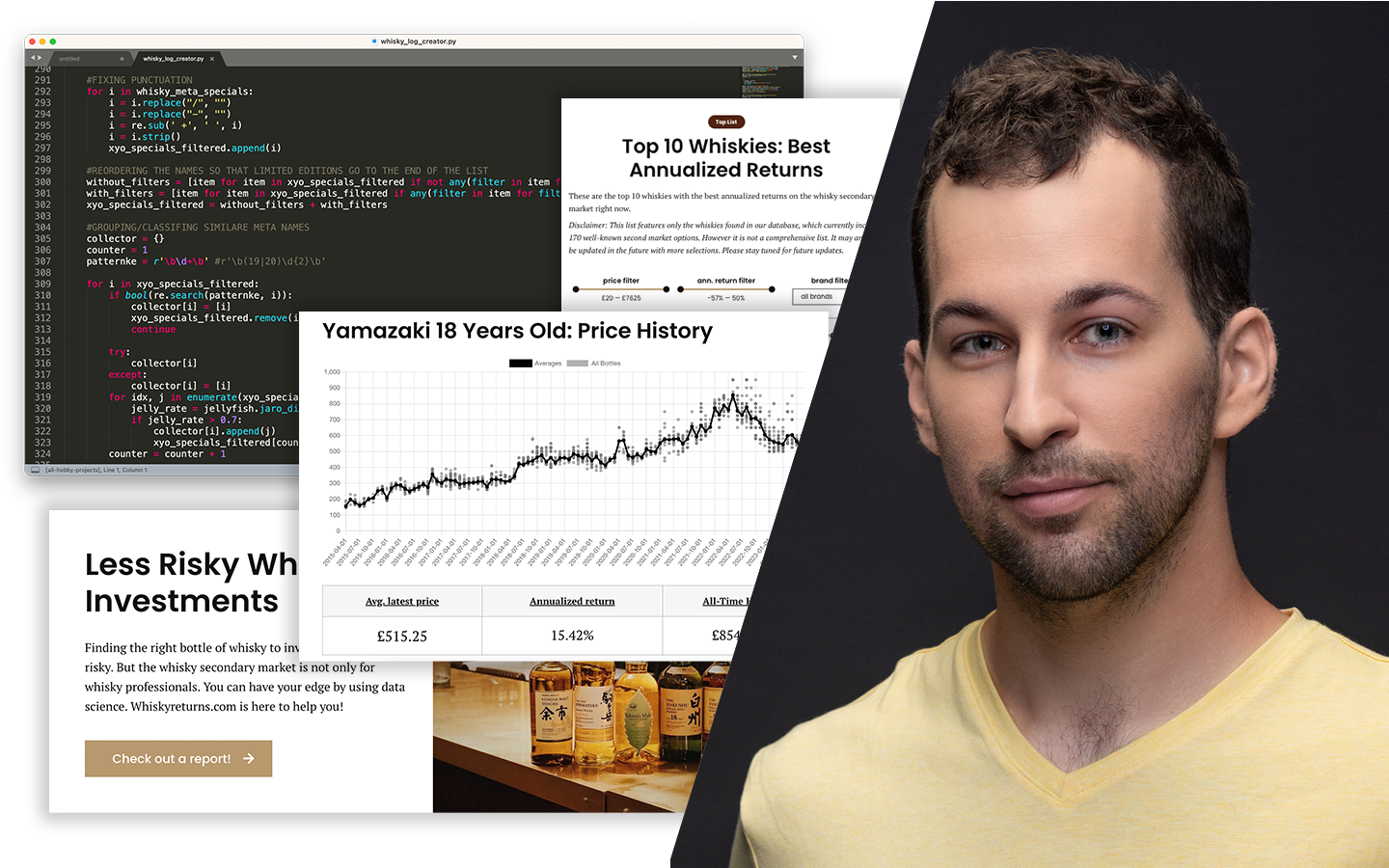
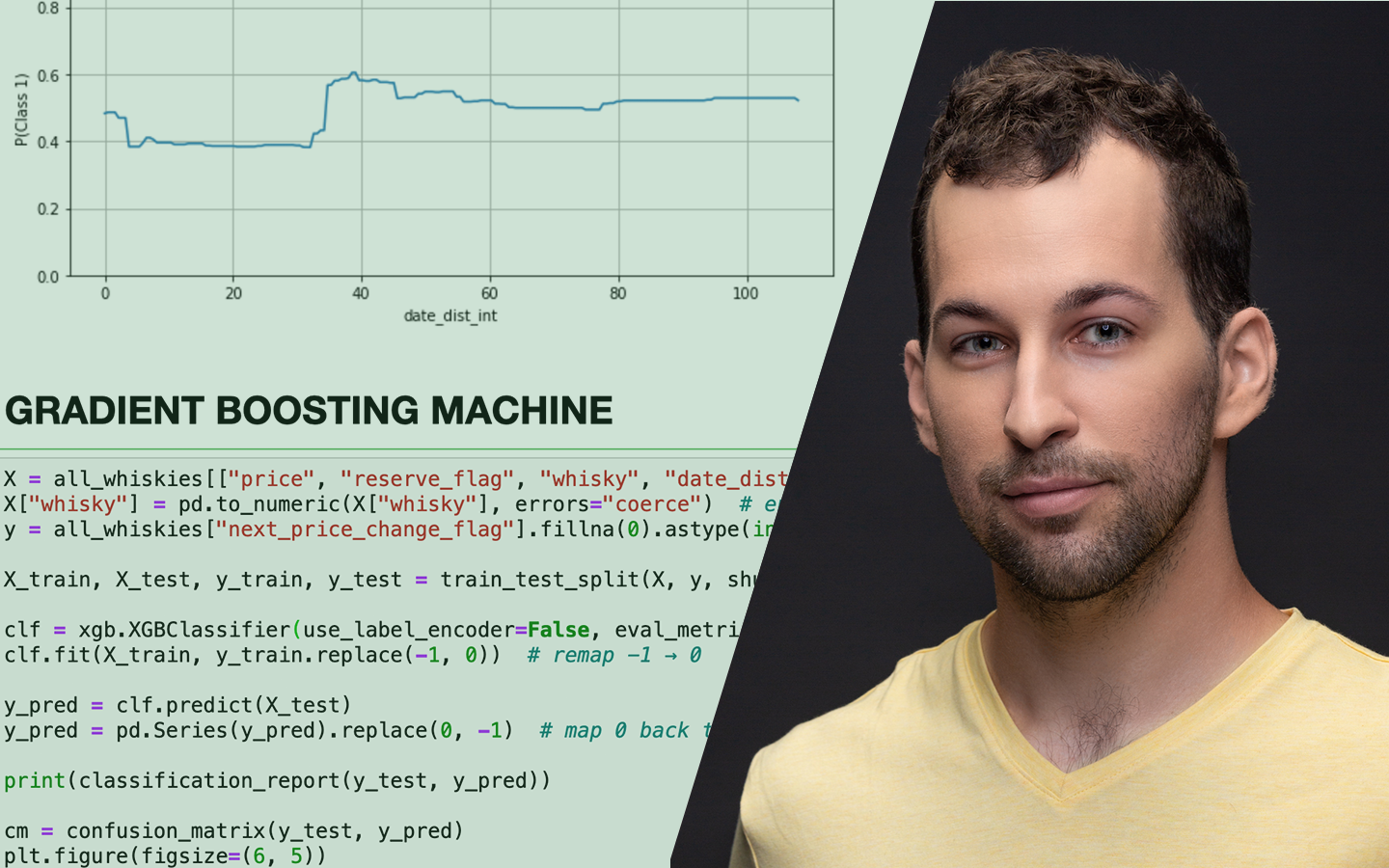
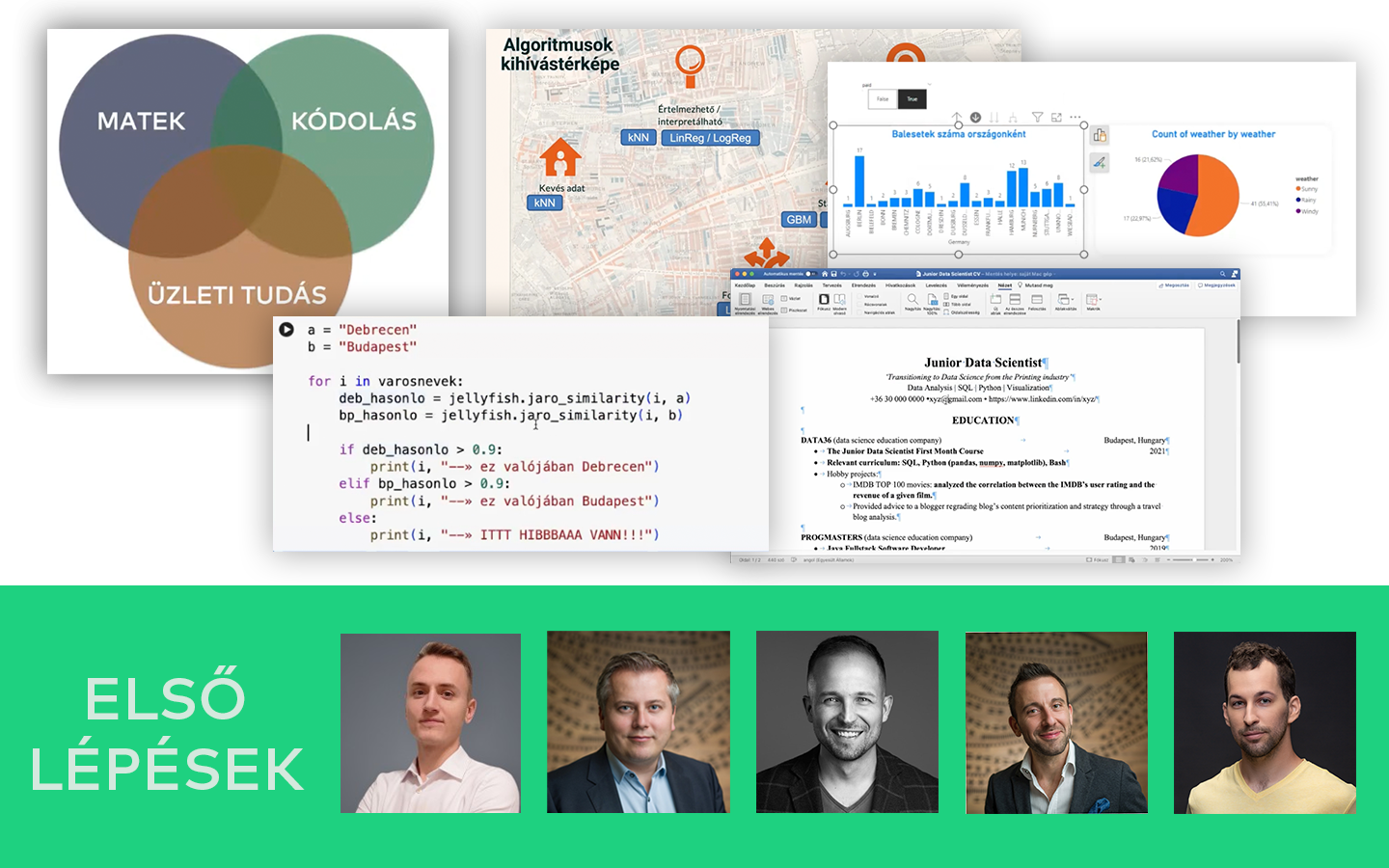
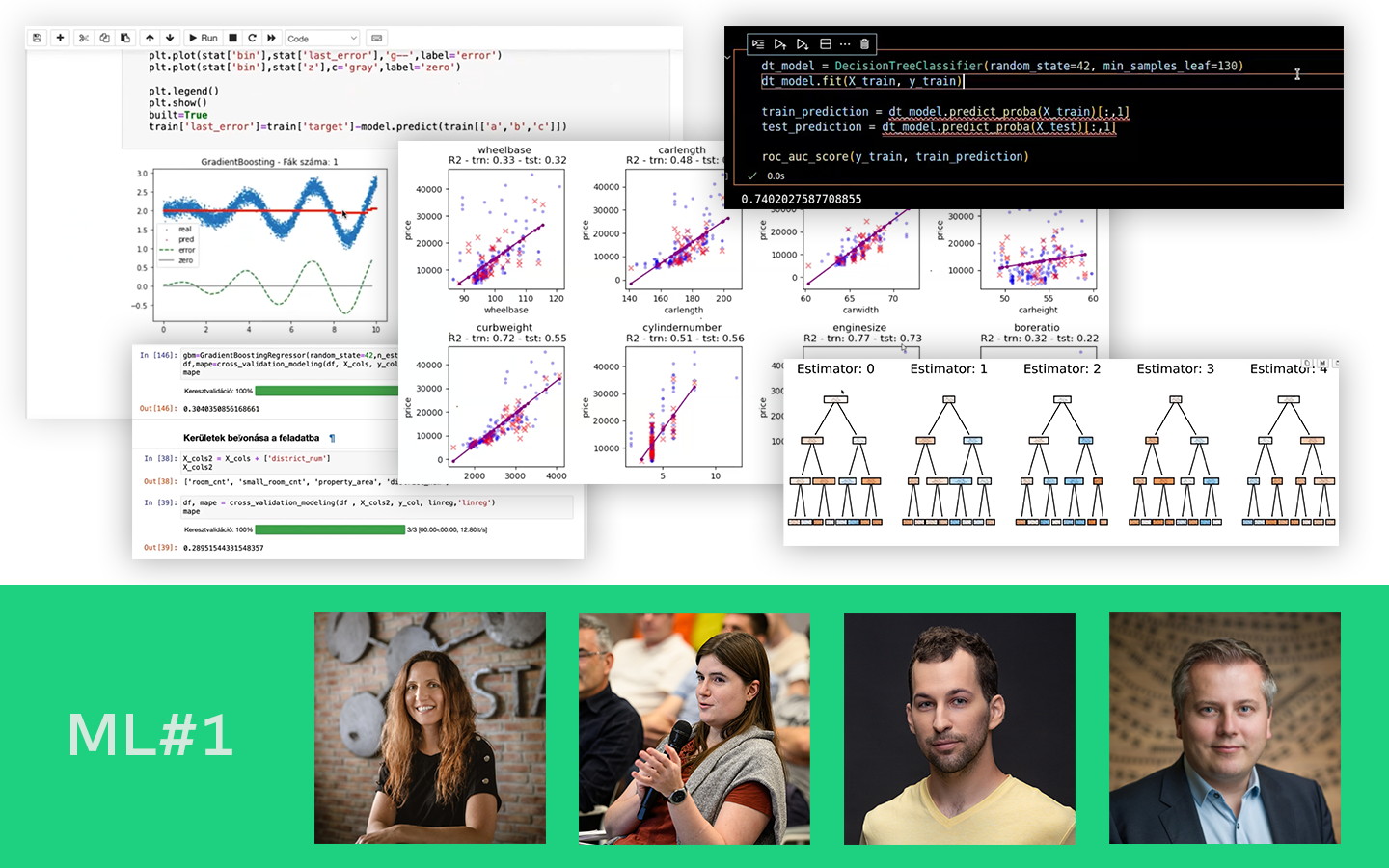
A „Statisztika Közérthetően, 1. Rész: Nevezetes Eloszlások” előadás abban segít, hogy a statisztikára a data science egyik legpraktikusabb