Ha szeretnéd érteni, mikor érdemes Random Forestet vagy GBM-et használni klasszifikációs feladatokra, ez az előadás gyorsan rendszerezi a lényeget. Windhager Eszter (Data Scientist, Onekey) valós autóhitel-adatokon, Python-kóddal mutatja meg, hogyan jutsz el az intuíciótól a működő, kiértékelt modellekig. Nemcsak az algoritmusok működését követheted végig, hanem a köztük lévő gyakorlati különbségeket is: pontosság, túltanulás, értelmezhetőség és paraméterezés szempontjából. Megnézzük, hogyan épül fel egy modell, hogyan mérhető a teljesítménye, és mire figyelj, hogy megalapozottan dönthess arról, melyik megközelítés illik jobban a saját feladatodhoz.
Milyen főbb témákról van szó az előadásban?
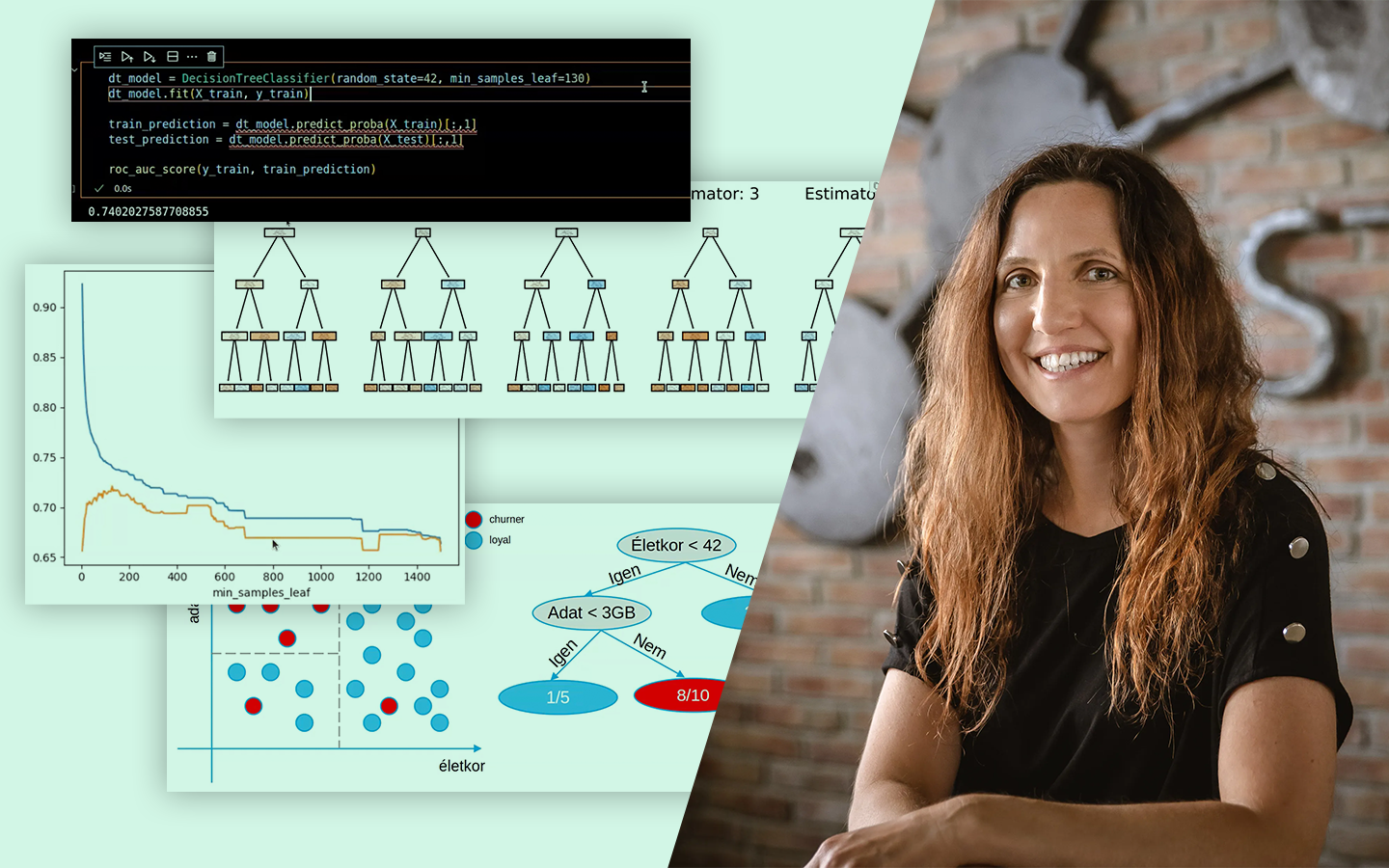
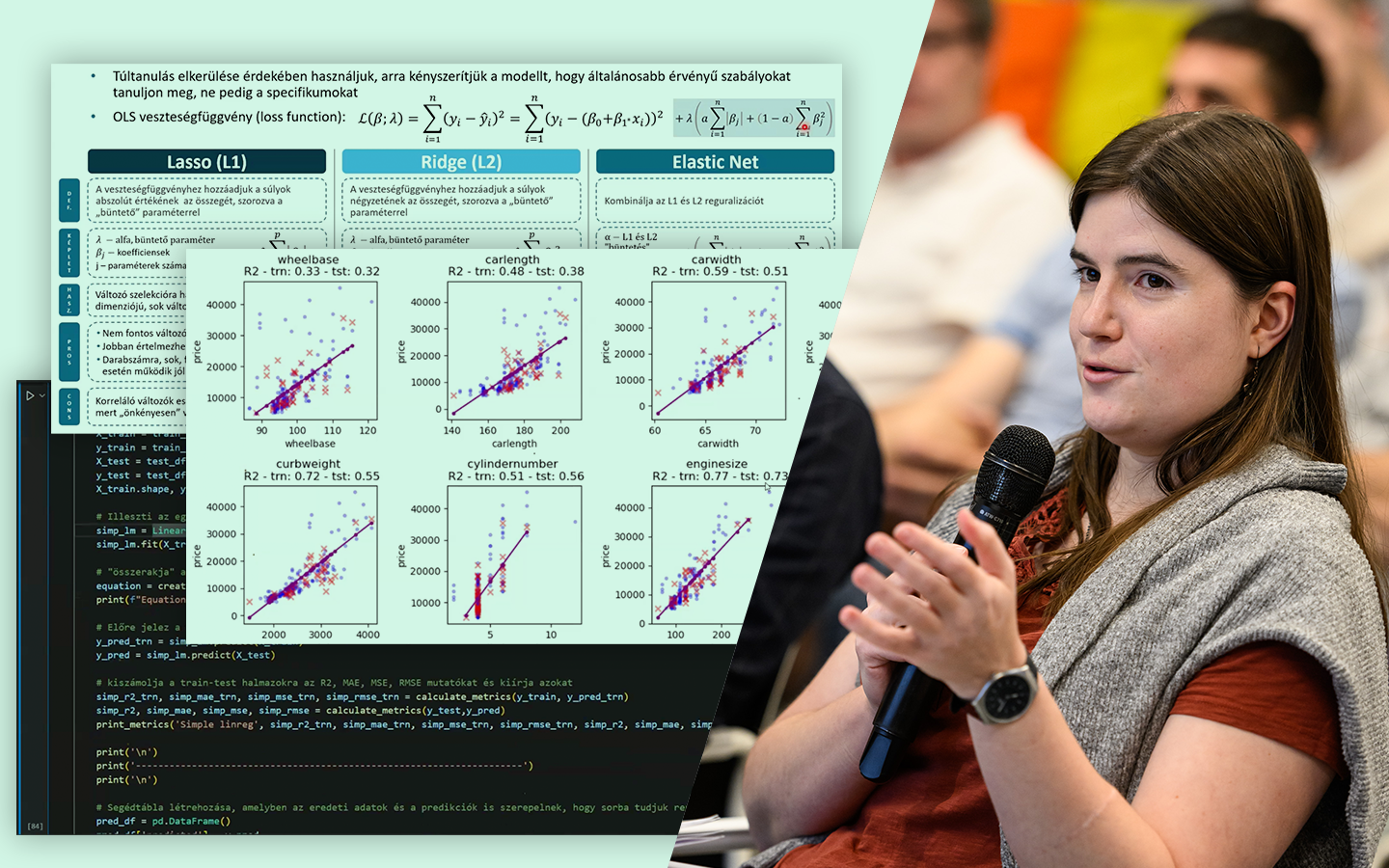
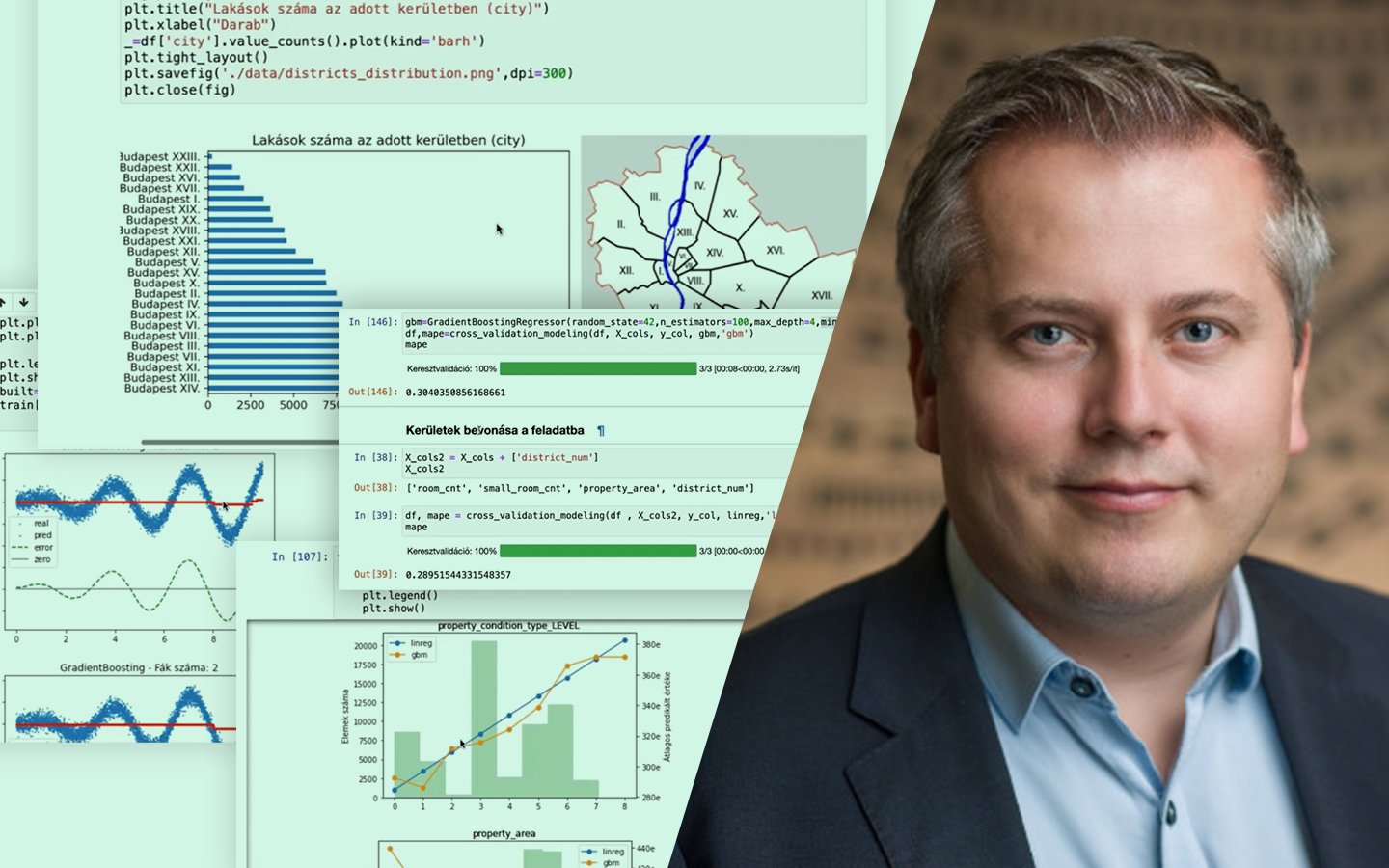
