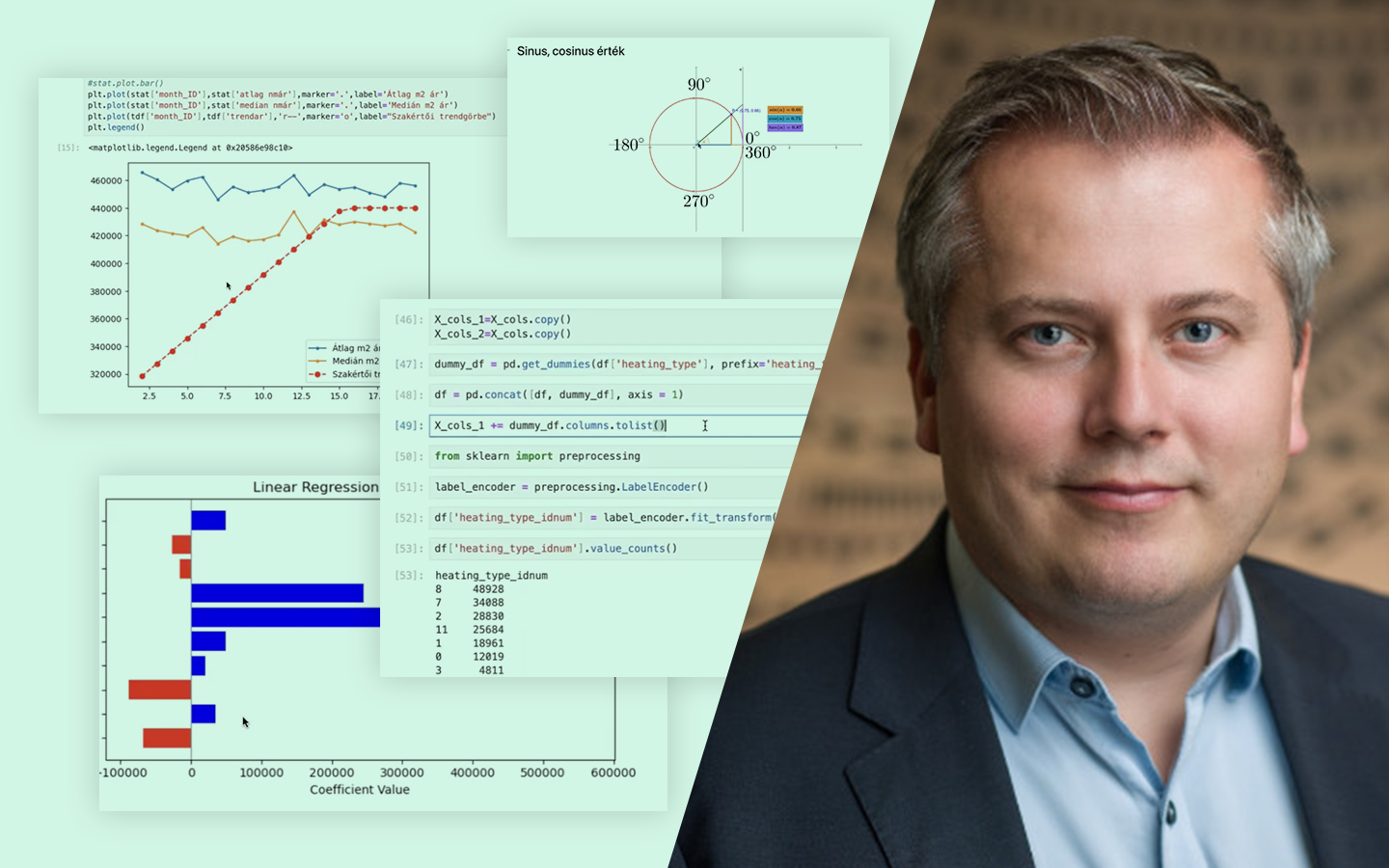
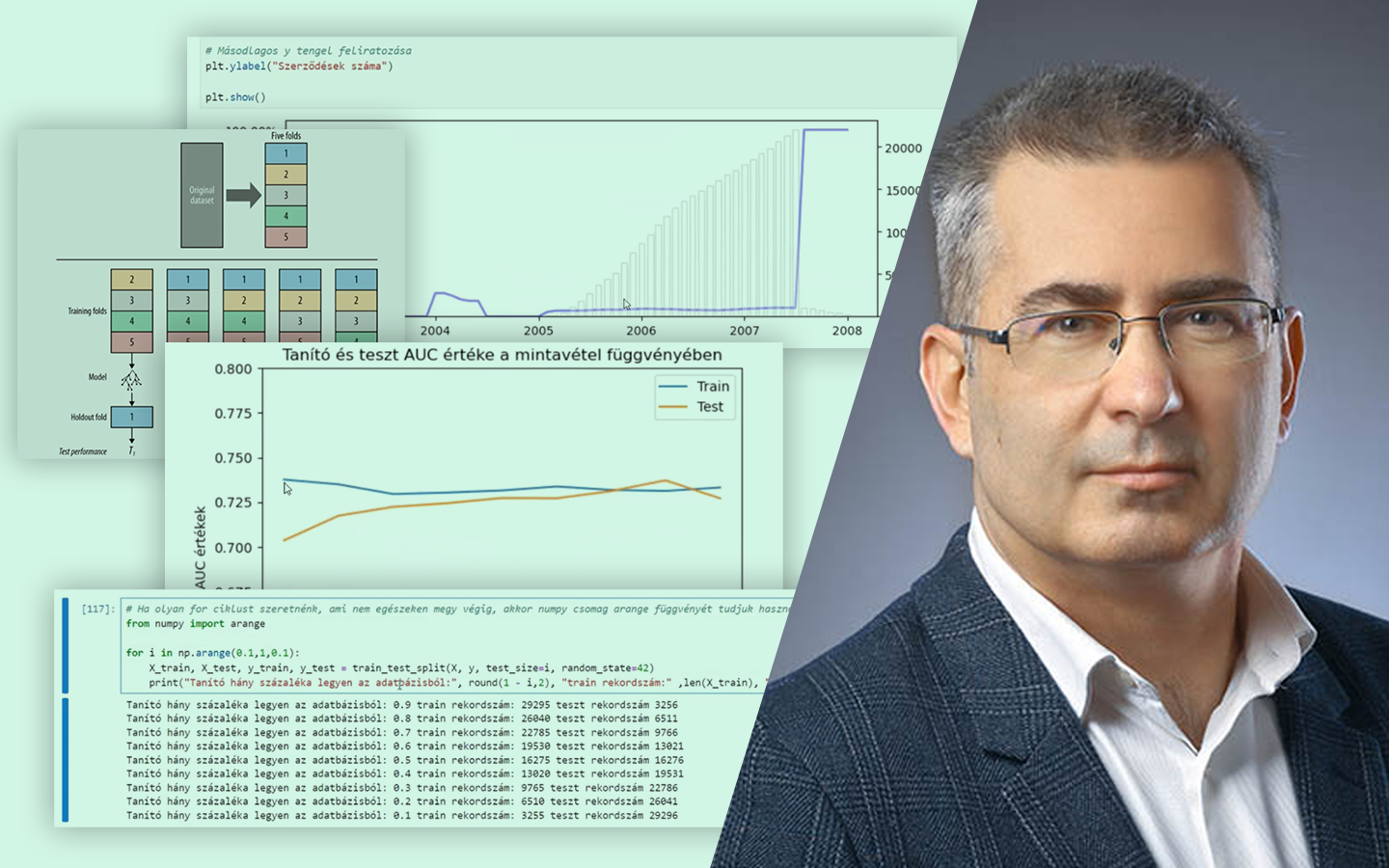
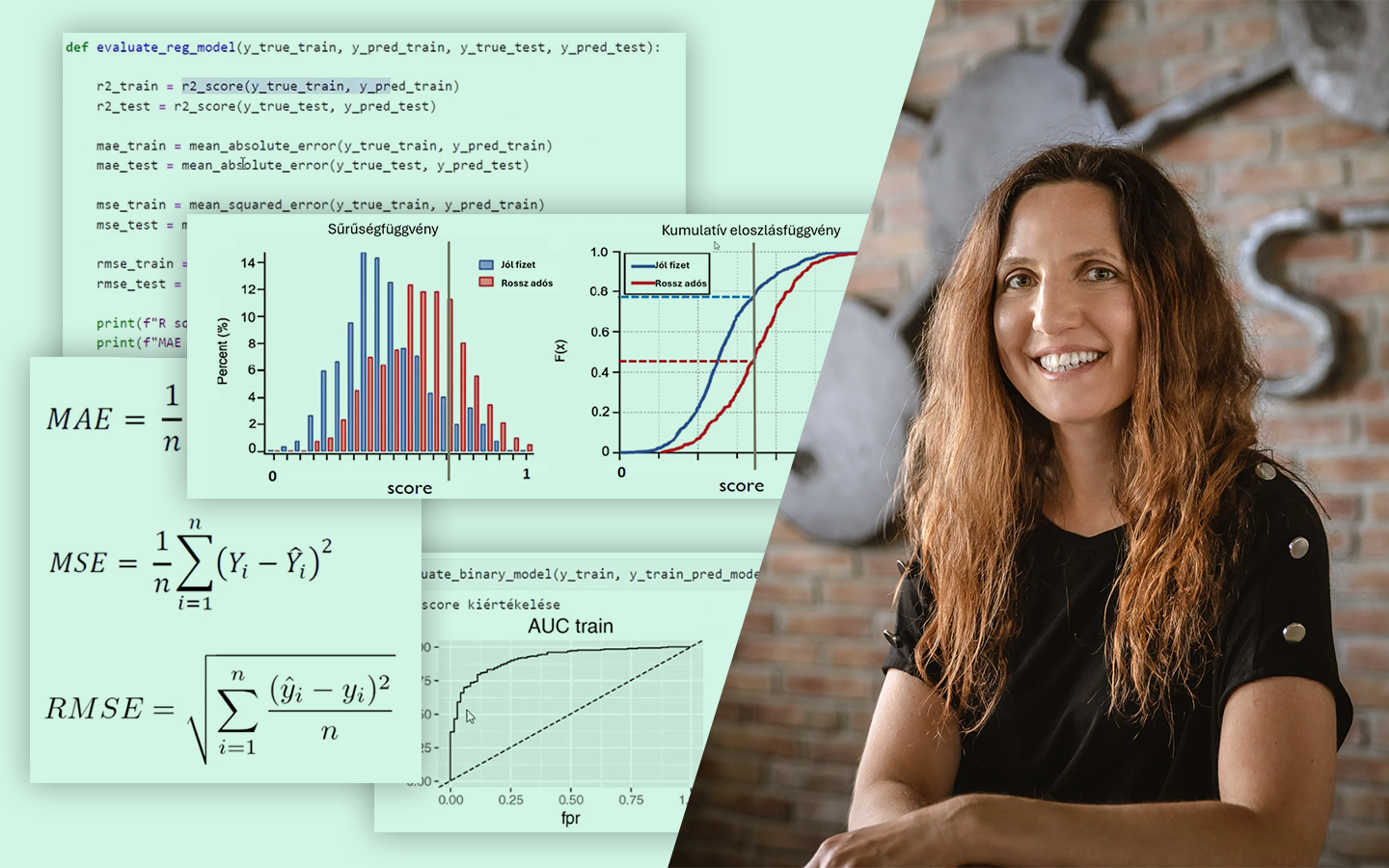
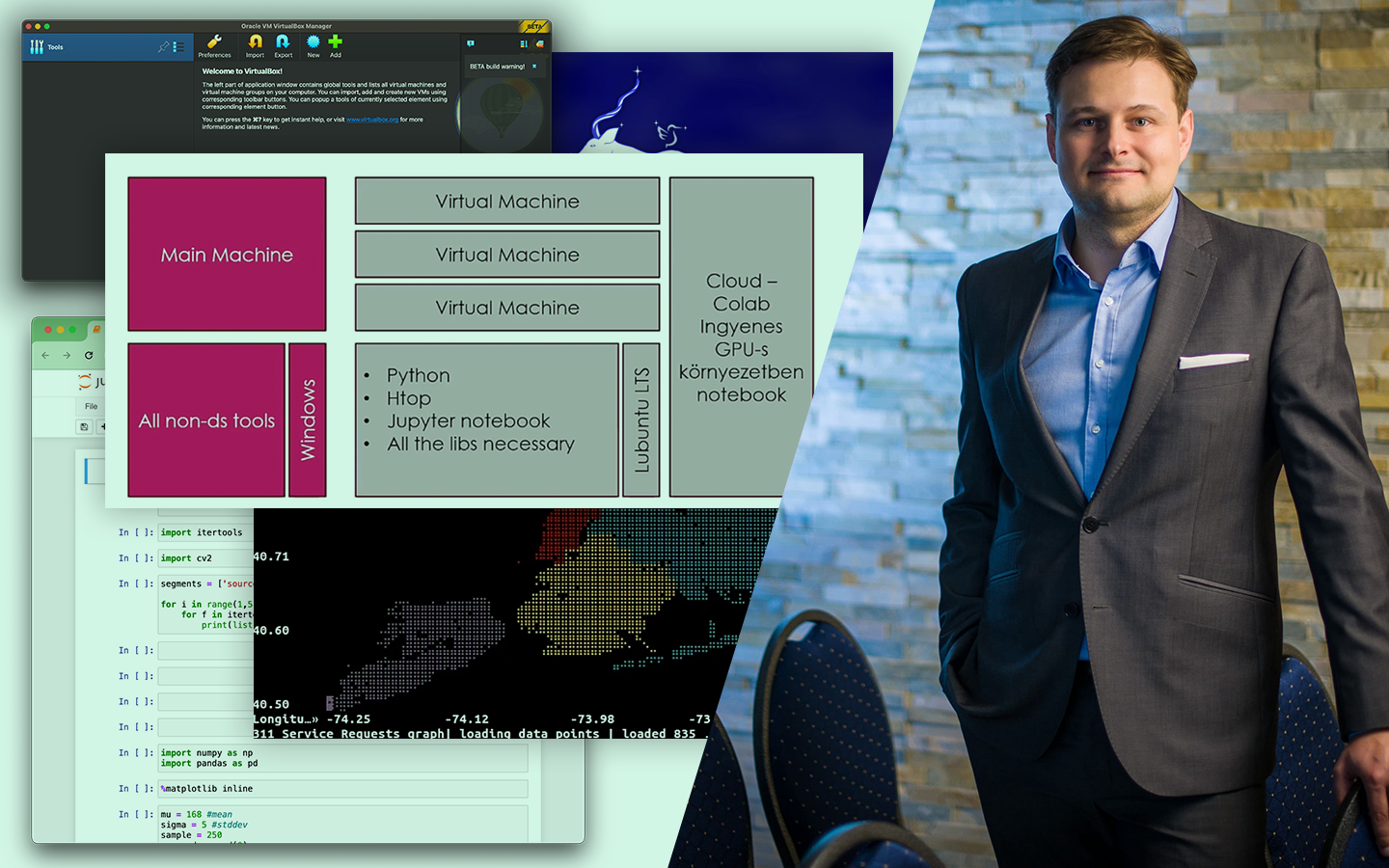
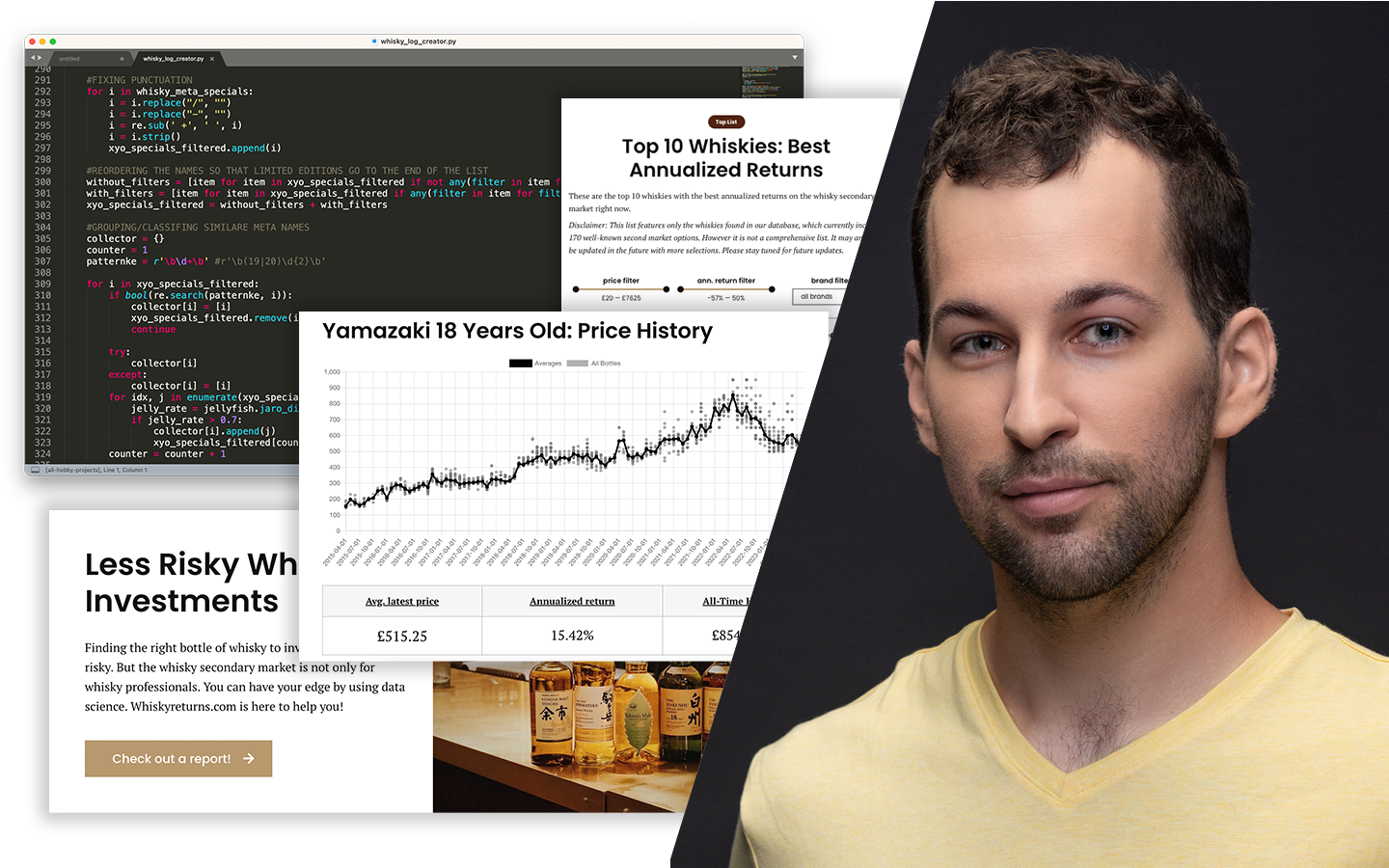
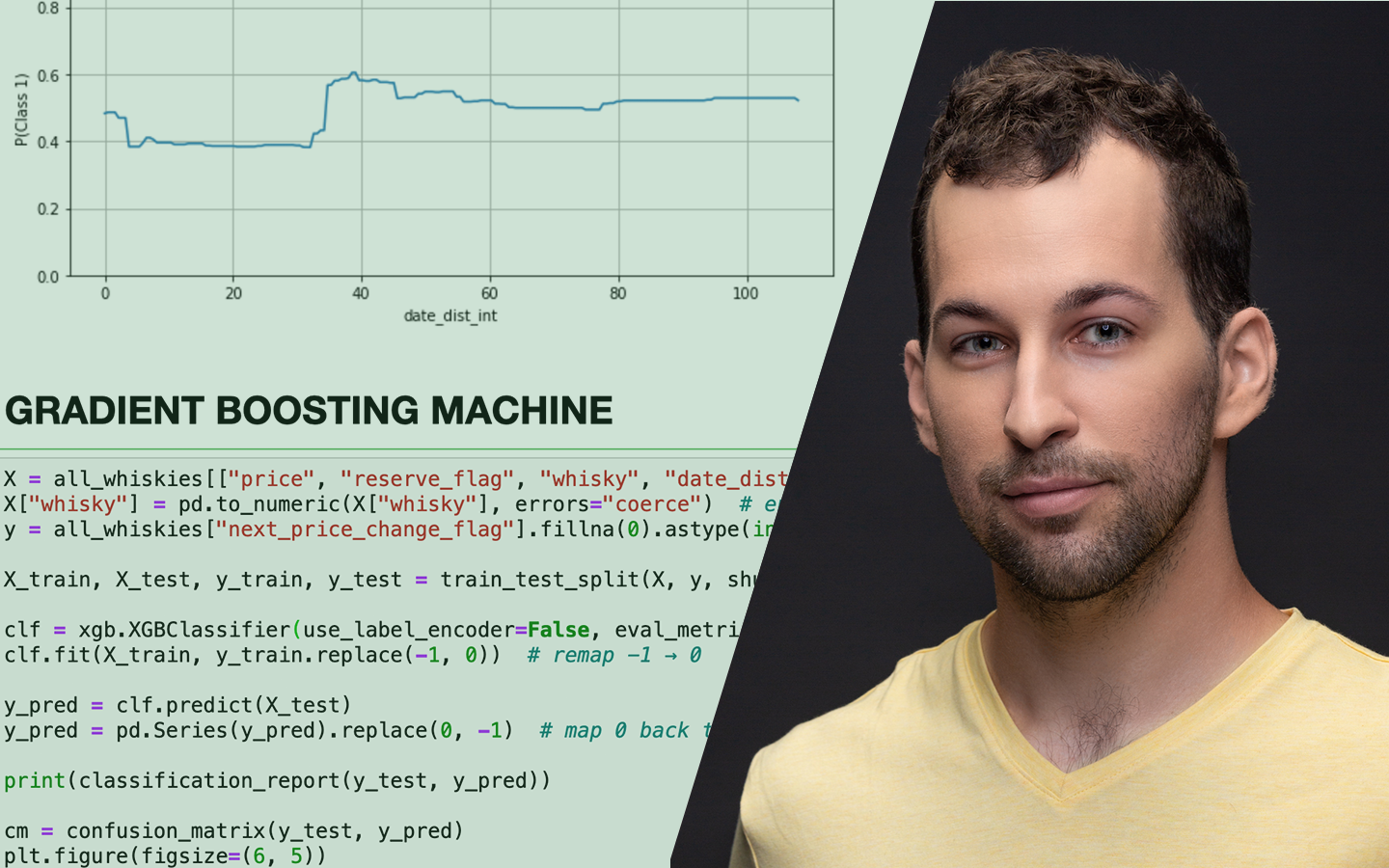