eszköztáraként gondolj, ne pedig ijesztő akadályként. Szabó Dóra, PhD (Senior Data Scientist, Shapr3D) üzleti példákon és könnyen követhető analógiákon keresztül mutatja meg, hol csúsznak félre már a mérésnél a projektek, és hogyan lehet ezt közérthetően helyretenni. Megtanulod értelmezni az eloszlásokat, a konfidencia intervallumot, a hibákat, valamint az átlag–medián különbséget, és konkrét fogódzókat kapsz A/B tesztekhez, outlierekhez és stakeholder-kommunikációhoz, hogy gyorsabban juss megbízható következtetésekhez.
Milyen főbb témákról van szó az előadásban?
- Méréselmélet a gyakorlatban: mit mérünk valójában, hogyan reprezentálja a mérés a valóságot, és miért itt dől el sok projekt sorsa.
- Adatgyűjtés vs. meglévő adatok: milyen kockázatokkal jár, ha „készen kapod” az adatot (alkalmas-e a kérdésre), és miben más, ha neked kell megtervezni (idő, költség, minőség, mennyiség).
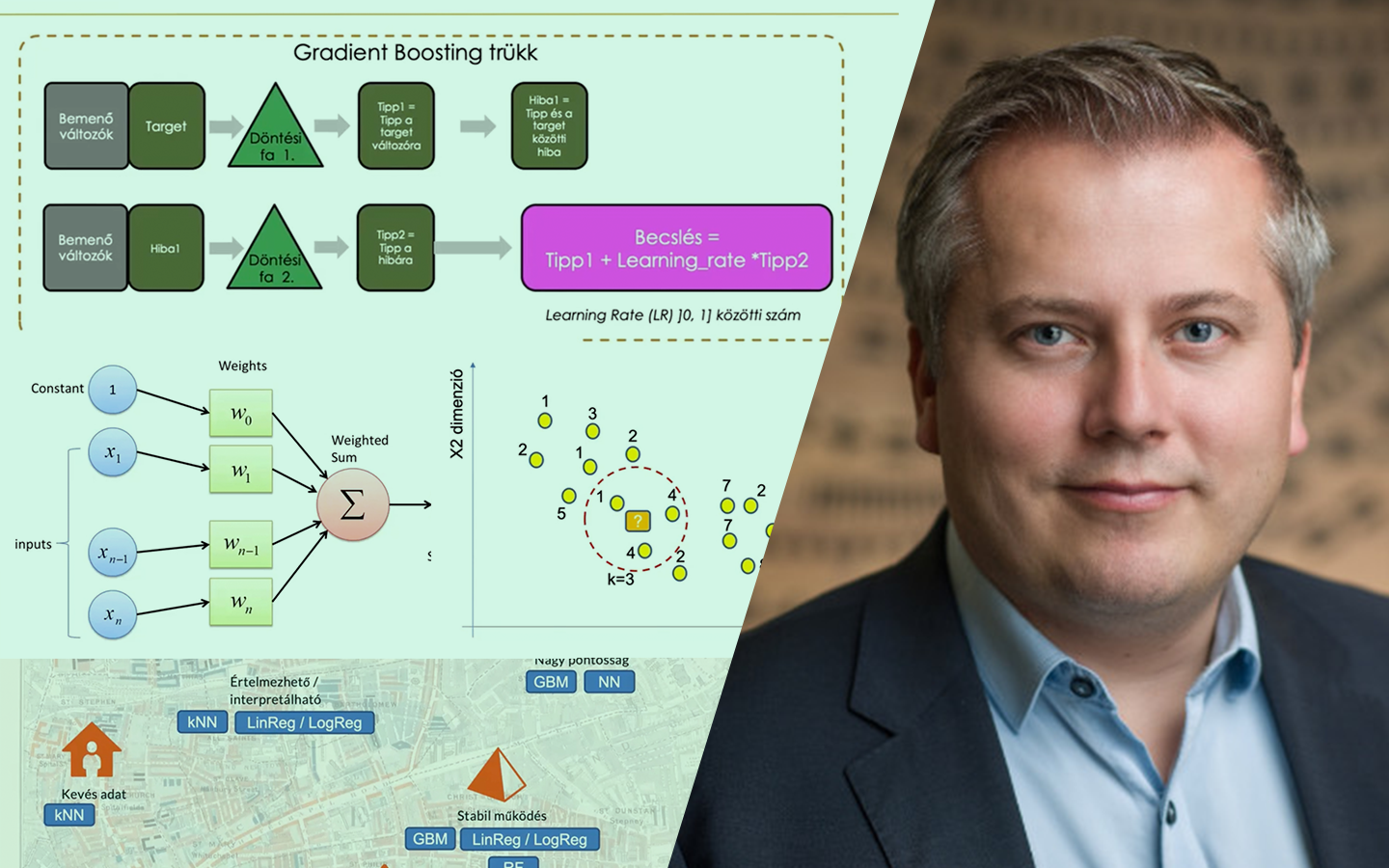