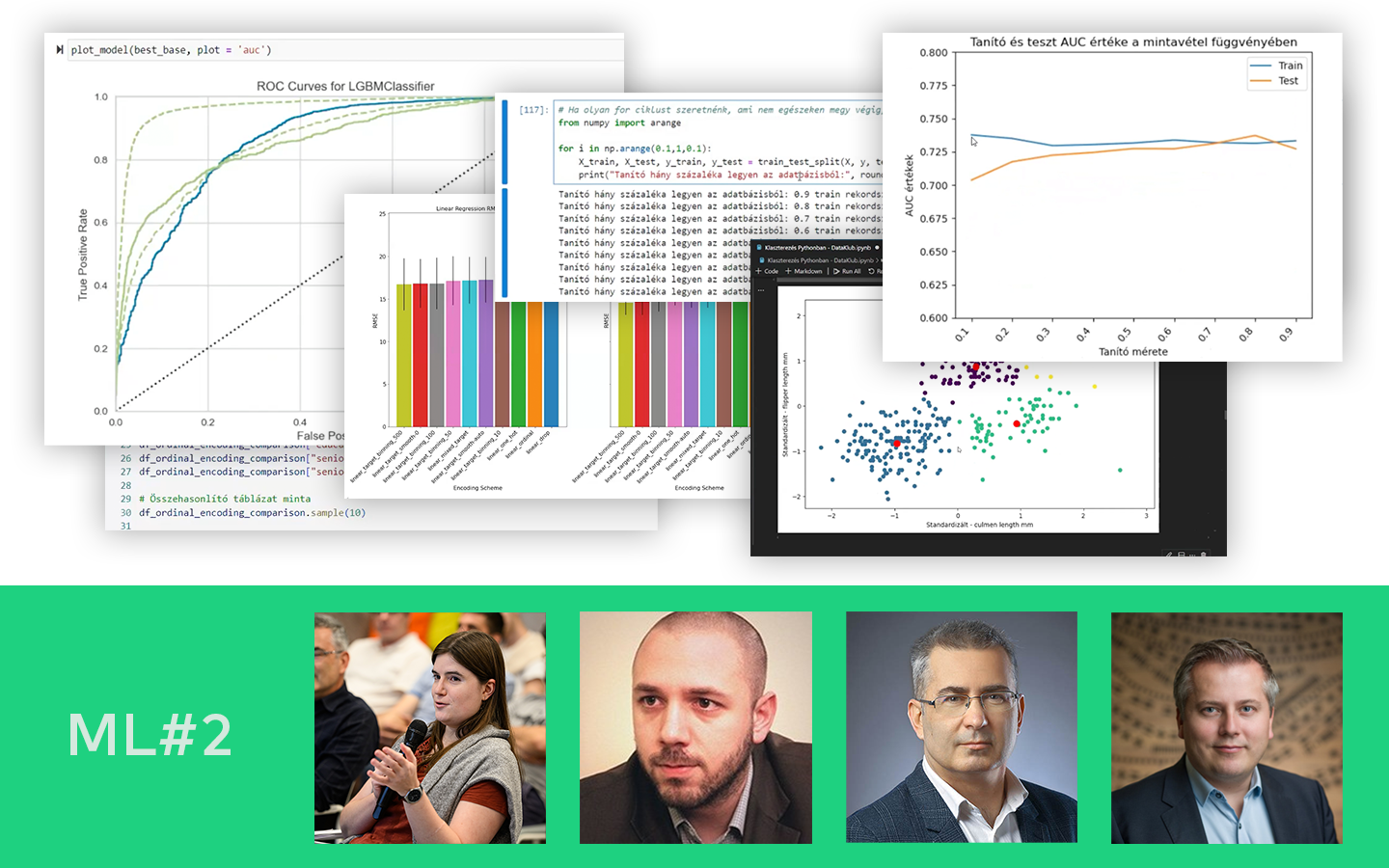
- Bináris klasszifikáció valós adaton, Pythonban: a gyakorlati folyamat bemutatása autóhitel példán, a probléma megértésétől a kiértékelt modellekig.
- Klasszifikációs alaphelyzetek üzleti példákkal: tipikus döntési szituációk, mint a