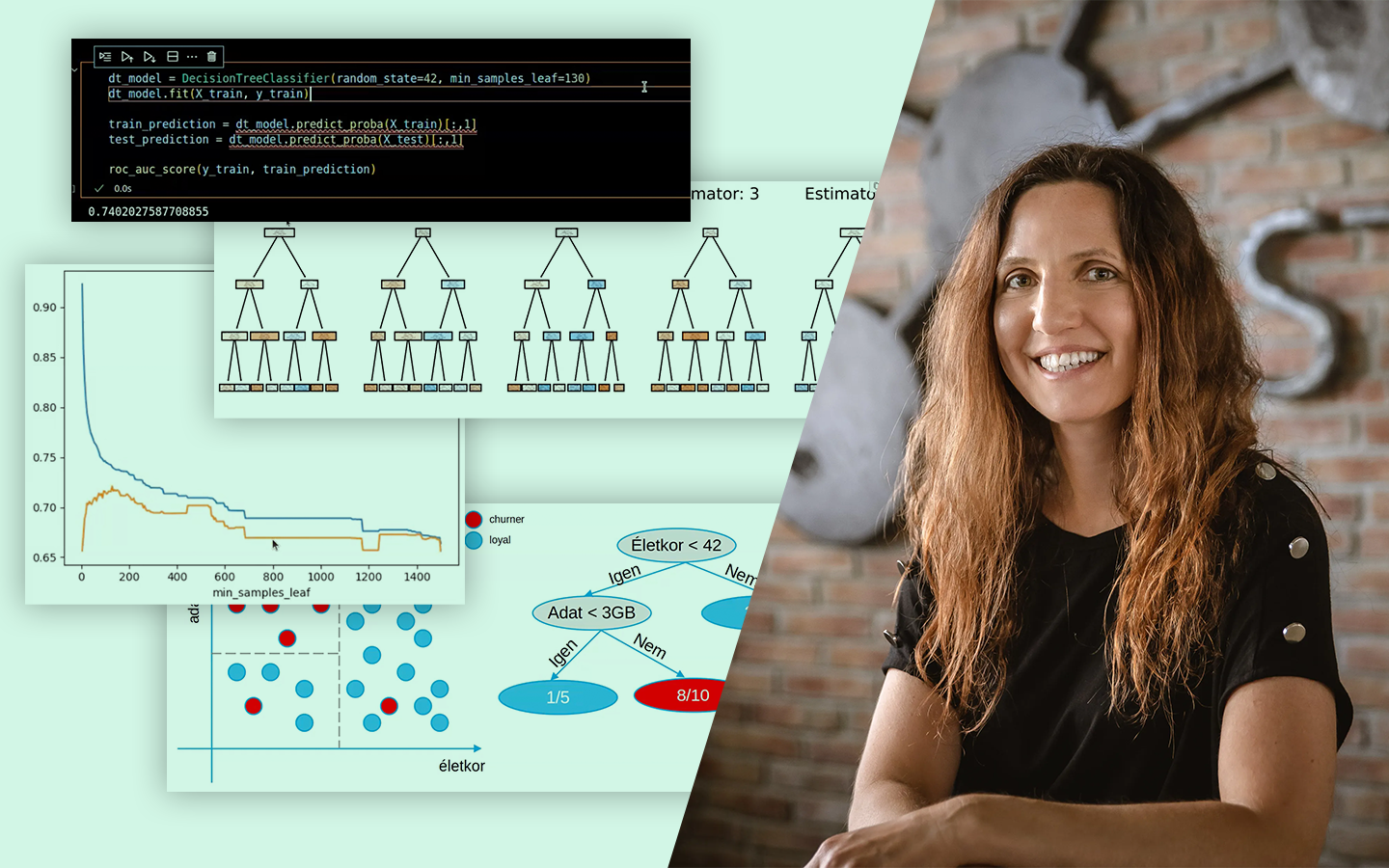
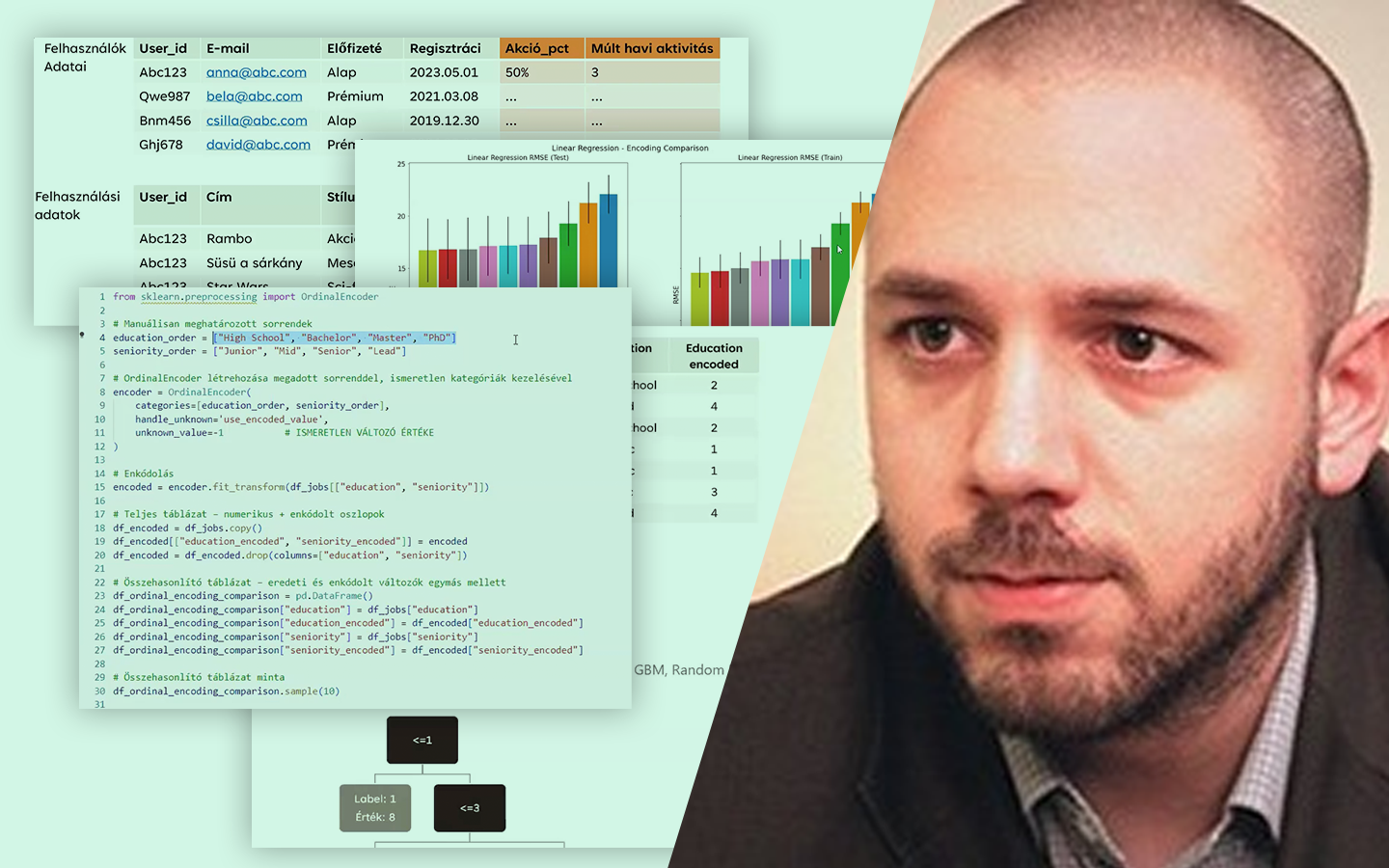
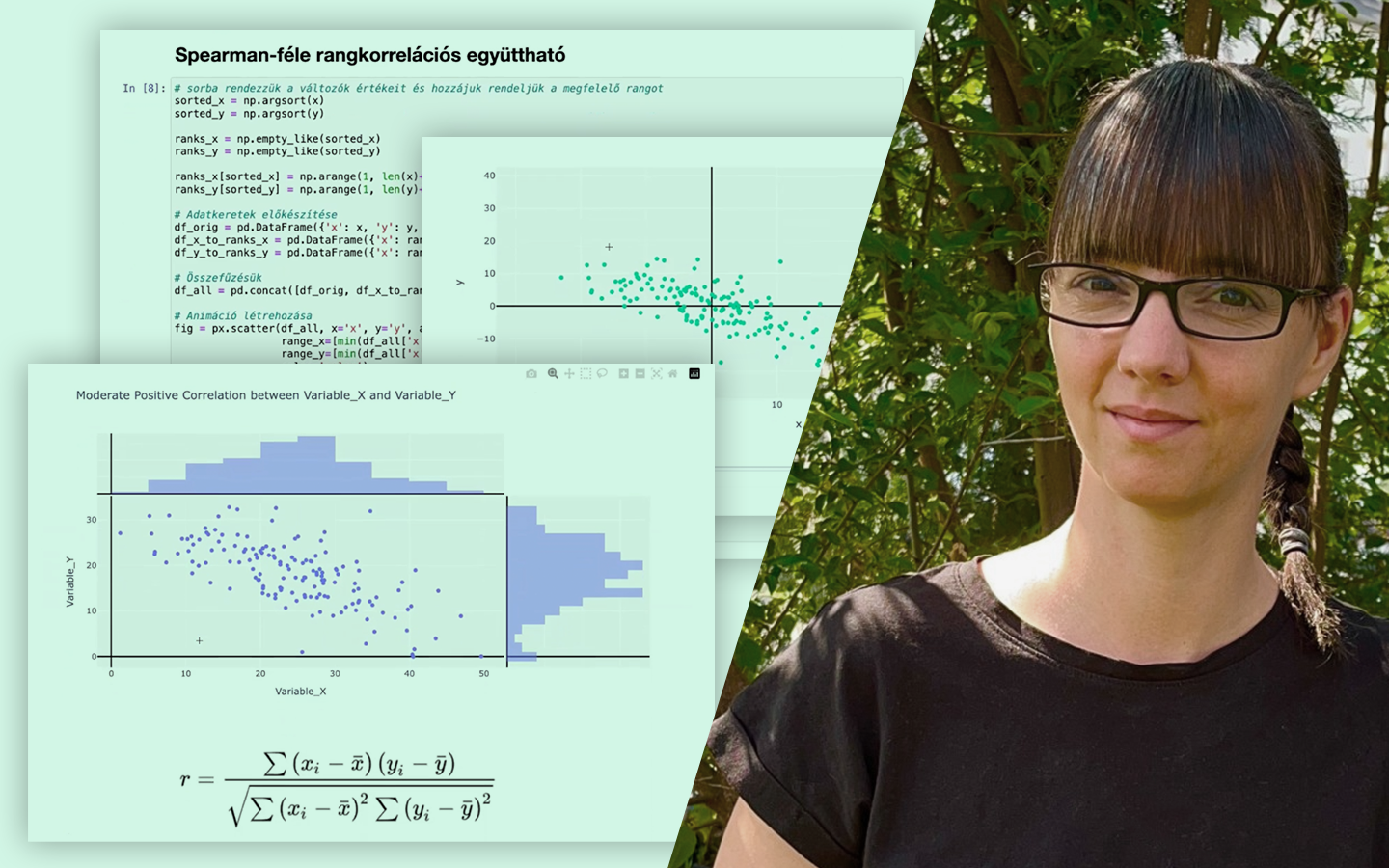
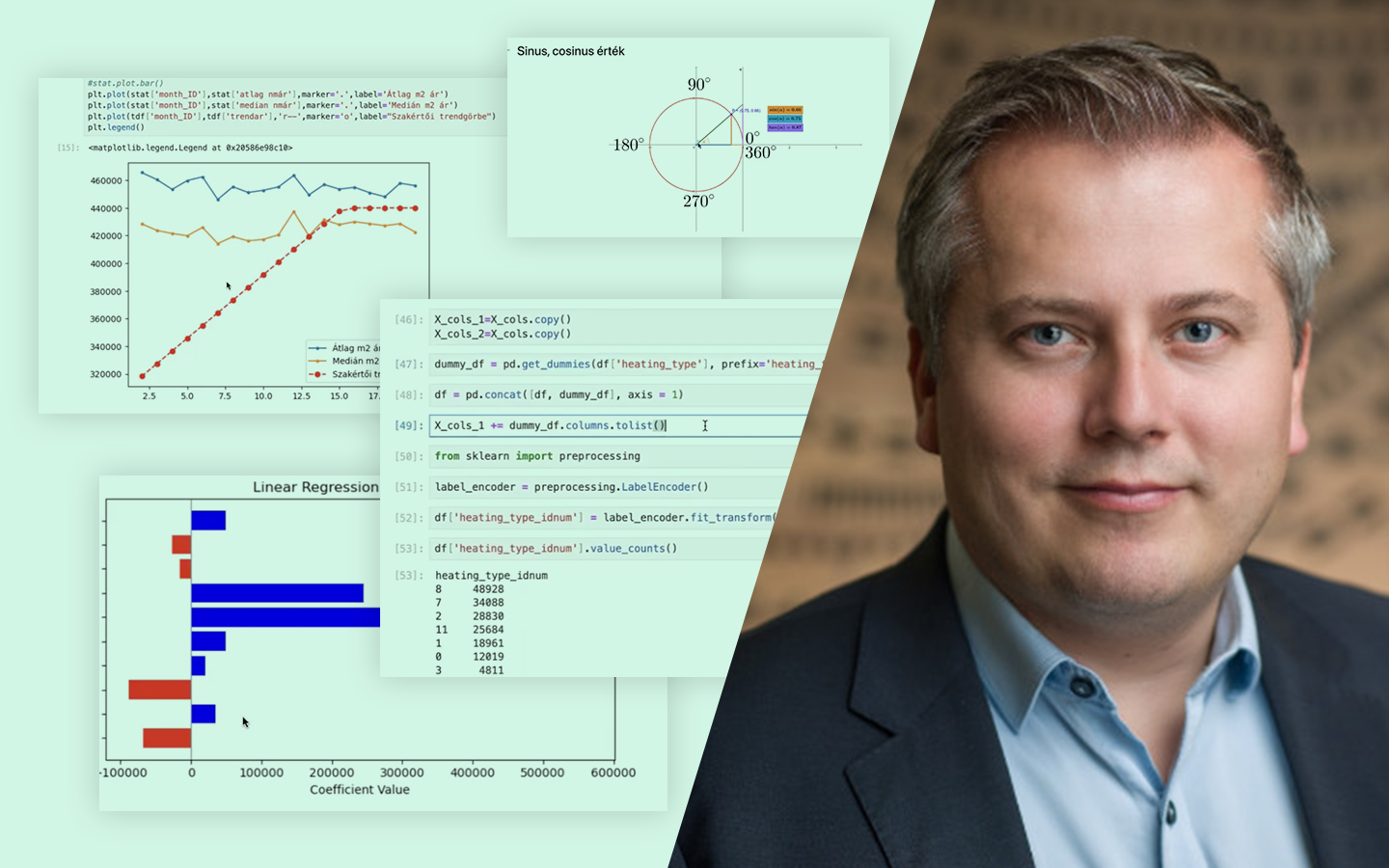
- Alapok és fogalmak tisztázása: célváltozó (Y), magyarázó változók (X), tengelymetszet (β0), koefficiensek (β), reziduumok/hibák. Mit jelentenek a gyakorlatban, és hogyan olvasd a modellt.