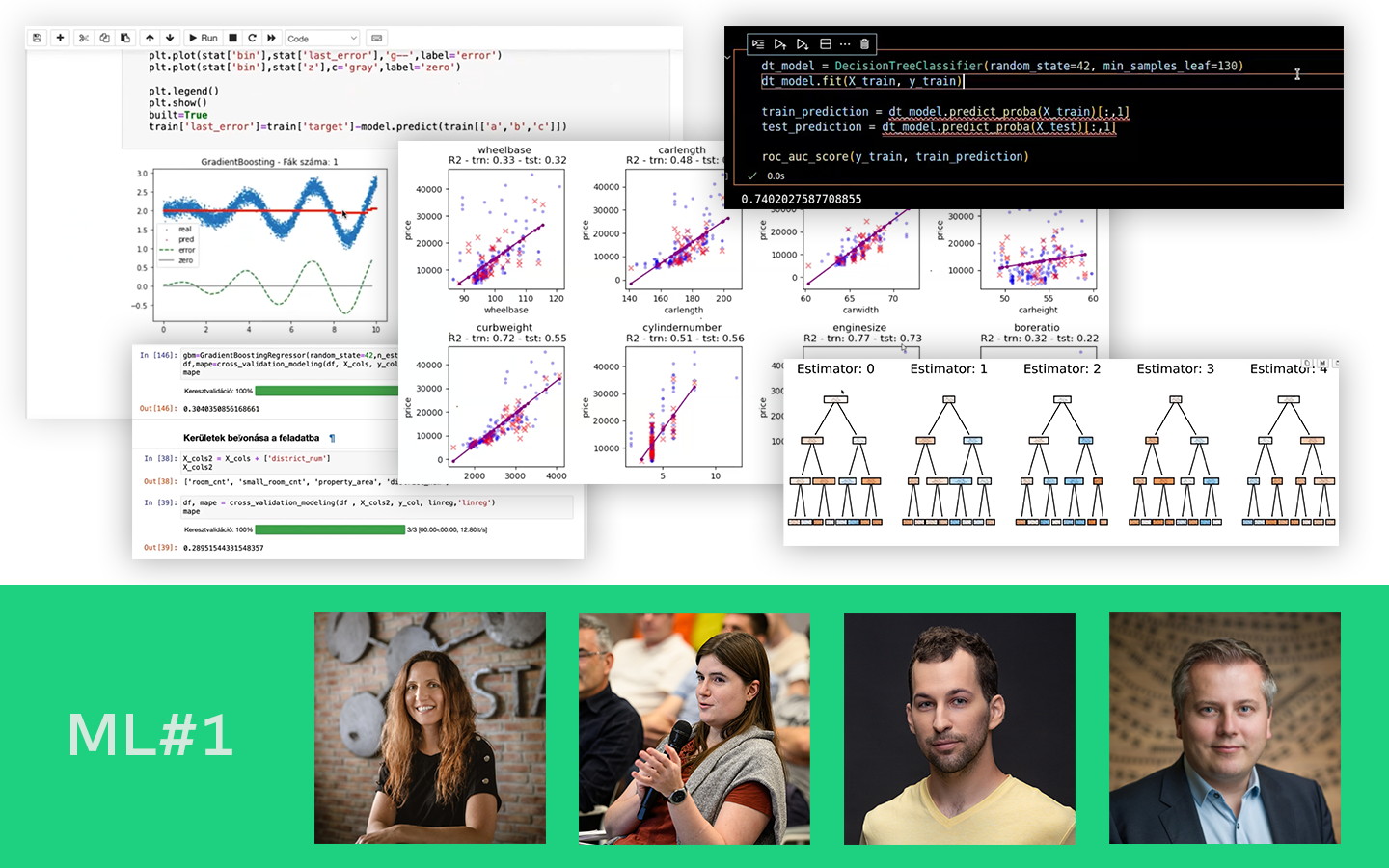
A „Klaszterezés Python-ban (koncepció, kódolás, esettanulmány)” előadás rendszerezi a nem felügyelt tanulás egyik leggyakoribb, mégis sokszor félreértett eszközét: hogyan találsz