hitelbírálat (default igen/nem) és a lemorzsolódás (churn), ahol a cél egy kategória előrejelzése.
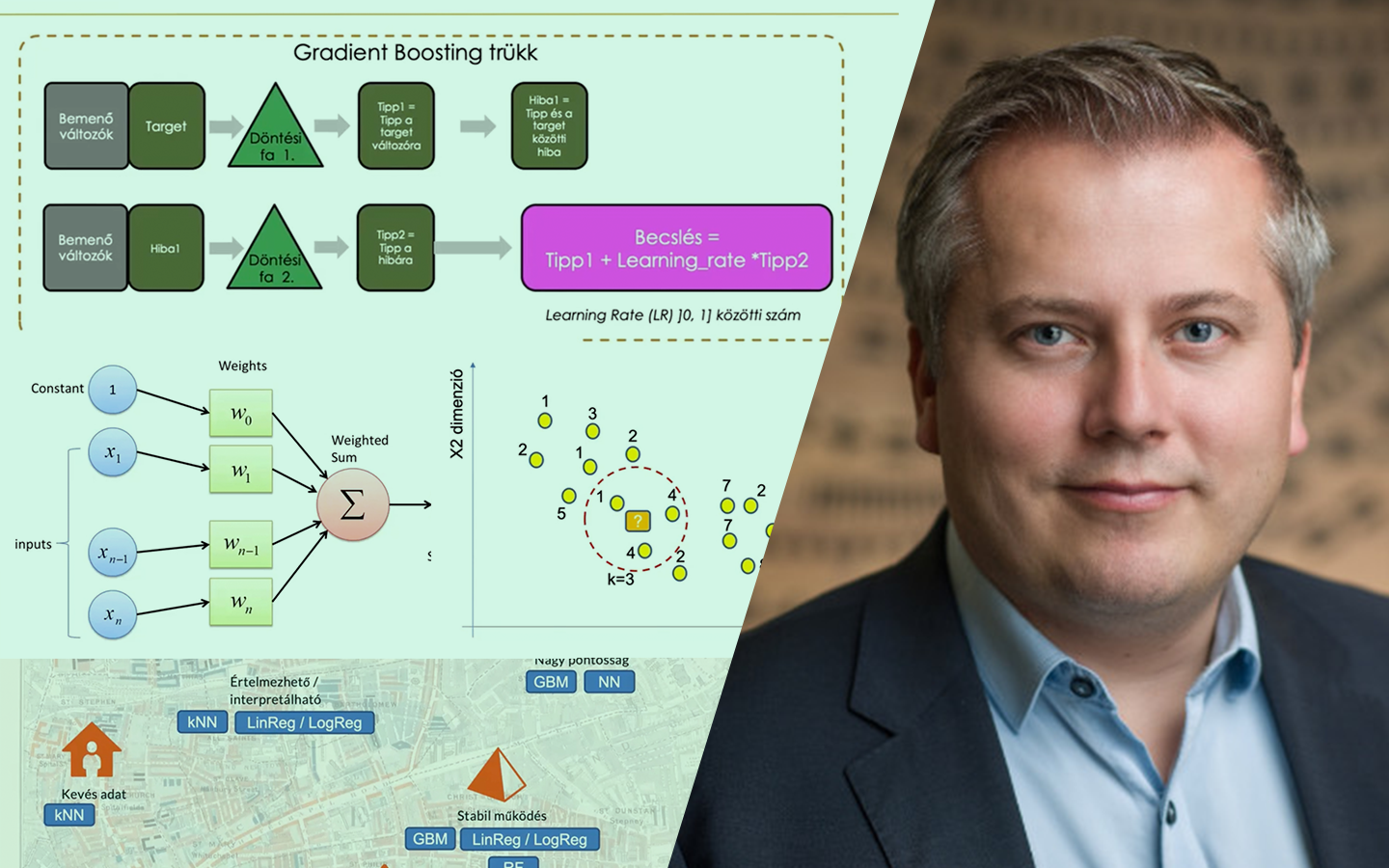
- Döntési fa működése: hogyan „darabolja” az adatot: homogénebb csoportok keresése egyszerű szabályokkal; a vágások minősítése Gini vagy entrópia alapján, konkrét számolási példával.