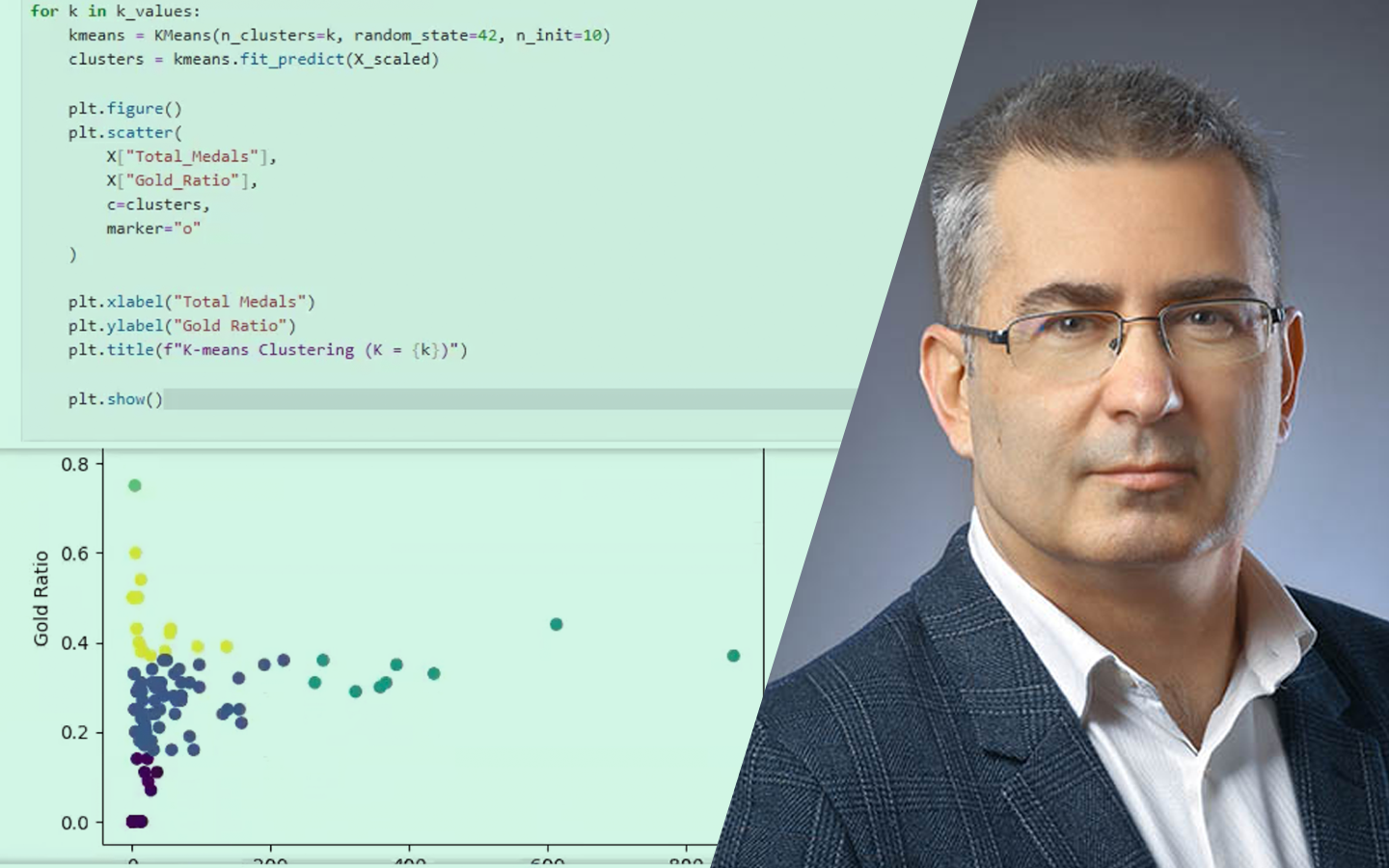
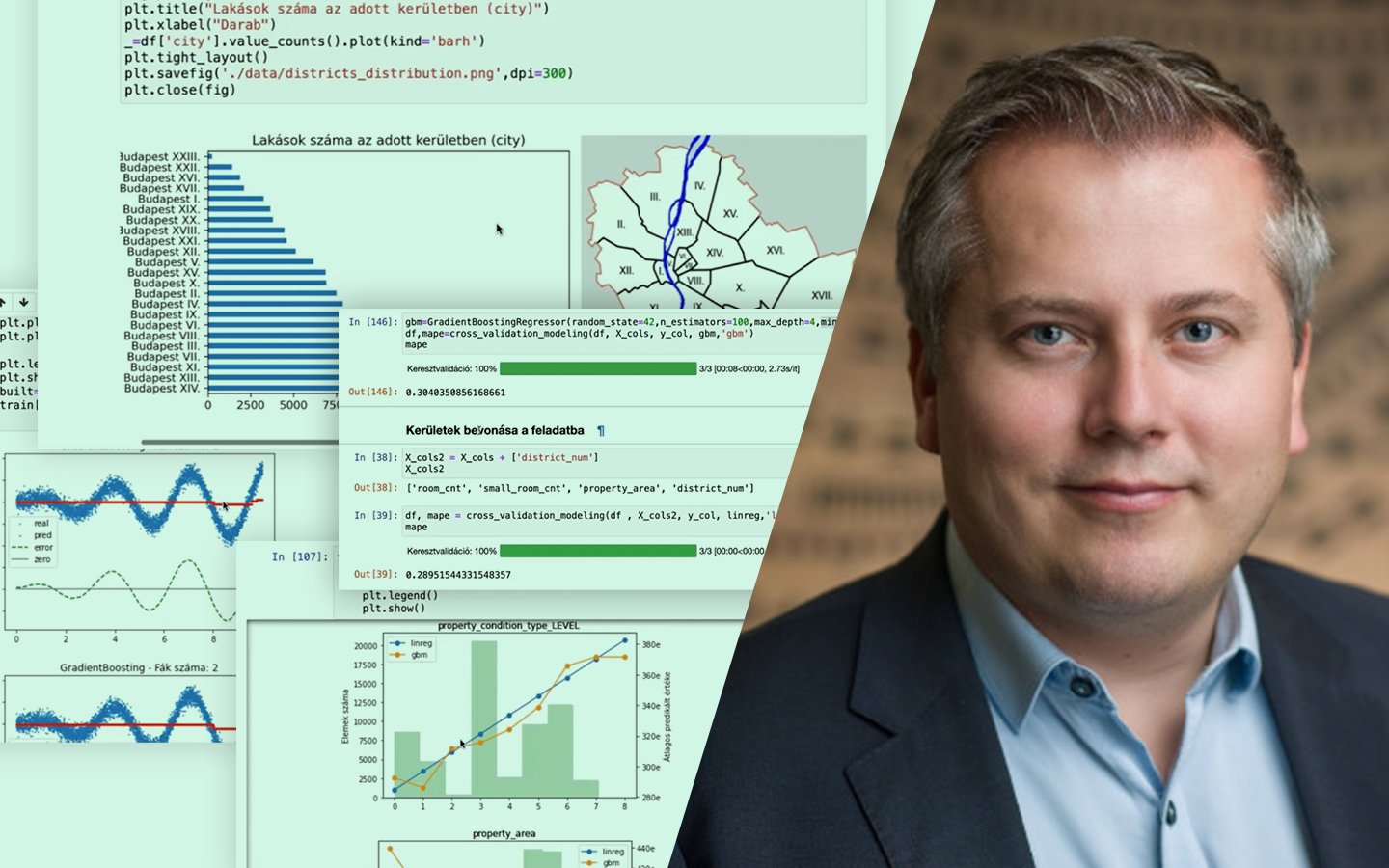
- Egyszerű vs. többváltozós lineáris regresszió: mikor elég egy változóval dolgozni, és mikor lesz a modell sík/hipersík több feature-rel – és miért ez a tipikus valós helyzet.
