Ha szeretnéd megérteni, hogyan lehet a nagy nyelvi modelleket (LLM) valóban a saját dokumentumaidra, adataidra és üzleti tudásodra építve használni, ez az előadás világos és gyakorlatias képet ad a RAG működéséről. A Saját Tudásbázis + LLM: RAG Lépésről Lépésre nemcsak az alapfogalmakat tisztázza, hanem végigvezet azon is, hogyan áll össze egy működő rendszer a dokumentumfeldolgozástól a keresésen át a válaszgenerálásig. Megmutatja, hogyan köthetsz össze egy LLM-et a saját adataiddal úgy, hogy a válasz ne csak „hihető”, hanem tényleg releváns legyen. A végére pontosabban látod, mely technikai döntések befolyásolják a válaszok minőségét, és milyen szempontok alapján érdemes saját megoldást tervezni vagy meglévőt értékelni.
Milyen főbb témákról van szó az előadásban?
- Miért kell egyáltalán RAG? Az LLM-ek erősségei (transformer, attention, skálázhatóság) mellett a valós korlátok: hallucináció, tudás cutoff, és a céges/saját adatokhoz való nehéz kapcsolódás.
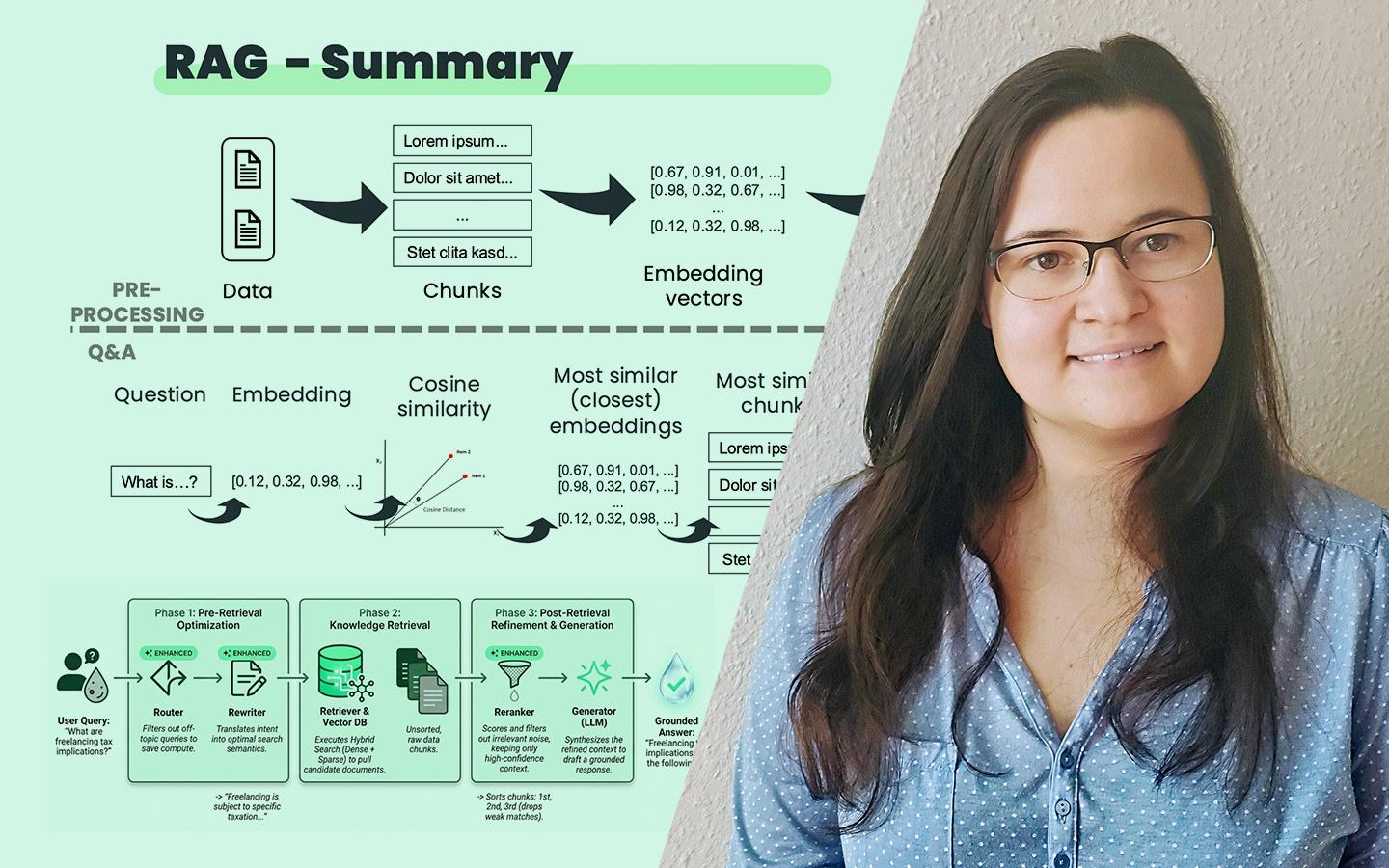
- A RAG két komponense: retrieval + augmented generation Hogyan épül fel a teljes folyamat a dokumentumfeldolgozástól a válaszgenerálásig, és mi történik „a fekete dobozban”.
- Retrieval alapok: milyen adatbázisokra építhető? Nem csak vektoradatbázis: szó esik SQL, NoSQL, vektor- és gráfadatbázisokról, sőt képekről is – a kulcs, hogy az információ kereshető legyen.
- Nem strukturált adatok bekötése: chunking → embedding → indexing Miért kritikus a chunkolás (méret, vágási pontok, átfedés, referenciák, táblák/képek), és hogyan lesz a szövegből kereshető reprezentáció.
- Keresés és relevancia Szemantikus hasonlóság, top‑N és küszöbök: hogyan lesz a kérdésből vektor, mit jelent a hasonlóság (például koszinusz), és miért kerülhetnek be irreleváns találatok.
- Modellek és tradeoffok Kontextusablak, reasoning igény, sebesség és költség; valamint a closed vs open source döntési szempontok.