mintázatokat címkézetlen adatokban, és hogyan döntesz arról, hogy a kapott csoportosítás valóban hasznos-e. Böjte Berta (Senior Data Scientist, Starschema) a szükséges elméleti alapok után végigvezet a klaszterezés gyakorlati kérdésein: algoritmusválasztás, paraméterezés, távolságmértékek, skálázás és kiértékelés. A bemutatott lépések Pythonban is megvalósulnak, a Jupyter Notebook pedig letölthető lesz.
Milyen főbb témákról van szó az előadásban?
- A klaszterezés helye a gépi tanulásban: felügyelt vs. nem felügyelt tanulás, miért más a klaszterezés logikája, és miért nehezebb „visszamérni” az eredményt célváltozó nélkül.
- Gyakorlati felhasználások: mintázat- és struktúrafelfedezés, szegmentálás, vizualizáció támogatása, kilógó értékek (anomáliák) azonosítása, valamint egyszerűsítés „reprezentatív pontokkal”.
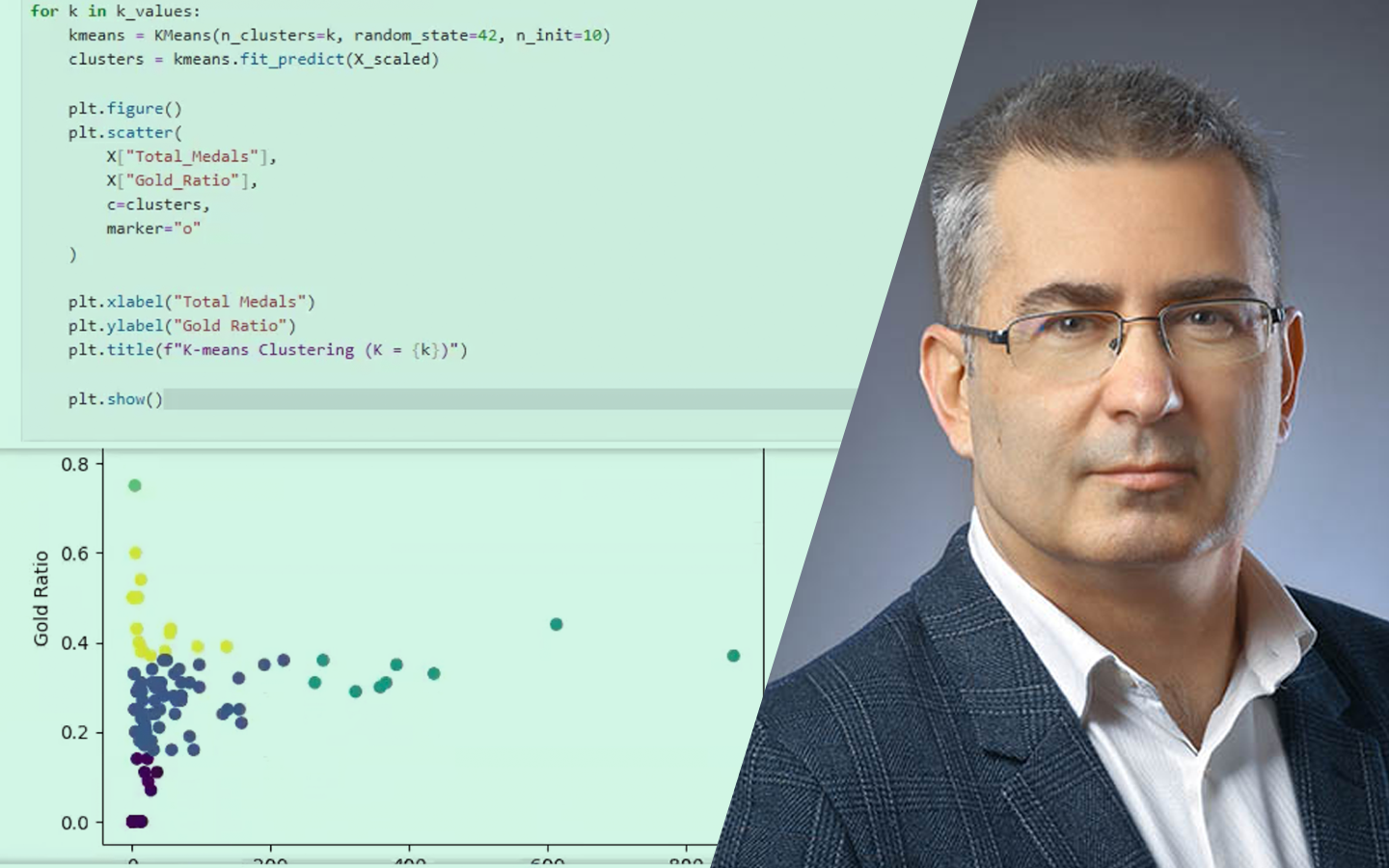
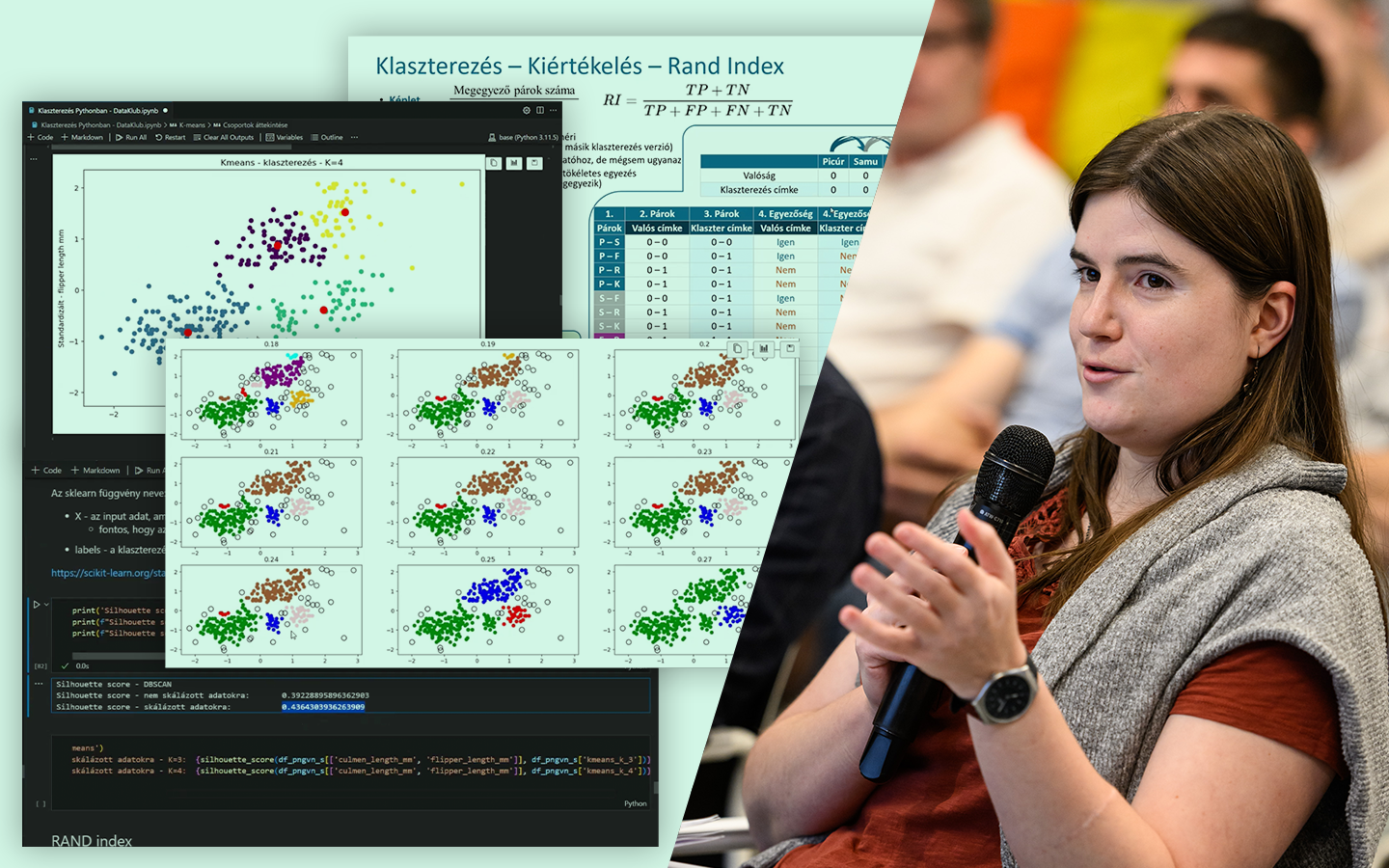
- Algoritmustípusok áttekintése, majd fókusz két módszeren: k-means (gyors és skálázható, de klaszterszámot igényel, érzékeny lehet kezdőpontokra és outlierekre) és DBSCAN (nem kell klaszterszám, kezeli a zajt/outliereket, de az epsilon és a minimum pontszám beállítása kritikus).