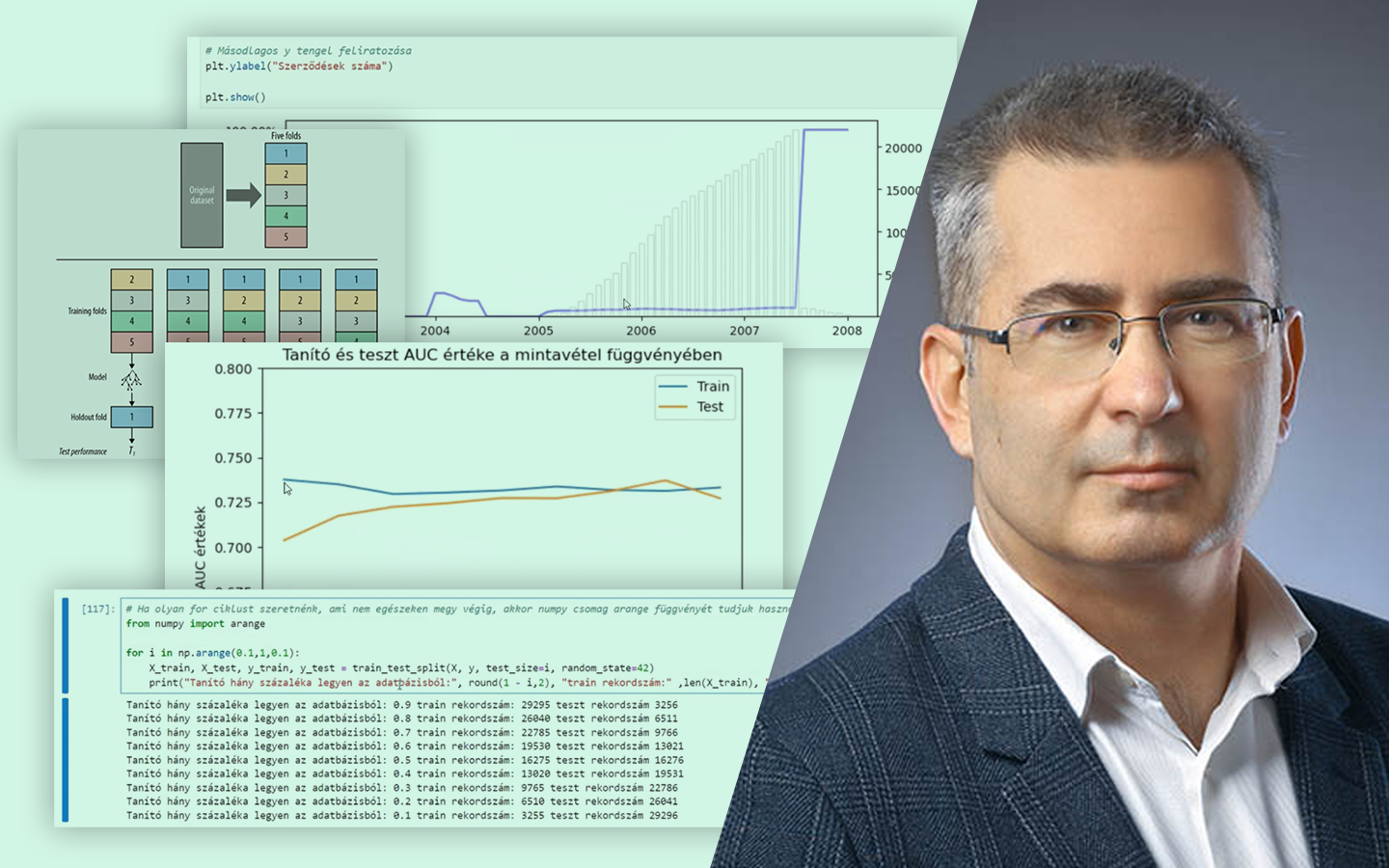
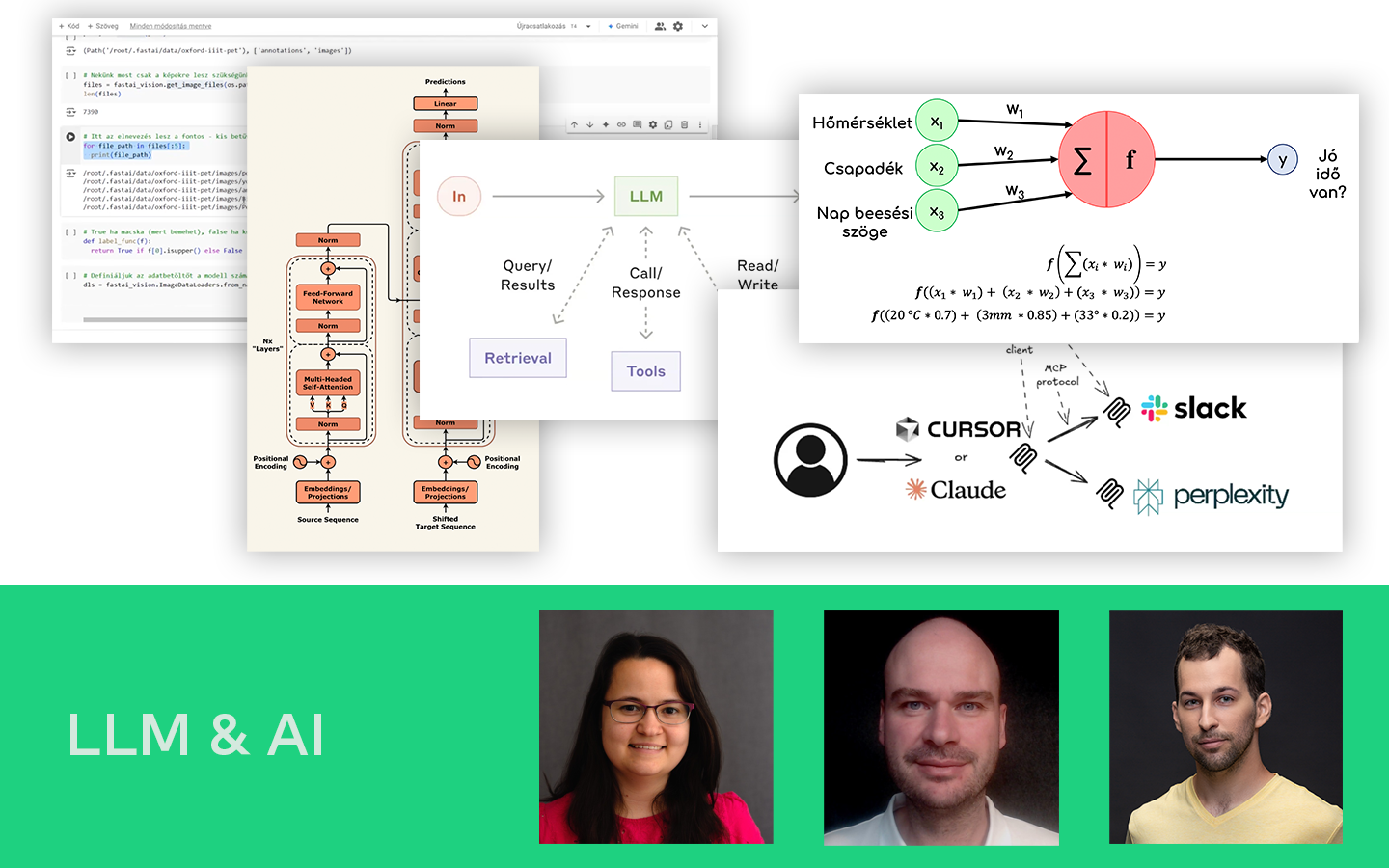
- Betanítás: OLS és gradiens alapú megközelítés: mit optimalizálunk (SSE/MSE), mikor működik jól a zárt képlet (OLS), és mikor érdemes iteratív módszerben gondolkodni (Gradient Descent).