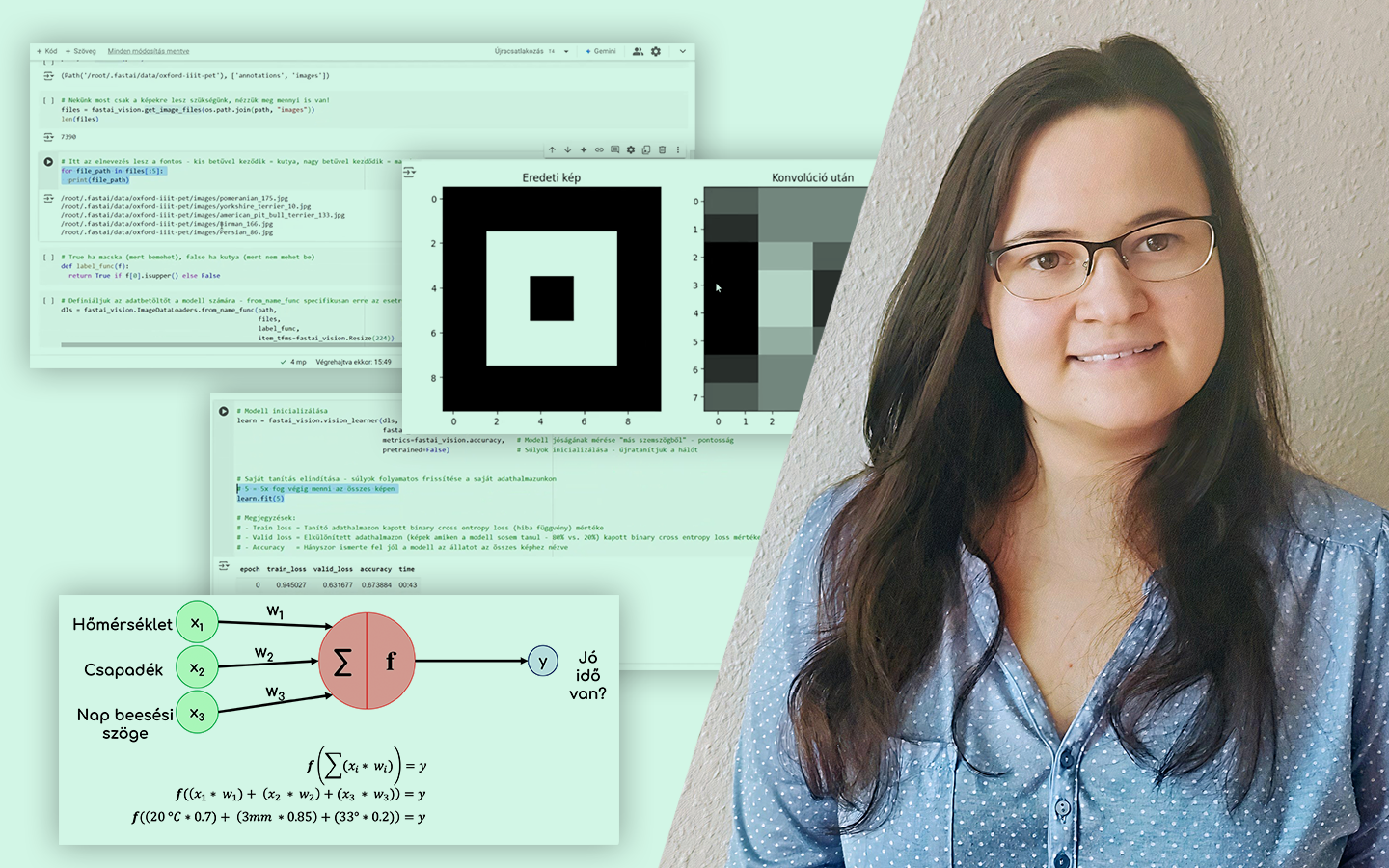
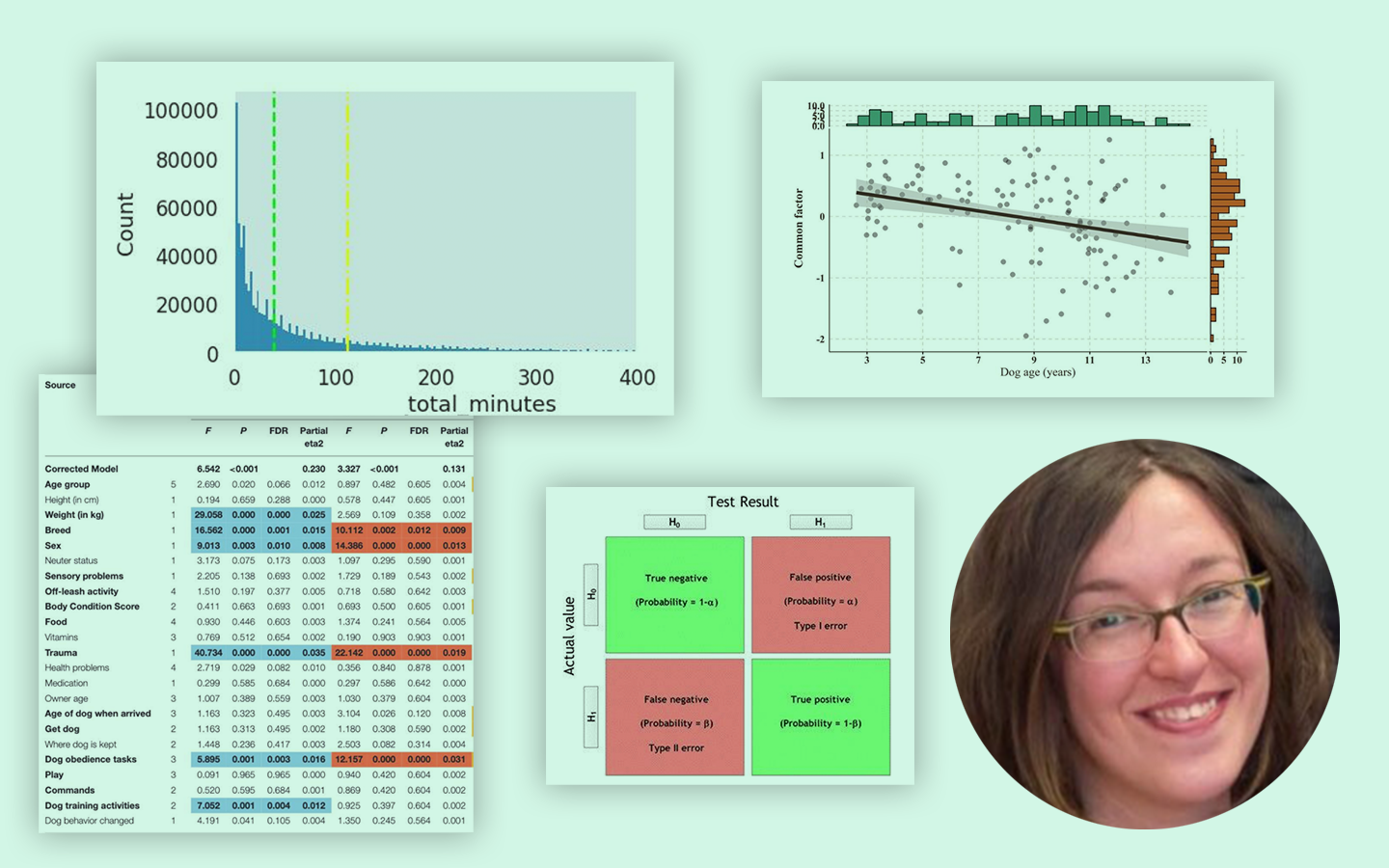
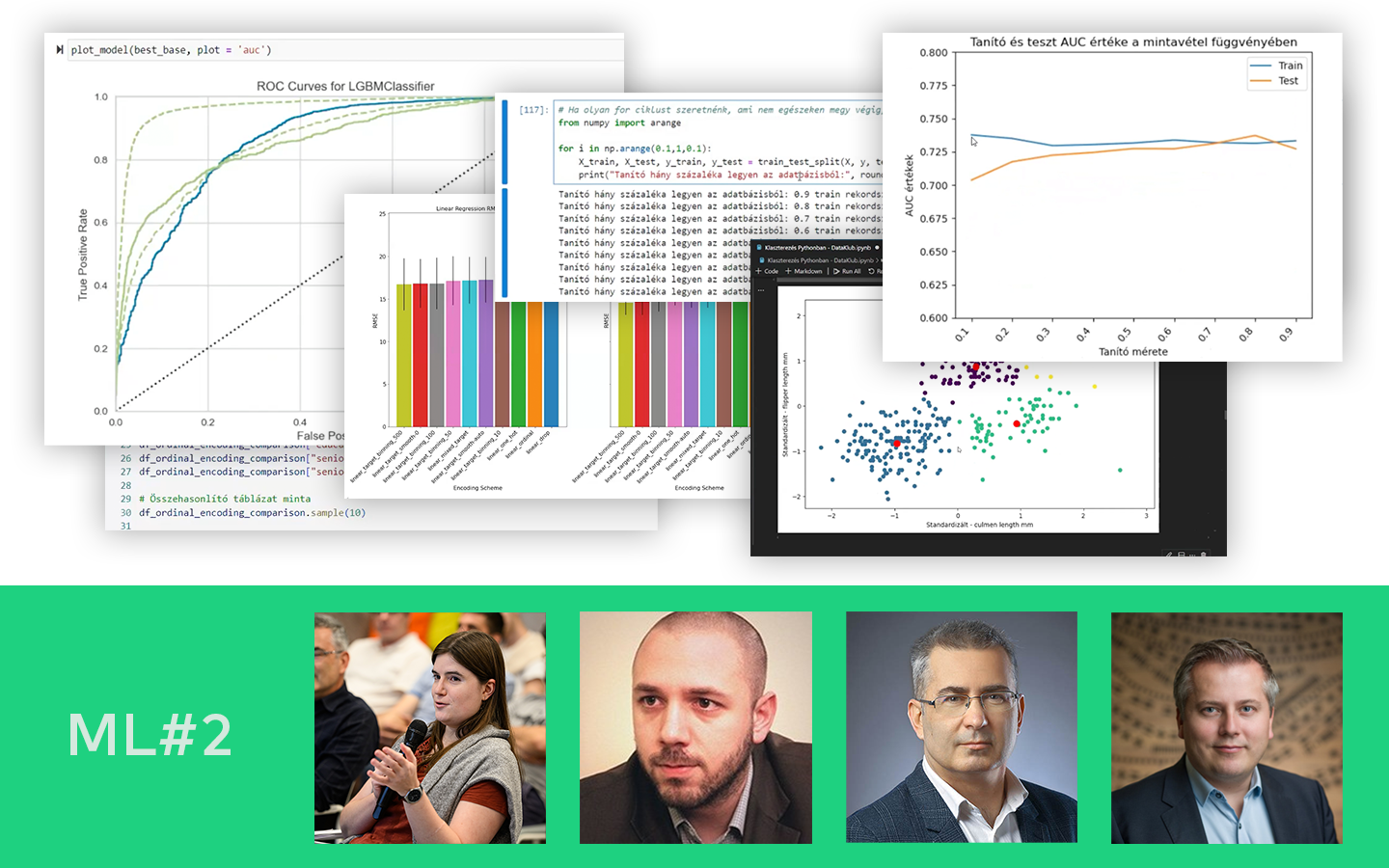
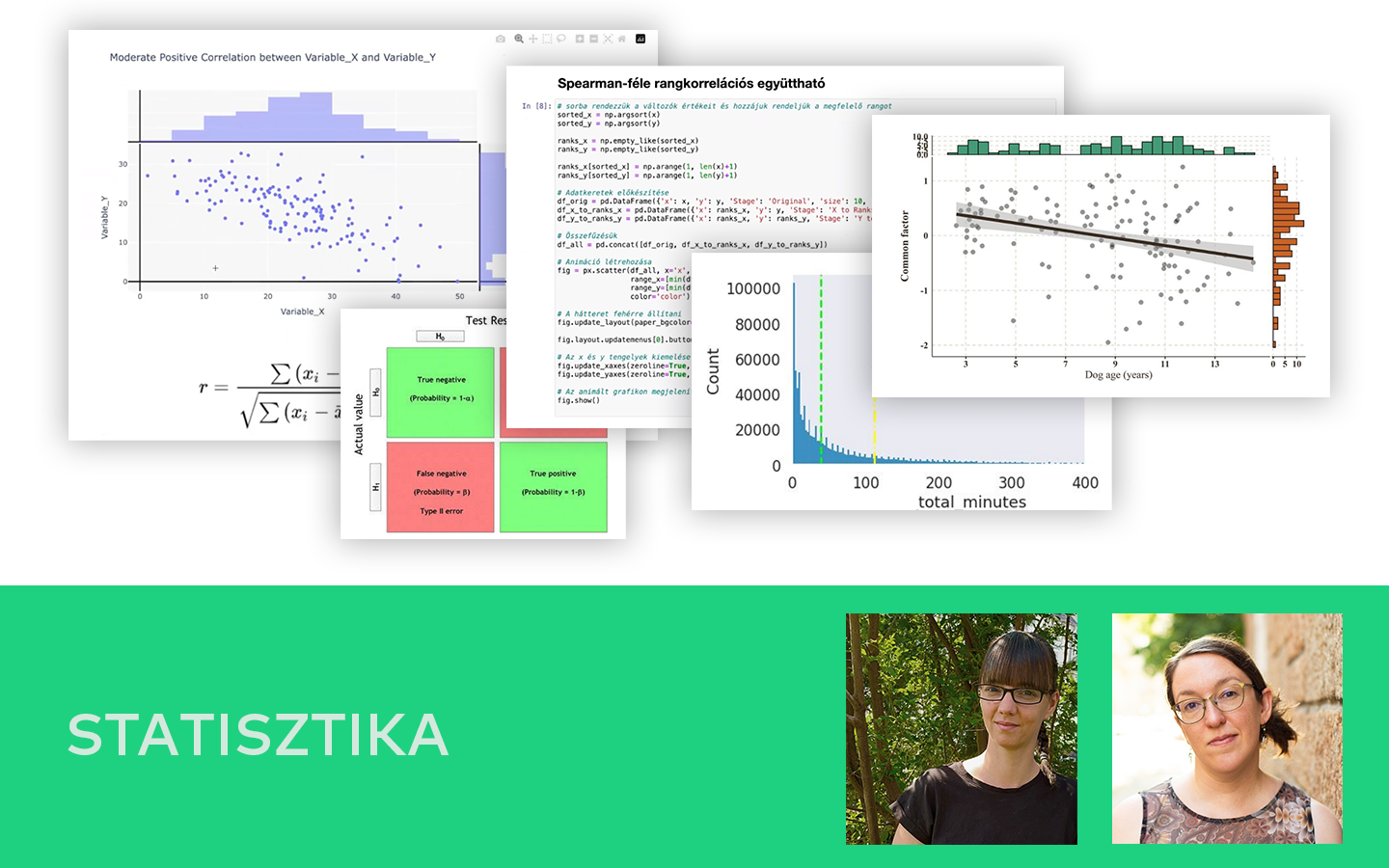
- Mérési hibák és modellezési hibák összekötése: pontosság és szisztematikus hiba, prediction error, valamint a confusion matrix logikája (Type I/Type II hiba).