- Paraméterválasztás „könyök” módszerekkel: k-meansnél inertia/elbow, DBSCAN-nél k-távolság görbe.
- Távolságmértékek és skálázás: euklideszi, koszinusz és Manhattan távolság – mikor melyik működik jobban, és mikor szükséges a skálázás.
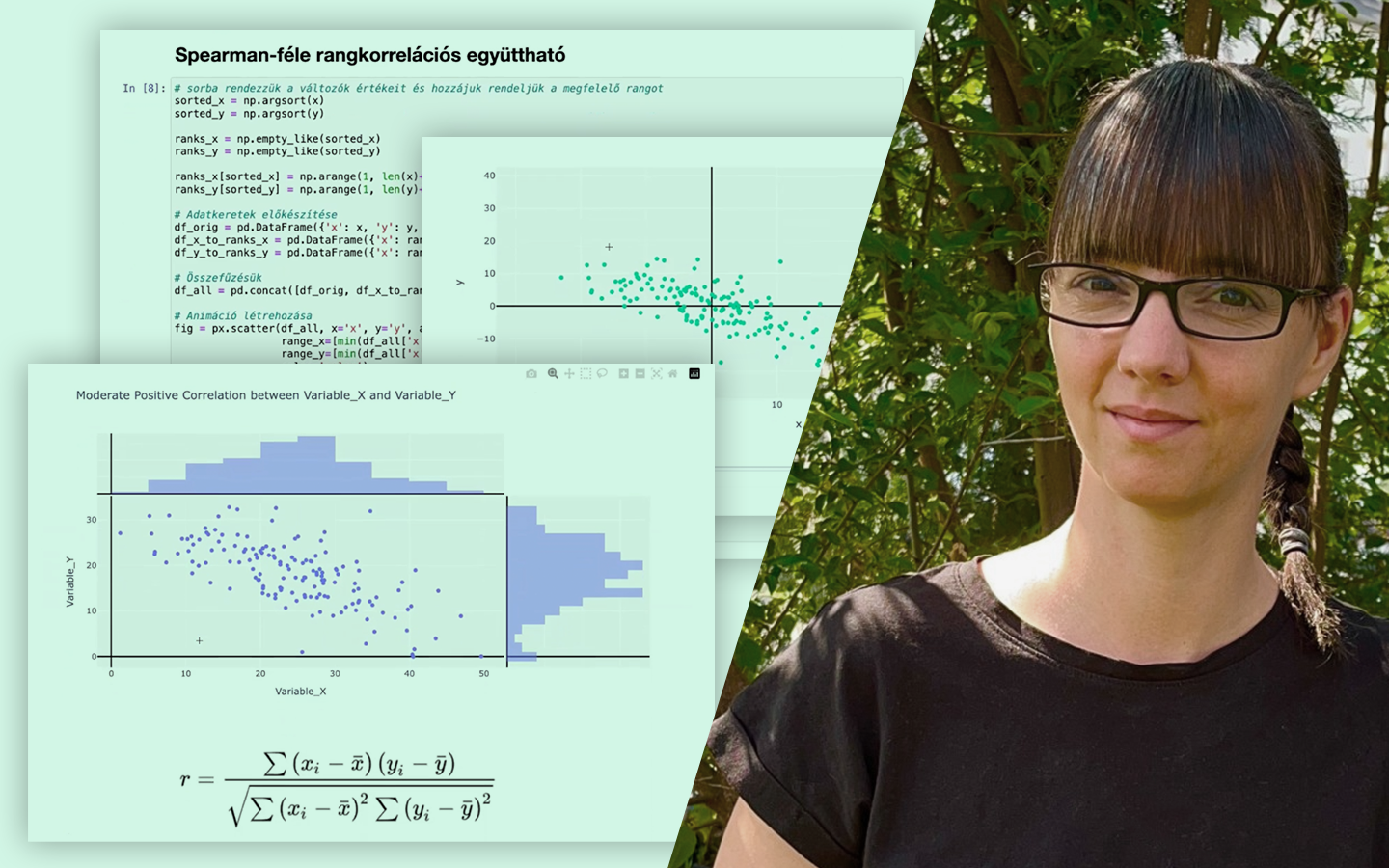
- Kiértékelés címkék nélkül is: belső metrikák (például silhouette score), illetve külső metrika, ha van „ground truth” (például Rand index).
- Pythonos bemutató: a koncepciók gyakorlati megvalósítása Jupyter Notebookban, amely letölthető lesz.