- Előnyök és buktatók a gyakorlatban: interpretálhatóság és kevés előkészítés előnyei, szemben a túltanulás és a magas variancia kockázatával; mikor hasznosabb mintázatfeltárásra, mint predikcióra.
- Ensemble megközelítések: bagging vs. boosting: Random Forest (párhuzamos fák, sor- és oszlop-mintavételezés, átlagolt score) összevetése GBM/LightGBM megoldásokkal (egymásra épülő fák, hibajavítás).
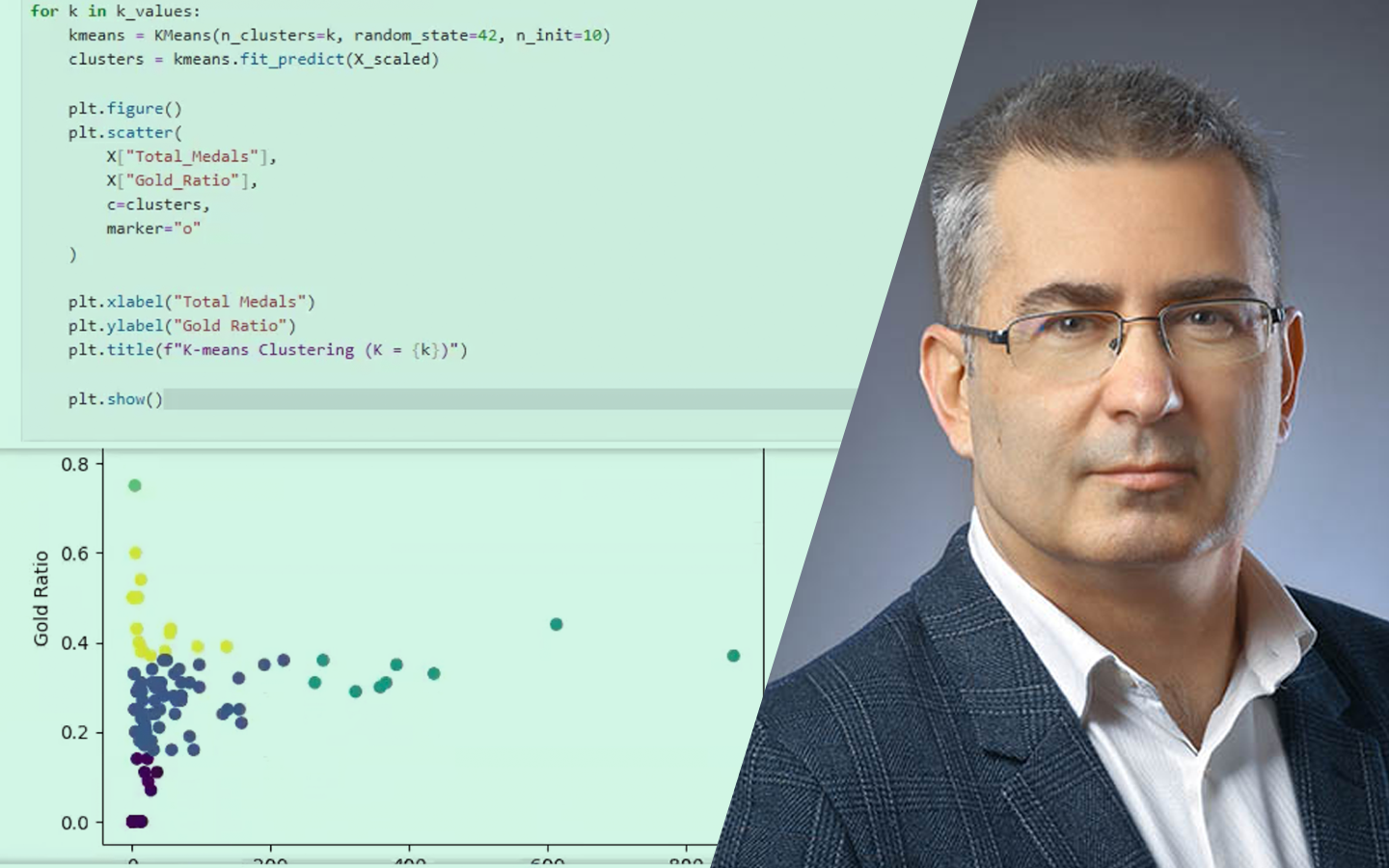
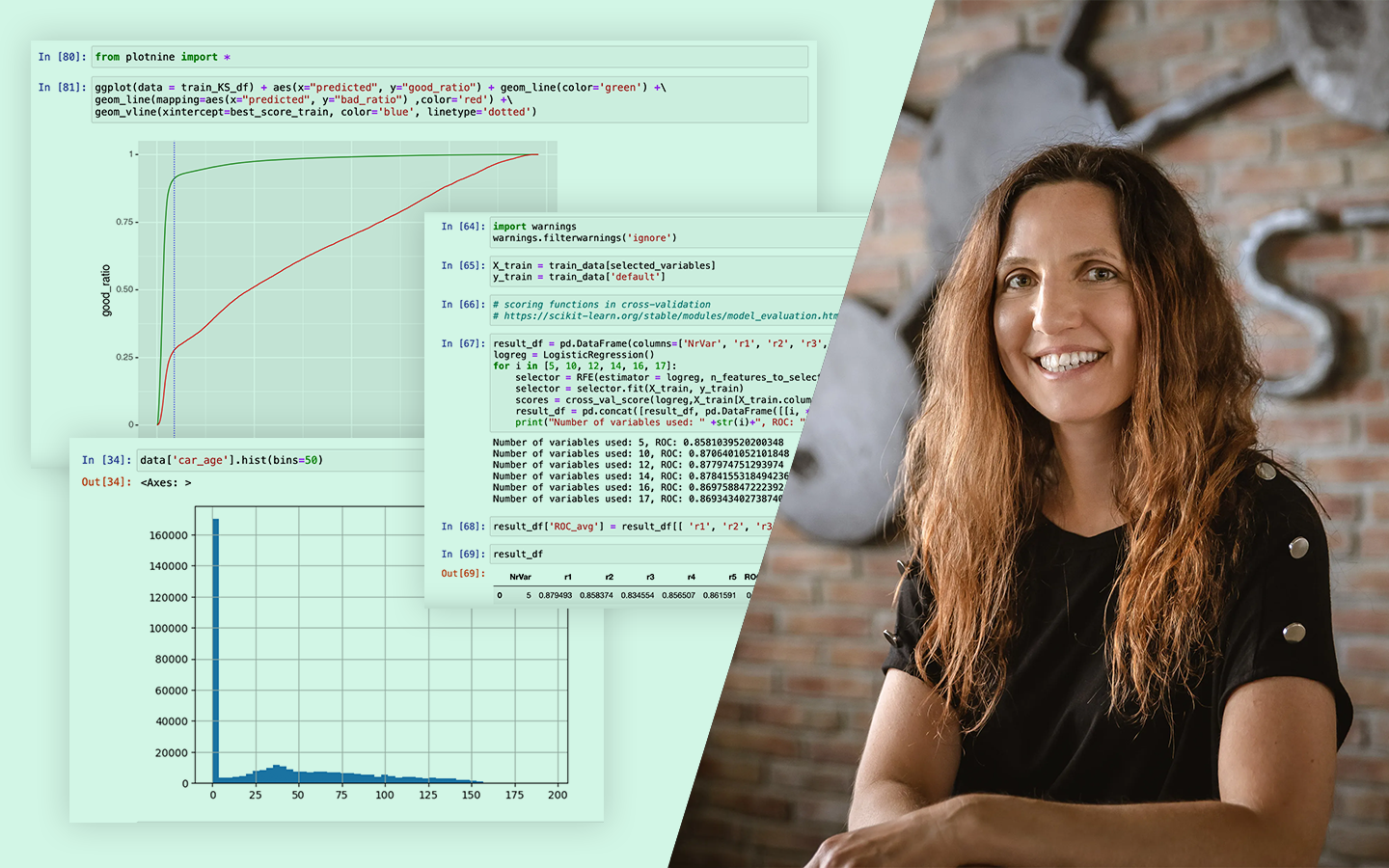
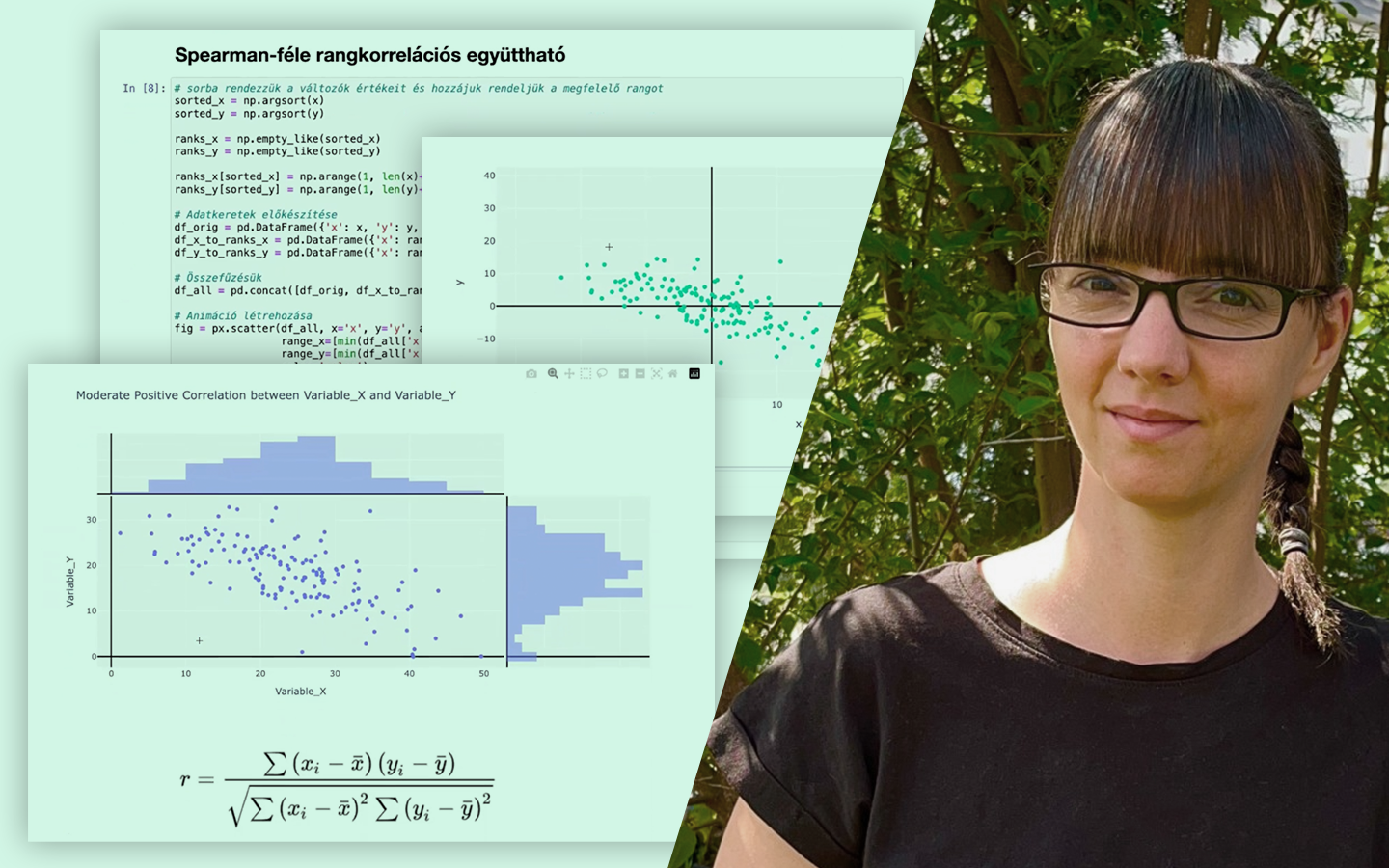