- Mintavétel, torzítások, outlierek: miért nem mindegy, hogyan gyűjtesz mintát, mitől lesz „furcsa” egy adatpont, és mikor hiba automatikusan kidobni.
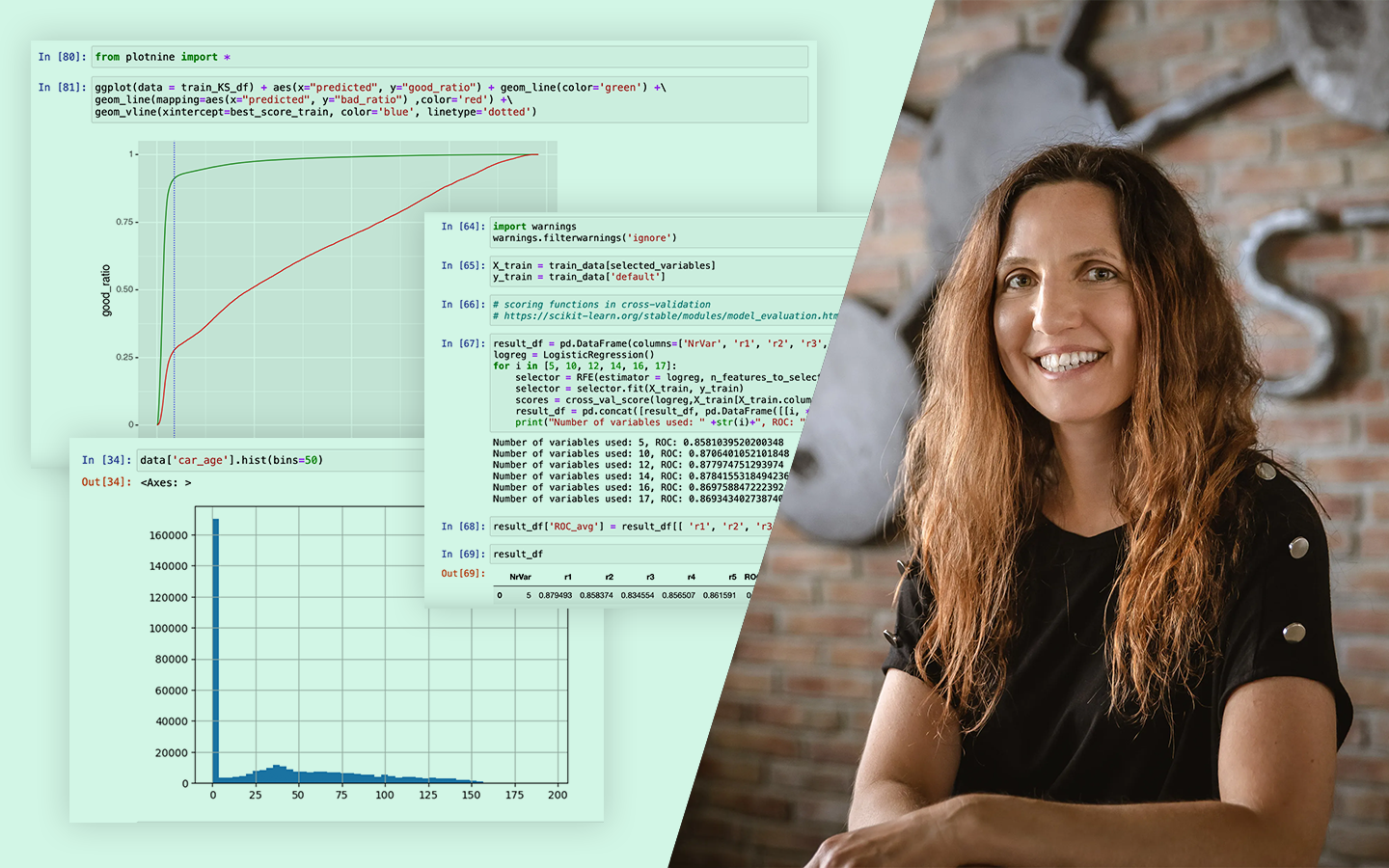
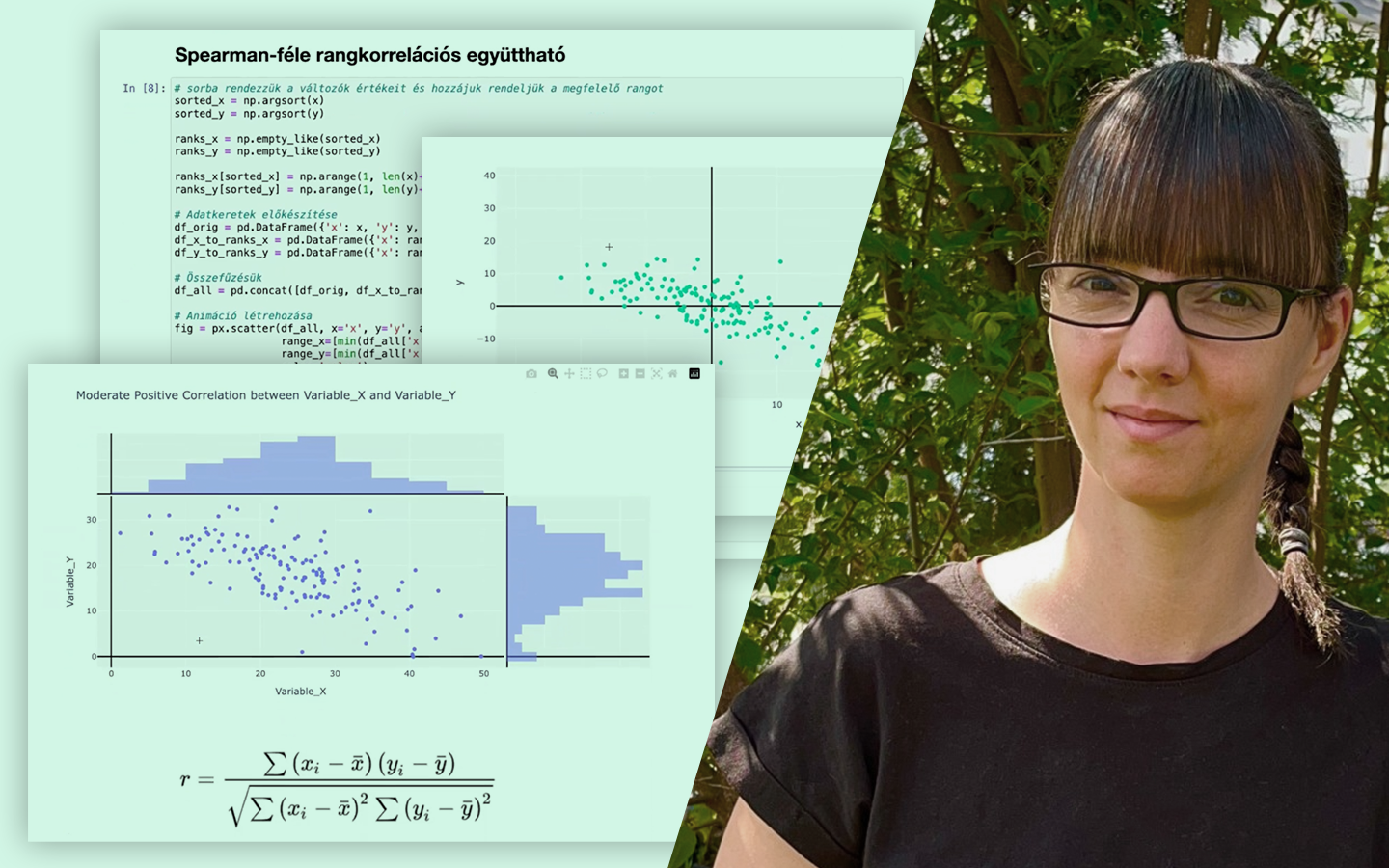
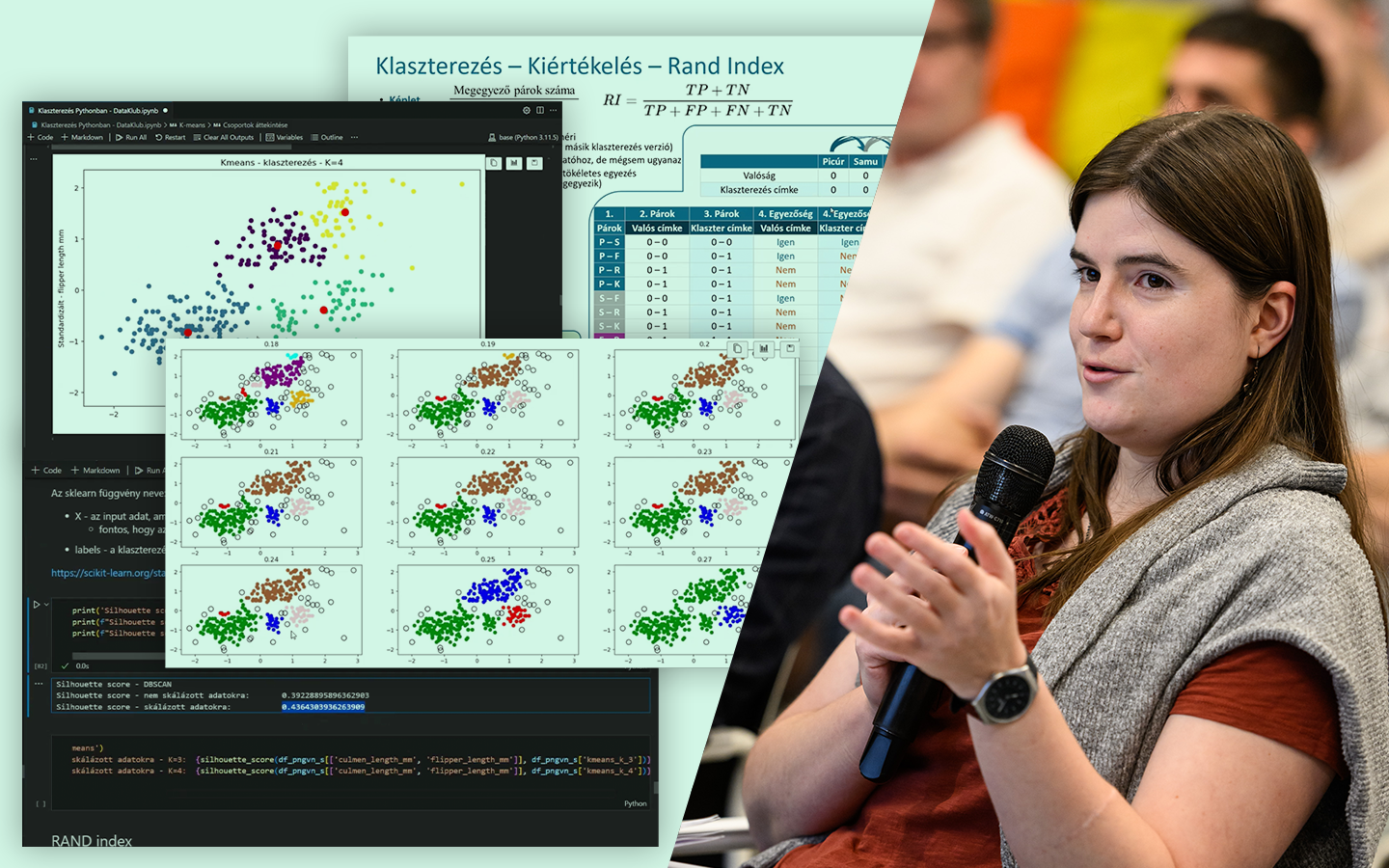