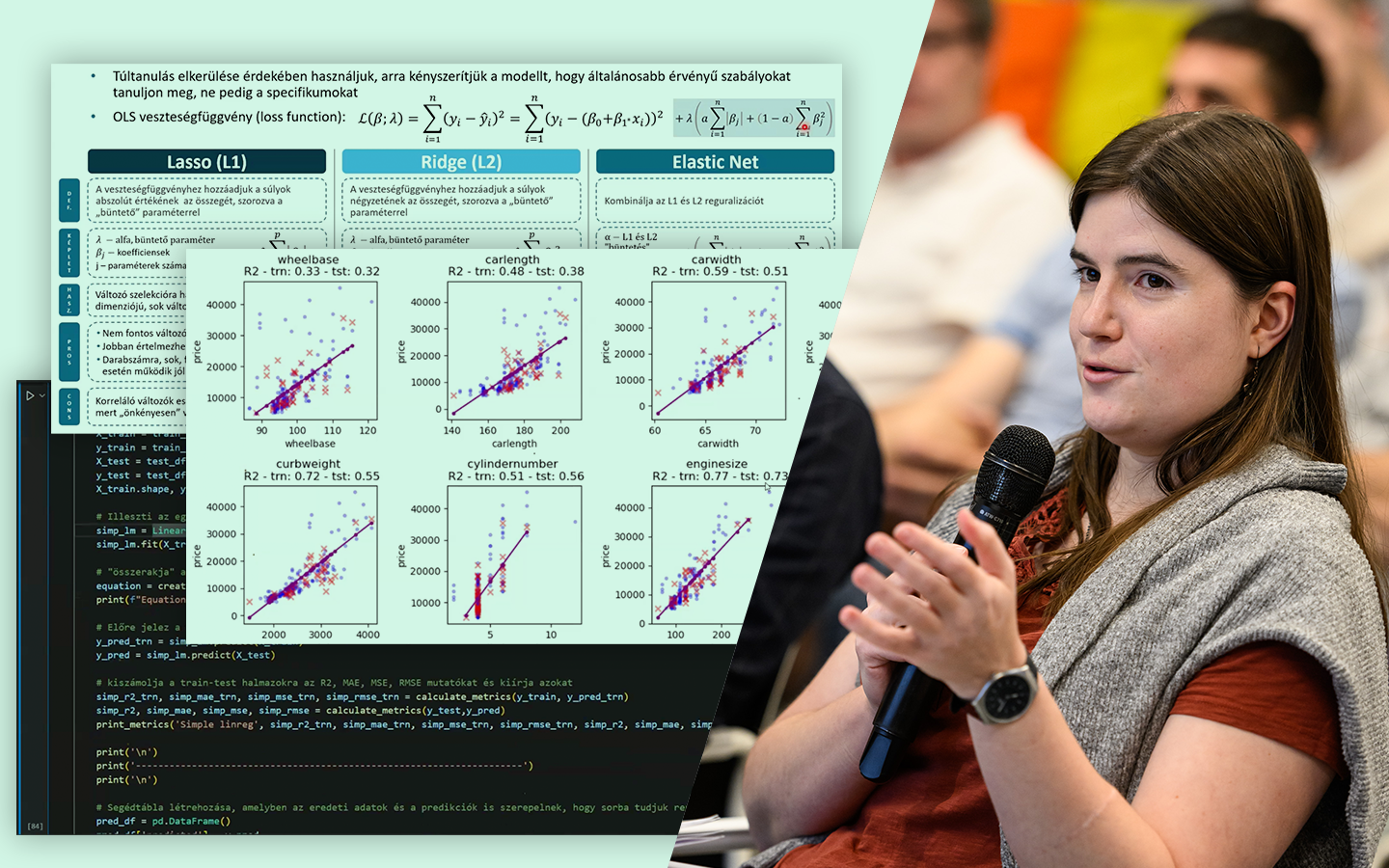
- Túltanulás kezelése regularizációval: LASSO (L1), Ridge (L2) és ElasticNet – mikor nulláz ki változókat, mikor „összenyomja” a súlyokat, és hogyan segít általánosíthatóbb modellt építeni.