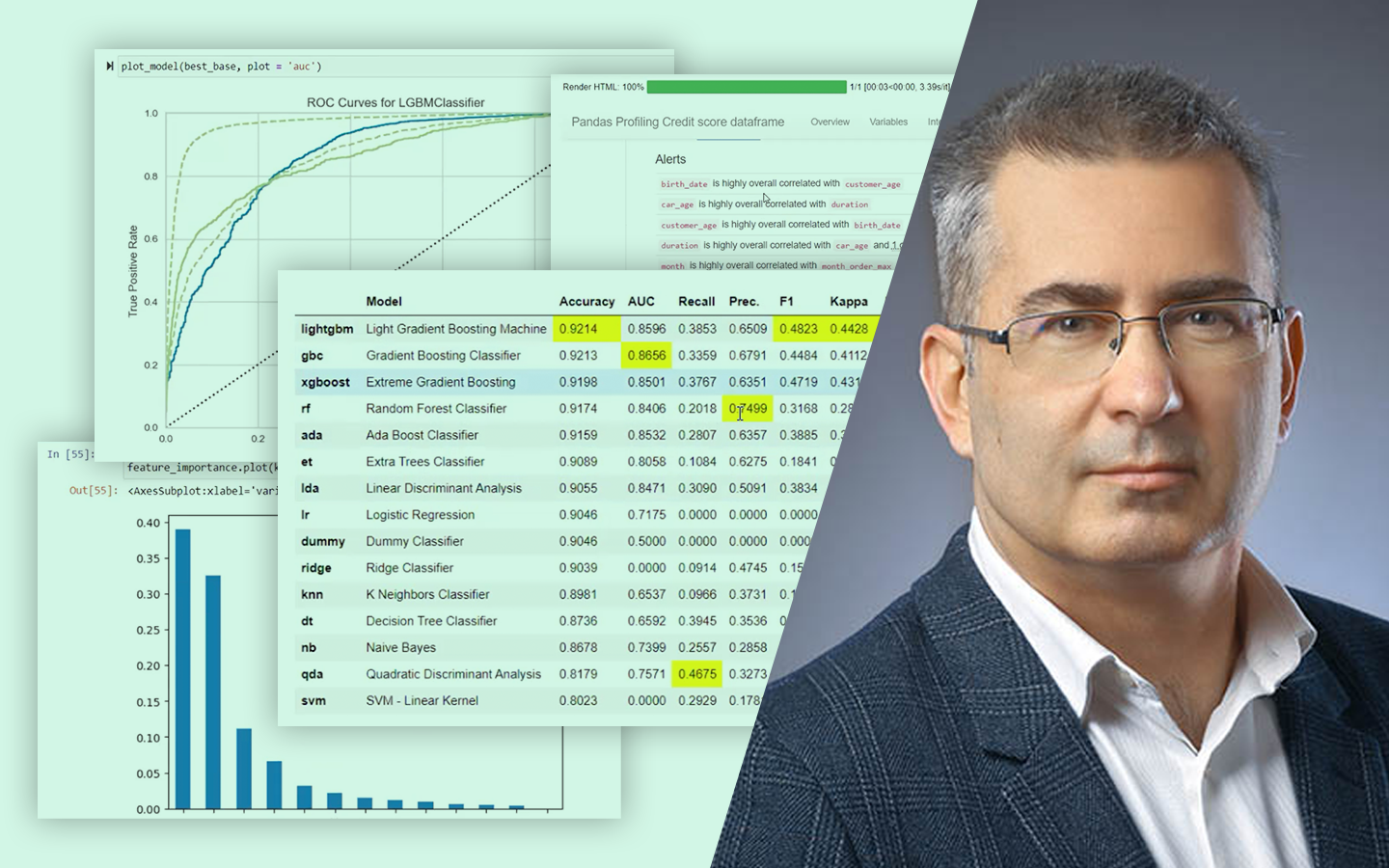
- Kód és kiértékelés: mit mérj, és miért: train–test felosztás, AUC alapú összehasonlítás, overfitting felismerése; scikit-learn döntési fa és Random Forest, valamint LightGBM (kategóriák kezelése, paraméterezési trade-offok).