- Eloszlások értelmezése vizuálisan: hisztogram, PDF/CDF, kétcsúcsú eloszlások, és miért érdemes „ránézni a grafikonokra” minden elemzés elején.
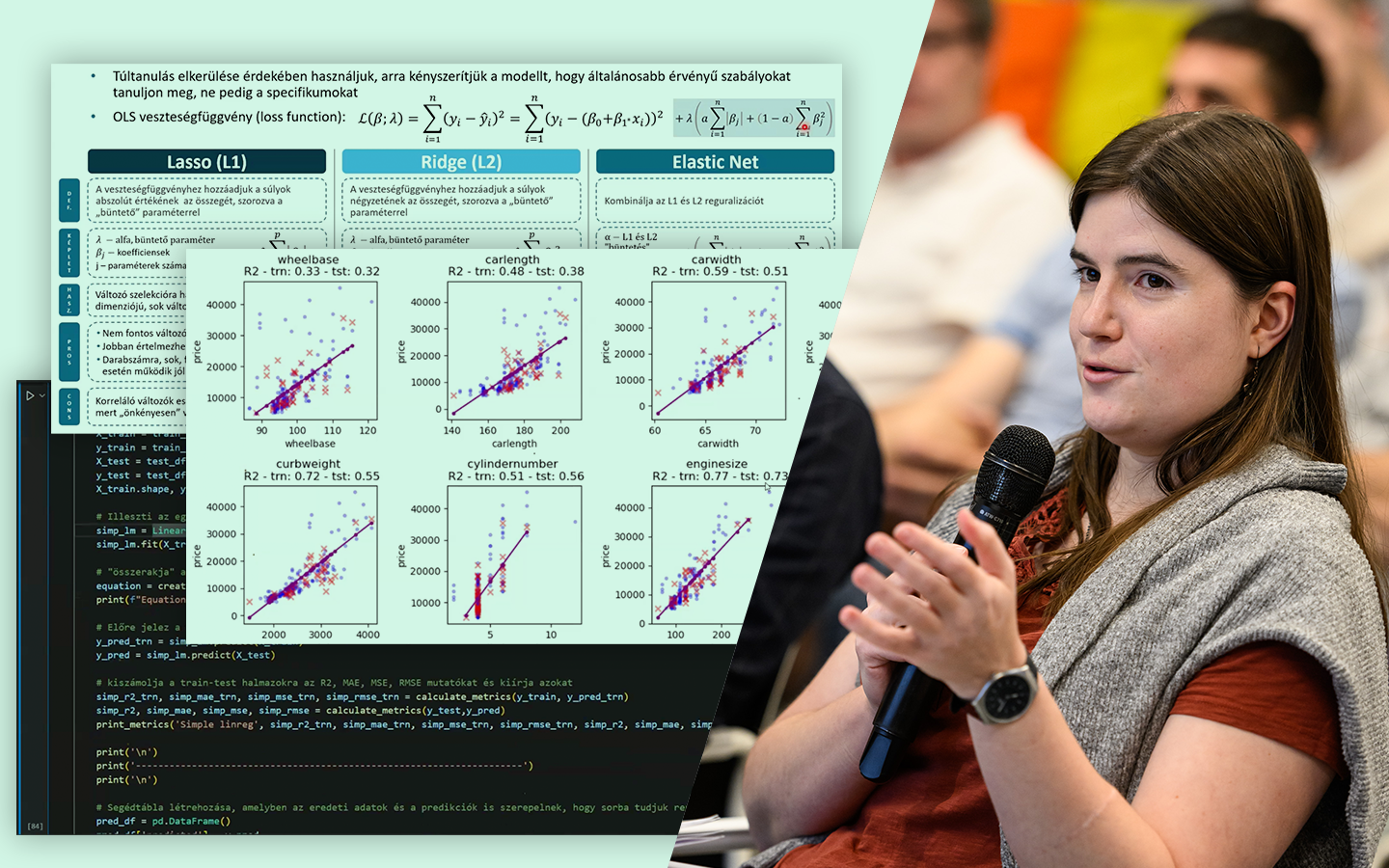
- Átlag vs. medián vs. percentilisek: long tail helyzetekben hogyan tud félrevinni az átlag, és mit érdemes helyette kommunikálni.
- Konfidencia intervallum, p-érték, effektusméret: mit jelentenek döntési helyzetben (például A/B tesztekben), és miért nem elég csak a szignifikanciát nézni.
- Eredmények üzleti kommunikációja: hogyan lesz a bonyolult elemzésből 1–2 érthető, használható megállapítás, és hogyan kezeld a bizonytalanságot.