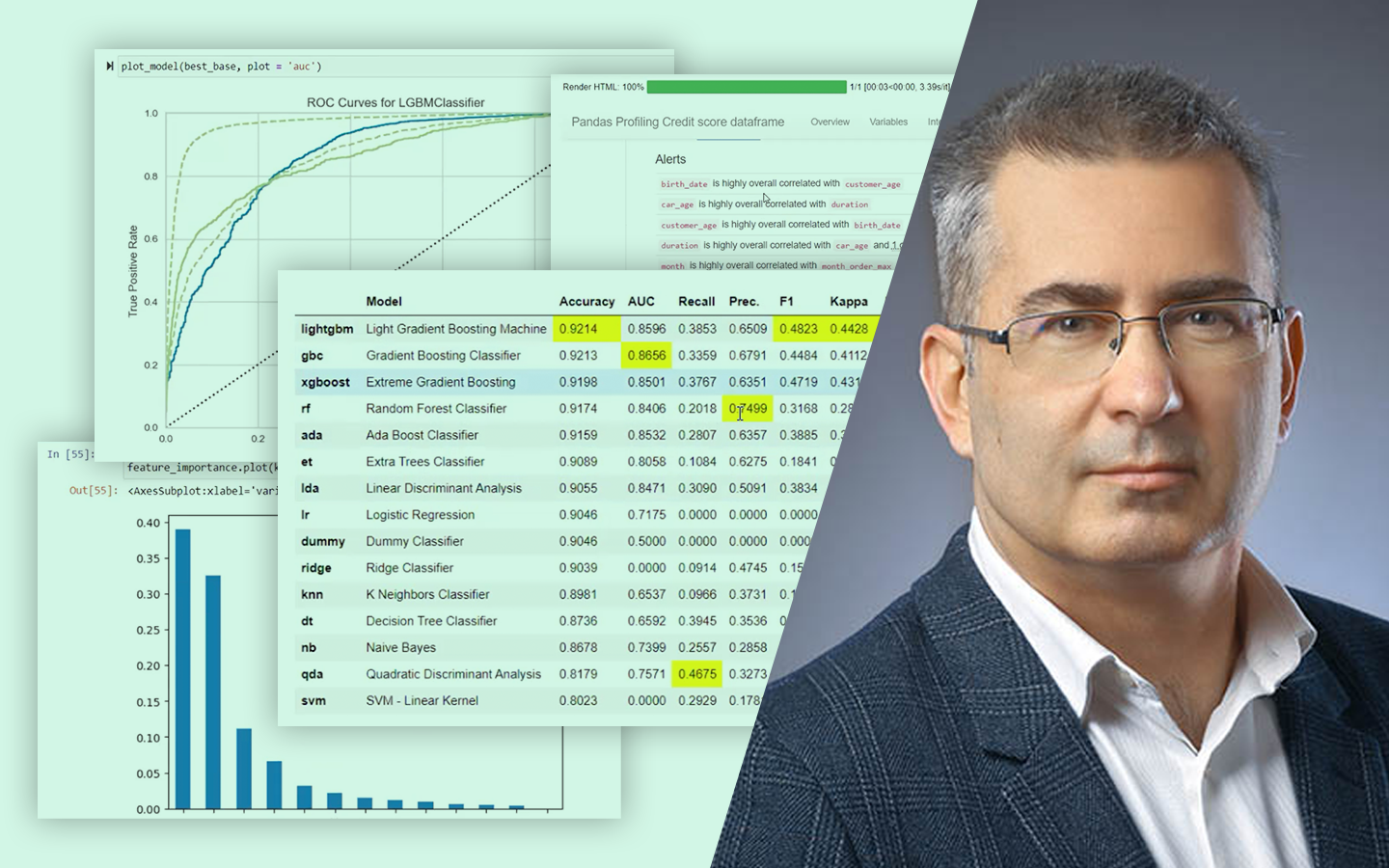
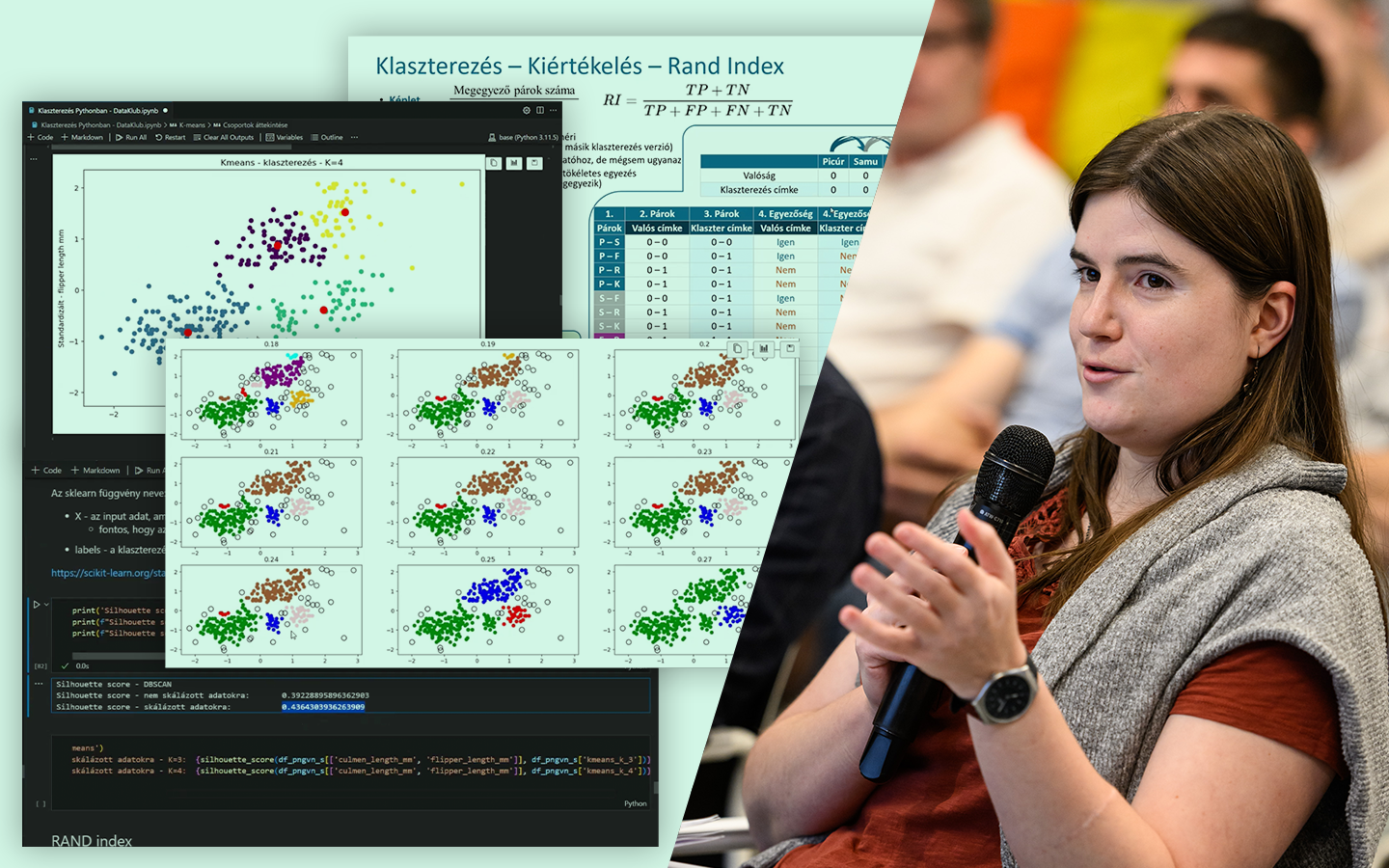
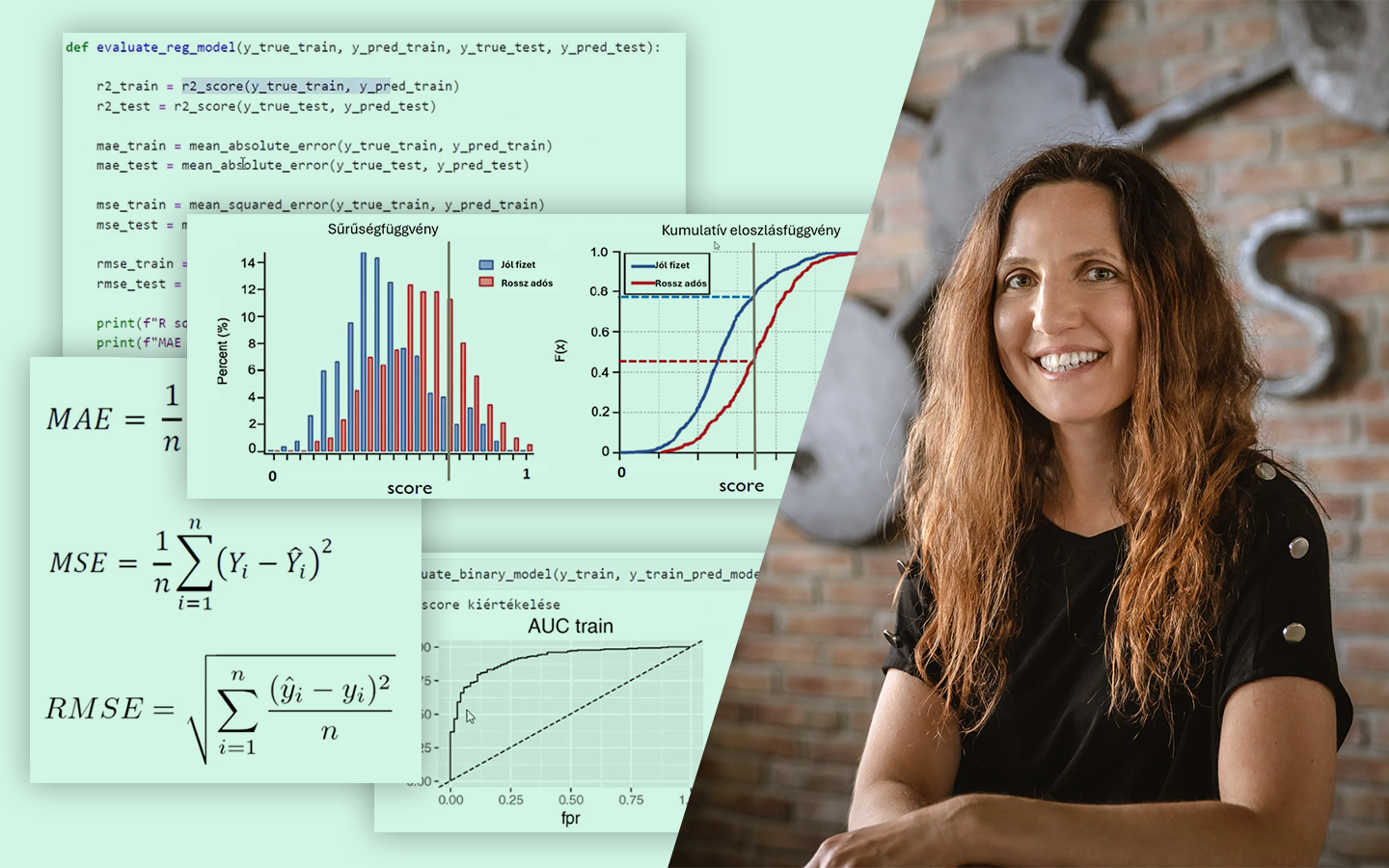
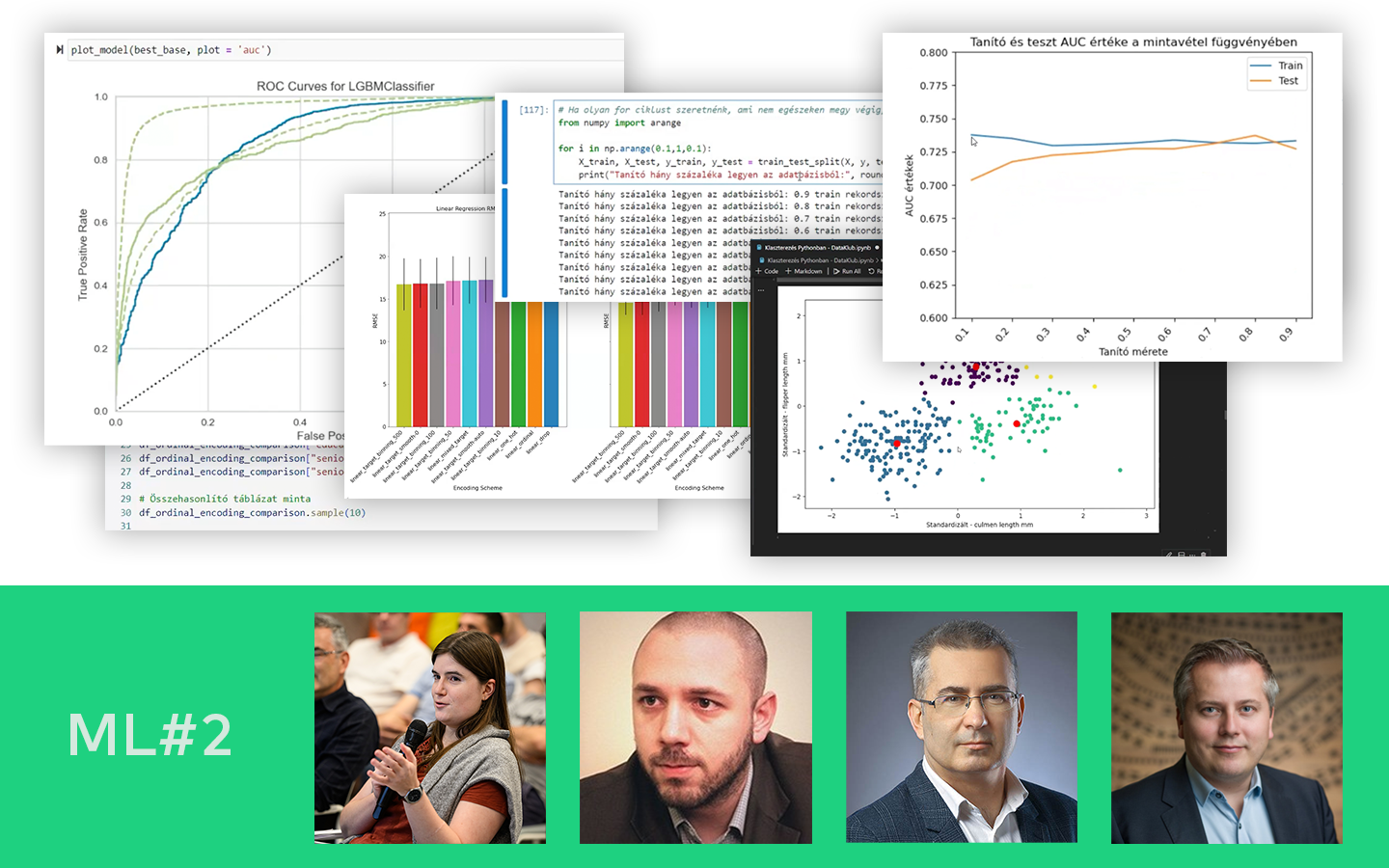
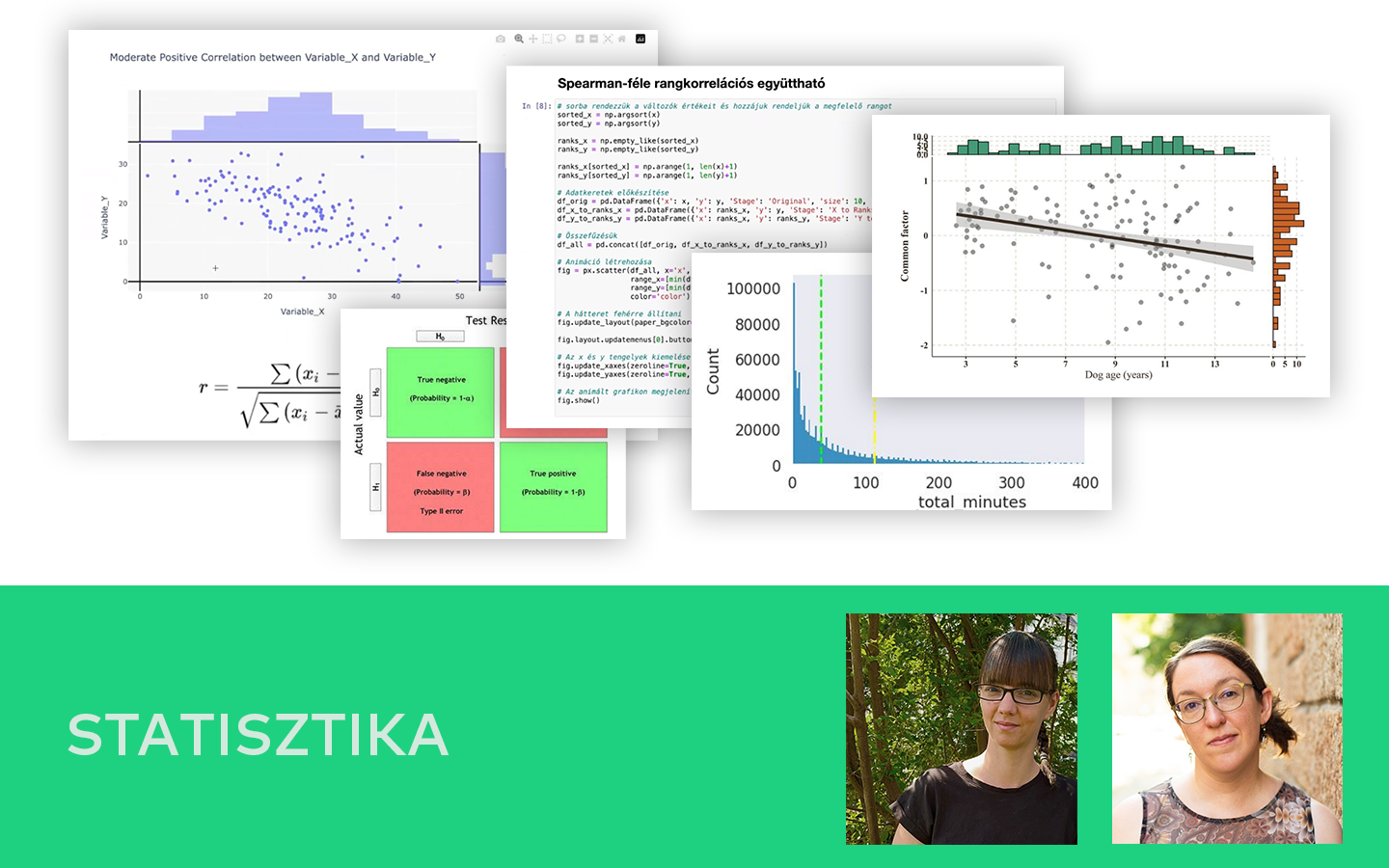
- Kiértékelés és metrikák: MAE, MSE/RMSE, R² – hogyan értelmezd őket tréning és teszt halmazon, és mire figyelj az összehasonlításnál.
- Polinomiális regresszió: mit tehetsz, ha a kapcsolat nem lineáris; hatványozott feature-ök, görbeillesztés, és a túltanulás kockázata.